ロジスティック回帰モデルのベイズ解析
この例では、slicesample を使用してロジスティック回帰モデルでベイズの推論を行う方法を示します。
統計的推定は、最尤推定法 (MLE) に基づくのが一般的です。MLE はデータの尤度を最大化するパラメーターを選択するので、直観的に言えば魅力的です。MLE では、パラメーターは未知でも確定はしているものと想定されており、ある程度の信頼をもって推定されます。ベイズ解析では、未知のパラメーターについては確率を利用して数値化します。それゆえ未知のパラメーターは確率変数として定義されます。
ベイズの推論
ベイズの推論は、モデルまたはモデル パラメーターについての予備知識を取り込んで統計モデルを解析する処理です。このような推論の根底にあるのは、ベイズの定理です。
たとえば、次のような正規の観測値があるとします。
ここで、sigma は既知であり、theta の予備知識は次のとおりです。
この式で、「ハイパーパラメーター」と呼ばれることもある mu と tau も既知です。正規分布の観測値 X の n 個の標本が観測される場合、次のような theta の正規共役事後分布を得ることができます。
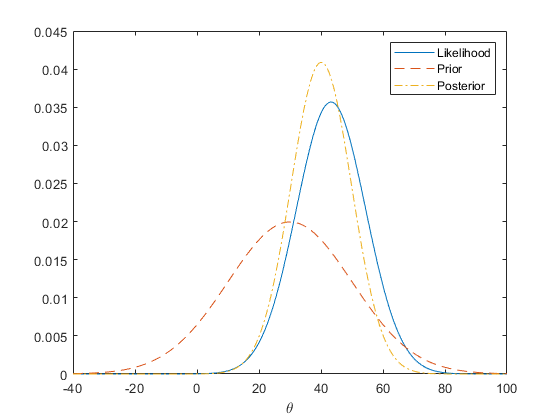
theta の事前分布、尤度分布、および事後分布を次のグラフに示します。
rng(0,'twister'); n = 20; sigma = 50; x = normrnd(10,sigma,n,1); mu = 30; tau = 20; theta = linspace(-40, 100, 500); y1 = normpdf(mean(x),theta,sigma/sqrt(n)); y2 = normpdf(theta,mu,tau); postMean = tau^2*mean(x)/(tau^2+sigma^2/n) + sigma^2*mu/n/(tau^2+sigma^2/n); postSD = sqrt(tau^2*sigma^2/n/(tau^2+sigma^2/n)); y3 = normpdf(theta, postMean,postSD); plot(theta,y1,'-', theta,y2,'--', theta,y3,'-.') legend('Likelihood','Prior','Posterior') xlabel('\theta')
自動車実験データ
前に示した正規平均推定の例などの単純な問題では、閉じた形での事後分布を理解するのは簡単です。しかし、非共役事前分布が関係する一般的な問題では、事後分布を解析的に計算するのは困難または不可能です。そこで、例としてロジスティック回帰を検討します。この例には、燃費テストで不合格になった、さまざまな重量の自動車の割合をモデル化するのに役立つ実験が含まれています。データには、重量、テストした自動車の台数、および不合格台数の観測値が含まれています。重量を変換して、回帰パラメーター推定における相関を低減させます。
% A set of car weights weight = [2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300]'; weight = (weight-2800)/1000; % recenter and rescale % The number of cars tested at each weight total = [48 42 31 34 31 21 23 23 21 16 17 21]'; % The number of cars that have poor mpg performances at each weight poor = [1 2 0 3 8 8 14 17 19 15 17 21]';
ロジスティック回帰モデル
ロジスティック回帰は、一般化線形モデルの特殊ケースであり、応答変数が 2 項なのでここで示したデータにとって適切です。ロジスティック回帰モデルを次のように記述することができます。
ここで、X は計画行列で、b はモデル パラメーターを格納したベクトルです。MATLAB® では、この式を次のように記述できます。
