slicesample
スライス サンプラー
構文
説明
例
slicesample を使用して、一変量密度関数から無作為標本を生成します。
正規確率密度関数の関数ハンドルを作成します。
rng default % For reproducibility mean = 4; sigma = 2; % Standard deviation pdf = @(x) normpdf(x,mean,sigma);
バーンイン期間なしで pdf から 1000 個の標本を生成します。初期値には 4 を使用します。
initial = 4;
nsamples = 1000;
sampleValues = slicesample(initial,nsamples,"pdf",pdf);標本値の連鎖をプロットします。
plot(sampleValues,":*") grid on xlabel("Sample Number");
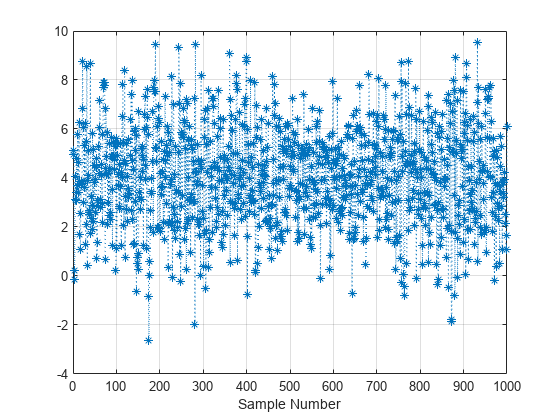
標本値の正規化ヒストグラムをプロットします。ヒストグラムに正規確率密度関数を重ね合わせます。
h = histogram(sampleValues,25,"Normalization","pdf"); hold on xgrid = linspace(h.BinLimits(1),h.BinLimits(2),200); plot(xgrid,normpdf(xgrid,mean,sigma),"r","LineWidth",2) hold off
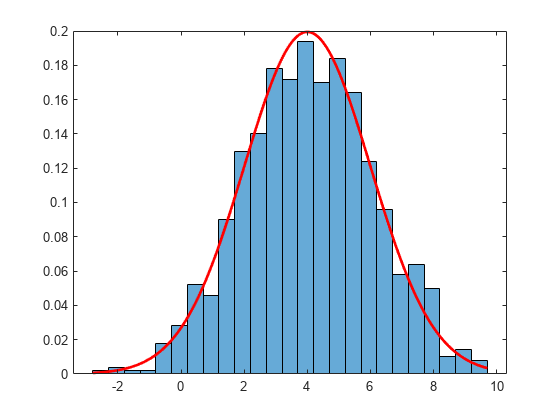
ヒストグラムから、normpdf から生成される無作為標本は、平均が 4 で標準偏差が 2 に等しい正規分布にほぼ従うことがわかります。
slicesample を使用して、対数の形式の密度関数から無作為標本を生成します。
平均が 0 で標準偏差が 1 に等しいロジスティック確率密度分布関数の関数ハンドルを作成します。
pdf = @(x) exp(x)./(1+exp(x)).^2;
対数ロジスティック分布関数の関数ハンドルを作成します。
logpdf = @(x) x-2*log(1+exp(x));
バーンイン期間なしで logpdf から 1000 個の標本を生成します。初期値には 0 を使用します。
rng default % For reproducibility initial = 0; nsamples = 1000; sampleValues = slicesample(initial,nsamples,"logpdf",logpdf);
標本値の連鎖をプロットします。
plot(sampleValues,":*") grid on xlabel("Sample Number");
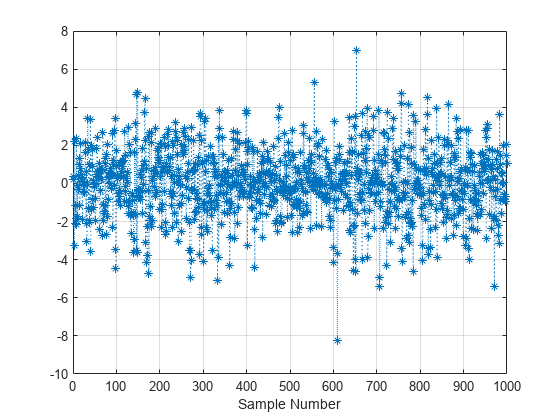
標本値の正規化ヒストグラムをプロットします。ヒストグラムにロジスティック分布関数を重ね合わせます。
h = histogram(sampleValues,"Normalization","pdf"); hold on xgrid = linspace(h.BinLimits(1),h.BinLimits(2),200); plot(xgrid,pdf(xgrid),"r","LineWidth",2) hold off
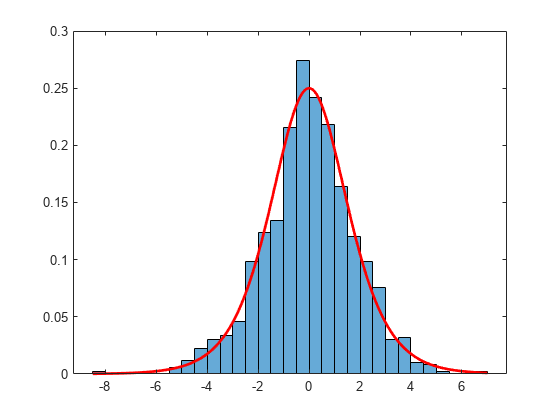
ヒストグラムから、logpdf から生成される無作為標本はロジスティック分布にほぼ従うことがわかります。
slicesample を使用して、マルチモーダル密度関数から無作為標本を生成します。
マルチモーダル密度に比例する関数を定義します。この関数は積分して 1 になる必要はありません。
rng default % For reproducibility pdf = @(x) exp(-x.^2/2).*(1 + (sin(3*x)).^2).* ... (1 + (cos(5*x).^2));
初期値を 1 にして pdf から無作為標本を生成します。最初の 1000 個の標本を破棄し、その後は 5 つごとに 1 つの標本を保持します。出力列の標本数は 2000 です。
N = 2000; sampleValues = slicesample(1,N,"pdf",pdf,"burnin",1000,"thin",5);
標本値の正規化ヒストグラムをプロットします。ヒストグラムに密度関数を重ね合わせます。
h = histogram(sampleValues,50,"Normalization","pdf"); hold on xgrid = linspace(h.BinLimits(1),h.BinLimits(2),1000); area = integral(pdf,-5,5); y = pdf(xgrid)/area; plot(xgrid,y,"r","LineWidth",2) hold off
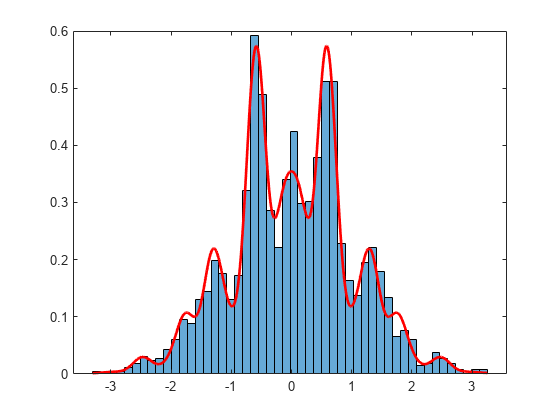
標本がマルチモーダル密度関数によく適合しており、指定した burnin の値が適切であることがわかります。
slicesample で生成される無作為標本列の定常性を調べ、標本ごとの関数評価の平均回数を返します。
マルチモーダル密度に比例する関数を定義します。
rng default % For reproducibility pdf = @(x) exp(-x.^2/2).*(1 + (sin(3*x)).^2).* ... (1 + (cos(5*x).^2));
密度関数をプロットします。
x = linspace(-4,4,500); plot(x,pdf(x),"r","LineWidth",2) xline(0);
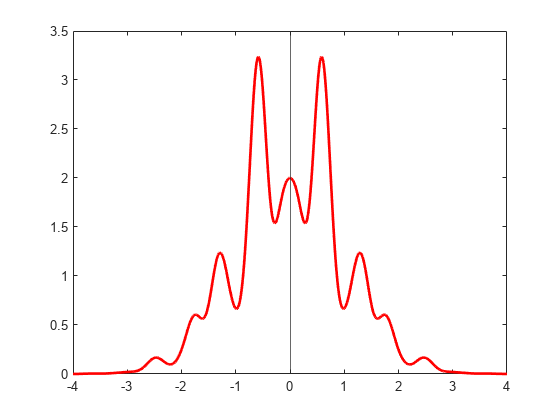
密度関数は原点に対して対称であるため、期待値は 0 です。
バーンイン期間なしで密度関数から 100 個の標本を生成します。初期値には 20、標本の幅には 15 を使用します。
nsamples = 100; initial = 20; width = 15; burnin = 0; [sampleValues,neval] = slicesample(initial,nsamples, ... "pdf",pdf,"width",width,"burnin",burnin); neval
neval = 4
関数 slicesample で、生成された標本ごとの関数評価の平均回数 neval が求められます。
標本列の値と移動平均の値をプロットします。移動平均ウィンドウの幅には 10 標本を使用します。
plot(sampleValues,":*") yline(0); xlabel("Sample Number"); movavg = movmean(sampleValues,10); hold on plot(movavg,"LineWidth",2) hold off
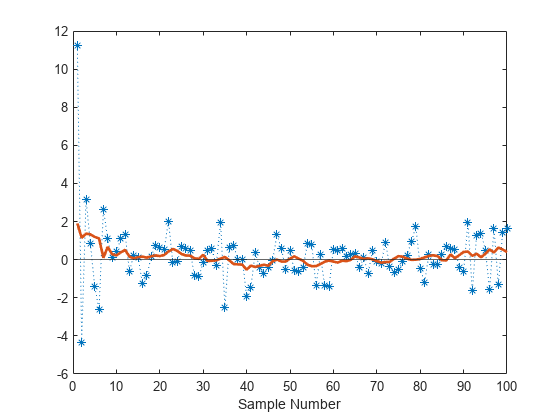
約 7 標本後に列の平均値が定常性に近づき、密度関数の期待値 (0) に近い値になっています。initial と burnin に別の値を指定することで、さらに速く定常性を実現できます。
入力引数
名前と値の引数
出力引数
ヒント
数値的なオーバーフローやアンダーフローのエラーが発生する可能性がある密度関数には、
pdfの代わりにlogpdfを使用します。thinとburninの適切な値を判断するための明確なガイドラインはありません。thinとburninの開始値を指定した後、標本の独立性と類似性がターゲットの密度関数に応じた必要な状態になるまで、必要に応じてそれらを増やしていきます。標本の生成時に関数評価の回数が最大数の 200 を超えてステップアウト手順 (アルゴリズムを参照) が失敗する場合は、必要に応じて