logitp = @(b,x) exp(b(1)+b(2).*x)./(1+exp(b(1)+b(2).*x));
予備知識または無情報事前分布がある場合には、モデル パラメーターの事前確率分布を指定することができます。たとえば、この例では、intercept パラメーター b1 と slope パラメーター b2 に正規事前分布を使用します。つまり、次のようになります。
prior1 = @(b1) normpdf(b1,0,20); % prior for intercept prior2 = @(b2) normpdf(b2,0,20); % prior for slope
ベイズの定理により、モデル パラメーターの結合事後分布は、尤度と事前分布の積に比例します。
post = @(b) prod(binopdf(poor,total,logitp(b,weight))) ... % likelihood * prior1(b(1)) * prior2(b(2)); % priors
このモデルにおける事後分布の正規化定数は、解析的に処理しにくいことに注意してください。ただし、正規化定数が不明である場合でも、モデル パラメーターのおおよその範囲が既知であれば、事後分布を可視化することはできます。
b1 = linspace(-2.5, -1, 50); b2 = linspace(3, 5.5, 50); simpost = zeros(50,50); for i = 1:length(b1) for j = 1:length(b2) simpost(i,j) = post([b1(i), b2(j)]); end; end; mesh(b2,b1,simpost) xlabel('Slope') ylabel('Intercept') zlabel('Posterior density') view(-110,30)
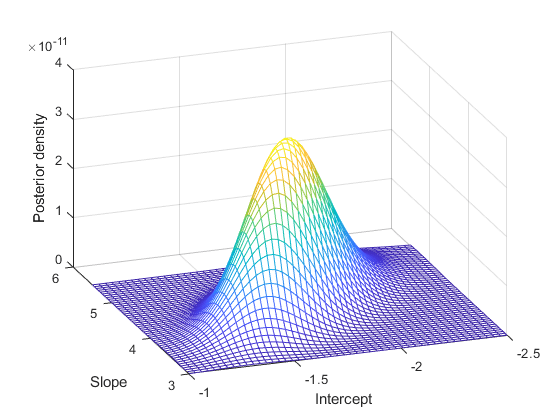
この事後分布は、パラメーター空間内で対角線方向に延ばされています。これは、データを調べた結果、パラメーターが相関していると思われることを示しています。これは興味深いことです。なぜなら、データを収集する前は、独立しているものと想定していたからです。この相関は、事前分布と尤度関数を組み合わせたことに由来します。
スライス サンプリング
データのベイズ解析では、事後分布を集計するためにモンテ カルロ法がよく使用されます。これは、事後分布を解析的に計算できない場合でも、分布から無作為標本を生成し、このランダムな値を使用して事後分布または派生統計量 (事後分布の平均値、中央値、標準偏差など) を推定できるという考え方です。スライス サンプリングは、比例定数 (これはまさに、正規化定数が未知である解析しにくい事後分布から標本を抽出するために必要とされるものです) までしかわかっていないときに、任意の密度関数を使用して分布から標本を抽出することを目的とするアルゴリズムの一種です。このアルゴリズムでは、独立した標本は生成されず、定常分布が対象の分布であるマルコフ系列が生成されます。このように、スライス サンプラーは、マルコフ連鎖モンテ カルロ (MCMC) アルゴリズムの一種です。ただし、スライス サンプラーは、よく知られている他の MCMC アルゴリズムとは異なります。指定する必要があるのは、スケーリングされた事後分布だけであるからです。提案分布と周辺分布を指定する必要はありません。
スライス サンプラーを燃費テストのロジスティック回帰モデルのベイズ解析の一部として使用する方法を次の例に示します。これには、モデル パラメーターの事後分布から無作為標本を生成し、サンプラーの出力を解析し、モデル パラメーターについて推定を行うことも含まれます。最初の手順は乱数標本を生成することです。
initial = [1 1]; nsamples = 1000; trace = slicesample(initial,nsamples,'pdf',post,'width',[20 2]);
サンプラー出力の解析
スライス サンプラーから無作為標本を取得した後は、収束や混合などの問題を調査することが重要です。これは、その標本が、対象の事後分布から得られる無作為の実現の集合として妥当に処理され得るかどうかを判断するためです。出力を調べる最も簡単な方法は、周辺のトレース プロットを確認することです。
subplot(2,1,1) plot(trace(:,1)) ylabel('Intercept'); subplot(2,1,2) plot(trace(:,2)) ylabel('Slope'); xlabel('Sample Number');
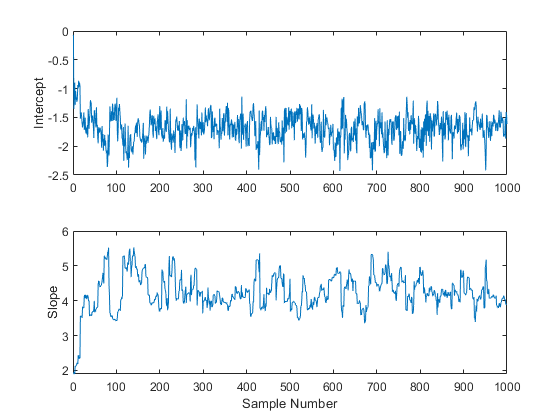
これらのプロットから、50 件ほどの標本でパラメーターの開始値の影響が消えて、プロセスが変動しないように見えるまでにしばらく時間がかかることは明らかです。
また、収束の有無を確認する際に、移動ウィンドウを使用して統計量 (標本の平均値、中央値、標準偏差など) を計算することも役に立ちます。これにより、生のサンプル トレースより滑らかなプロットが得られるので、非定常性の識別と理解が簡単になります。
movavg = filter( (1/50)*ones(50,1), 1, trace); subplot(2,1,1) plot(movavg(:,1)) xlabel('Number of samples') ylabel('Means of the intercept'); subplot(2,1,2) plot(movavg(:,2)) xlabel('Number of samples') ylabel('Means of the slope');
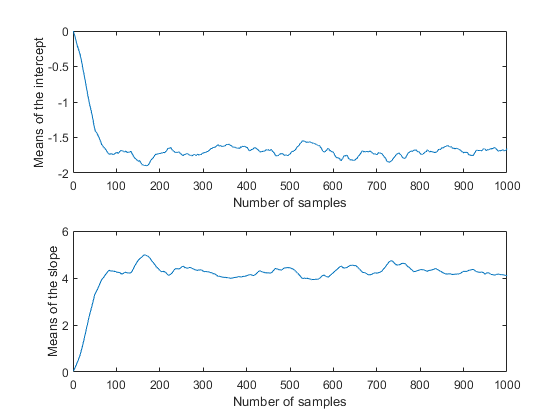
これらは、反復回数 50 回の間の移動平均なので、最初の 50 個の値はプロットのその他の値とは比較できません。ただし、各プロットの残りは、パラメーターの事後平均が 100 回ほどの反復の後に定常性に収束したことを裏づけているように思われます。また、2 つのパラメーターが、事後密度の前のプロットに一致して相互に相関し合っていることも明らかです。
沈静化期間の標本は対象の分布から得られる無作為の実現として適切には処理できないため、スライス サンプラーの出力の最初の 50 個ほどの値は使用しないことをお勧めします。単にそれらの出力行を削除することもできますが、"バーンイン" 期間を指定することも可能です。これは、適切なバーンイン長が (以前の実行例から) 既にわかっている場合に便利です。
trace = slicesample(initial,nsamples,'pdf',post, ... 'width',[20 2],'burnin',50); subplot(2,1,1) plot(trace(:,1)) ylabel('Intercept'); subplot(2,1,2) plot(trace(:,2)) ylabel('Slope');
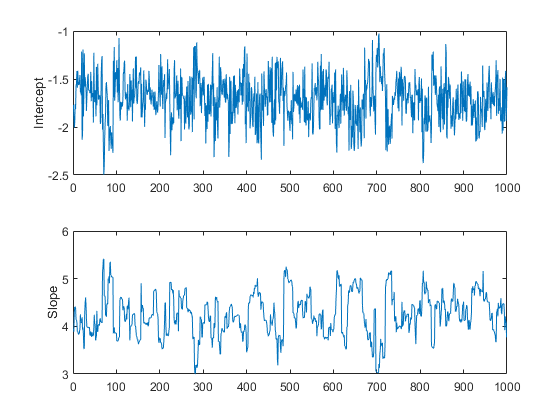
これらのトレース プロットは、非定常性を示しているようには見えず、バーンイン期間が自己の仕事を完了したことを示しています。
ただし、トレース プロットには別の面があり、これも調査する必要があります。intercept パラメーターのトレースが高周波ノイズのように見えるのに対して、slope パラメーターのトレースの周波数成分は比較的低いようです。これは、隣接する反復箇所で値間に自己相関があることを示します。この自己相関標本から平均値を計算することはできますが、標本内の冗長部分を取り除いて、必要とされるストレージを下げると都合が良い場合がよくあります。これにより自己相関が排除された場合には、これを複数の独立値で構成される標本として扱うこともできます。たとえば、10 個に 1 個の比率で 10 番目の値だけを残すことにより、標本を減らすことができます。
trace = slicesample(initial,nsamples,'pdf',post,'width',[20 2], ... 'burnin',50,'thin',10);
この間引きの効果を確認するには、標本の自己相関関数をトレースから推定し、その関数を使用して標本がすぐに混合するかどうかを確認します。