widthを別の値にして試してみます。widthが小さすぎると、スライスの範囲を特定するためにアルゴリズムで過剰な数の関数評価が実装される可能性があります。widthが大きすぎると、幅を適切なサイズに縮小するようにアルゴリズムで試行され、結果として関数評価の数が多くなることがあります。標本ごとの関数評価の平均回数は出力引数nevalで返されます。
アルゴリズム
スライス サンプリングは、比例定数までしかわかっていないときに、任意の密度関数を使用して分布から標本を抽出するマルコフ連鎖モンテカルロ (MCMC) アルゴリズムです。このような状況としては、正規化定数が未知である複雑なベイズ事後分布からサンプリングしなければならない場合などがあります。このアルゴリズムでは、独立した標本は生成されず、定常分布が対象の分布であるマルコフ連鎖が生成されます。
関数 slicesample は、垂直方向と水平方向のステップの列を使って、密度関数の下の領域から標本を抽出します。はじめに、0 から指定された初期値 x の密度関数 f(x) の値までの間で、無作為に高さを選択します。次に、選択された高さよりも密度関数が大きくなるすべての x の値を含む水平方向の "スライス" からサンプリングすることによって、新しい x の値を無作為に選択します。関数 slicesample は、多変量分布の場合にも同様のスライス サンプリング アルゴリズムを使用します。
ターゲットの密度関数に比例する密度関数 f(x) を選択し、以下を実行して乱数のマルコフ連鎖を生成します。
f(x) の定義域内にある初期値 x(t) を選択します。
(0, f(x(t))) から実数 y を等間隔に抽出することで、水平方向の "スライス" を S = {x: y < f(x)} として定義します。
すべてまたはほとんどの "スライス" S を含む x(t) 周辺の区間 I = (L, R) を検出します。
この区間内から新たな点 x(t + 1) を抽出します。
t を 1 ずつインクリメントし、目的とする標本数が得られるまで手順 2 から 4 を繰り返します。
slicesample では、Neal のスライス サンプリング アルゴリズム ([1]) を使用しています。数値安定性のために、slicesample は関数 pdf の対数に対して演算を行います (引数 logpdf が指定されている場合は除く)。slicesample は、スライス S を含む区間 I を見つけるために Neal の "ステップアウト" と "ステップイン" の手法を使用します。各標本の生成時にステップアウトとステップインの反復がそれぞれ最大 200 回まで試行されます。
連鎖内の近接点は、独立した値の標本からよりも互いに接近した値になる傾向があります。多くの目的で、点のセット全体を対象の分布からの標本として使用できます。ただし、この種の系列相関が問題となる場合は、名前と値の引数 burnin および thin を使用して相関を減らすことができます。
代替機能
slicesampleは、特に中次元と高次元の密度関数について、混合が遅く定常分布に収束するまで時間がかかるマルコフ連鎖を生成する可能性があります。このような場合にサンプリングを高速化するには、勾配に基づくハミルトニアン モンテカルロ (HMC) サンプラーhmcSamplerを使用します。マルコフ連鎖サンプラーを使用する標本分布の表現を参照してください。
参照
[1] Neal, Radford M. "Slice Sampling." The Annals of Statistics Vol. 31, No. 3, pp. 705–767, 2003. Available at https://doi.org/10.1214/aos/1056562461.
バージョン履歴
R2006a で導入