F = fft(detrend(trace,'constant')); F = F .* conj(F); ACF = ifft(F); ACF = ACF(1:21,:); % Retain lags up to 20. ACF = real([ACF(1:21,1) ./ ACF(1,1) ... ACF(1:21,2) ./ ACF(1,2)]); % Normalize. bounds = sqrt(1/nsamples) * [2 ; -2]; % 95% CI for iid normal labs = {'Sample ACF for intercept','Sample ACF for slope' }; for i = 1:2 subplot(2,1,i) lineHandles = stem(0:20, ACF(:,i) , 'filled' , 'r-o'); lineHandles.MarkerSize = 4; grid('on') xlabel('Lag') ylabel(labs{i}) hold on plot([0.5 0.5 ; 20 20] , [bounds([1 1]) bounds([2 2])] , '-b'); plot([0 20] , [0 0] , '-k'); hold off a = axis; axis([a(1:3) 1]); end
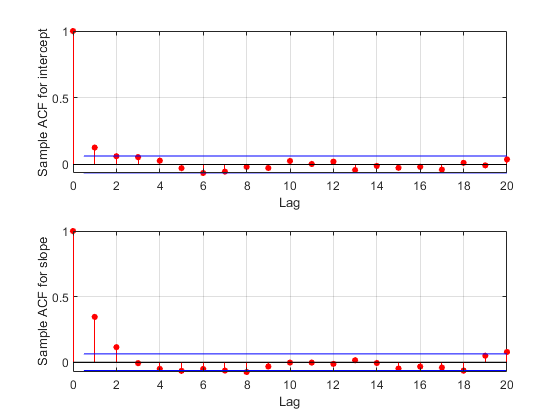
最初のラグにおける自己相関値は、intercept パラメーターにとって重要ですが、slope パラメーターにとってはさらに重要です。相関度をさらに引き下げるため、より大きい間引きパラメーターを使用してサンプリングを繰り返すことができます。ただし、この例では現在の標本を引き続き使用します。
モデル パラメーターの推定
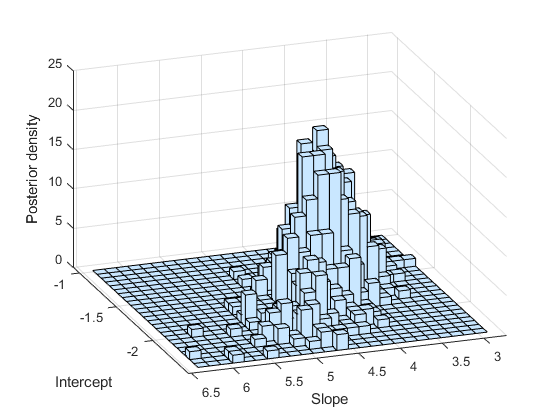
予想どおり、標本のヒストグラムは事後密度のプロットによく似ています。
subplot(1,1,1) histogram2(trace(:,1),trace(:,2)); xlabel('Intercept') ylabel('Slope') zlabel('Posterior density') view(-110,30)
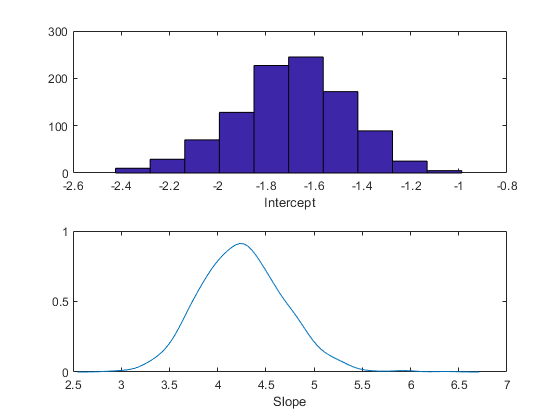
ヒストグラムまたはカーネルの平滑化密度推定を使用して、事後標本の周辺分布プロパティを集計することができます。
subplot(2,1,1) histogram(trace(:,1)) xlabel('Intercept'); subplot(2,1,2) ksdensity(trace(:,2)) xlabel('Slope');
また、記述統計量 (事後平均値や乱数標本の百分位など) を計算することもできます。標本サイズが目的の精度を得るのに十分な大きさかどうかを判断するには、標本数の関数としてトレースの目的の統計量を監視します。
csum = cumsum(trace); subplot(2,1,1) plot(csum(:,1)'./(1:nsamples)) xlabel('Number of samples') ylabel('Means of the intercept'); subplot(2,1,2) plot(csum(:,2)'./(1:nsamples)) xlabel('Number of samples') ylabel('Means of the slope');

このケースでは、良好な精度の事後平均値推定を得るために、標本サイズ 1,000 は十分すぎるほどの大きさがあるようです。
bHat = mean(trace)
bHat = 1×2
-1.6931 4.2569
まとめ
Statistics and Machine Learning Toolbox™ には、尤度と事前分布を簡単に指定できる各種の関数が用意されています。それらの関数を組み合わせて、1 つの事後分布を導き出すことができます。関数 slicesample を使用すると、マルコフ連鎖モンテ カルロ シミュレーションを使用して MATLAB でベイズ解析を実行することができます。この関数は、標準の乱数発生器を使用して標本を抽出するのが難しい事後分布に関する問題にも使用することができます。