分類学習器アプリの誤分類コスト
既定で、分類学習器アプリは学習中にすべての誤分類に同じペナルティを割り当てるモデルを作成します。特定の観測値について、その観測値が正しく分類されると 0 のペナルティが割り当てられ、その観測値が誤って分類されると 1 のペナルティが割り当てられます。この割り当ては不適切な場合もあります。たとえば、患者を健康か病気かのいずれかとして分類するとします。病気の人を健康として誤分類するコストは、健康な人を病気として誤分類するコストの 5 倍になる可能性があります。クラス間で観測値を誤分類するコストがわかっていて、そのコストがクラスによって異なる場合は、モデルに学習させる前に誤分類コストを指定します。
メモ
カスタムな誤分類コストはロジスティック回帰モデルではサポートされません。
誤分類コストの指定
分類学習器アプリで、[学習] タブの [オプション] セクションで [コスト] を選択します。応答変数のクラスによって決定される行ラベルと列ラベルをもつテーブルとして既定の誤分類コスト (コスト行列) を表示するダイアログ ボックスが開きます。テーブルの行は真のクラスに、列は予測クラスに対応します。コスト行列は、行 i と列 j のエントリが i 番目のクラスの観測値を j 番目のクラスに誤分類するコストであると、解釈できます。コスト行列の対角要素は 0 でなければならず、非対角要素は非負の実数でなければなりません。
ダイアログ ボックスのテーブルに値を直接入力するか、コストの値が含まれるワークスペース変数をインポートする 2 つの方法で独自の誤分類コストを指定できます。

メモ
コスト行列のスケーリングしたバージョンからは同じ分類結果が得られますが (混同行列と精度など)、総誤分類コストは異なります。すなわち、CostMat が誤分類コスト行列で a が正の実数スカラーである場合、コスト行列 a*CostMat で学習させたモデルには CostMat で学習させたモデルと同じ混同行列があります。
ダイアログ ボックスへのコストの直接入力
[誤分類コスト] ダイアログ ボックスで、編集するテーブルのエントリをダブルクリックします。このエントリの正しい誤分類コストの値とタイプを削除します。テーブルの編集が完了したら、[保存して適用] をクリックして変更を保存します。変更は、既存のすべてのドラフト モデルと、[学習] タブの [モデル] ギャラリーを使用して作成する新しいドラフト モデルに適用されます。
コストが含まれるワークスペース変数のインポート
[誤分類コスト] ダイアログ ボックスで、[ワークスペースからインポート] をクリックします。MATLAB® ワークスペースで変数からコストをインポートするダイアログ ボックスが開きます。
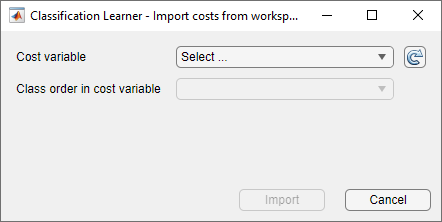
[コスト変数] リストから、誤分類コストが含まれるコスト行列または構造体を選択します。
コスト行列 – 行列には誤分類コストを含めなければなりません。対角要素は 0 でなければならず、非対角要素は非負の実数でなければなりません。既定では、前の [誤分類コスト] ダイアログ ボックスに表示されたクラスの順序を使用してコスト行列の値が解釈されます。
コスト行列のクラスの順序を指定するには、正しい順序でクラス名が含まれる個別のワークスペース変数を作成します。[インポート] ダイアログ ボックスで、[コスト変数内のクラス順序] リストから適切な変数を選択します。クラス名が含まれるワークスペース変数は、categorical ベクトル、logical ベクトル、数値ベクトル、string 配列、または文字ベクトルの cell 配列でなければなりません。クラス名は、応答変数のクラス名と (スペルおよび大文字/小文字の使用で) 一致しなければなりません。
構造体 – 構造体には以下が指定された
ClassificationCostsフィールドとClassNamesフィールドが含まれていなければなりません。ClassificationCosts– 誤分類コストが含まれる行列。ClassNames– クラスの名前。ClassNamesのクラスの順序によってClassificationCostsの行と列の順序が決まります。変数ClassNamesは、categorical ベクトル、logical ベクトル、数値ベクトル、string 配列、または文字ベクトルの cell 配列でなければなりません。クラス名は、応答変数のクラス名と (スペルおよび大文字/小文字の使用で) 一致しなければなりません。
コスト変数とコスト変数内のクラス順序を指定した後、[インポート] をクリックします。[誤分類コスト] ダイアログ ボックスで、テーブルが更新されます。
既定とは異なるコスト行列を指定した後に、既存のドラフト モデルの [概要] タブが更新されます。[概要] ペインに、[誤分類コスト: カスタム] セクションが表示されます。既定の誤分類コストを使用するモデルの場合は、[誤分類コスト: 既定] セクションが表示されます。
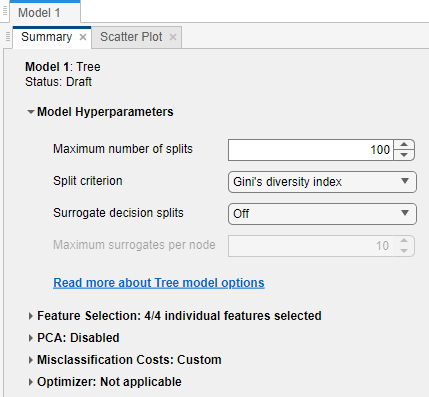
[誤分類コスト: カスタム] をクリックするとセクションを展開でき、誤分類コストのテーブルを表示できます。
モデルの性能評価
誤分類コストを指定した後、通常どおりモデルに学習させて調整できます。ただし、カスタムな誤分類コストを使用するとモデルの性能を評価する方法が変更される可能性があります。たとえば、最高精度をもつモデルが選択されるのではなく、精度が高く、総誤分類コストが低いモデルが選択されます。モデルの総誤分類コストは sum(CostMat.*ConfusionMat,"all") です。ここで、CostMat は誤分類コスト行列で、ConfusionMat はモデルの混同行列です。混同行列は各クラスでモデルがどのように観測値を分類するのかを示します。混同行列におけるクラスごとの性能のチェック を参照してください。
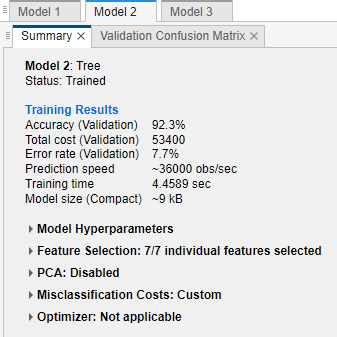
学習済みモデルの総誤分類コストを調べるには、[モデル] ペインでモデルを選択します。モデルを右クリックして [概要] を選択します。[概要] タブで、[学習結果] セクションを確認します。総誤分類コストがモデルの精度の下に一覧表示されます。
エクスポートされたモデルと生成されたコードの誤分類コスト
カスタムな誤分類コストでモデルに学習させ、アプリからエクスポートすると、エクスポートされたモデル内でカスタム コストを見つけることができます。たとえば、ツリー モデルを trainedModel という名前の構造体としてエクスポートすると、次のコードを使用してコスト行列および行列内のクラスの順序にアクセスできます。
trainedModel.ClassificationTree.Cost trainedModel.ClassificationTree.ClassNames
カスタムな誤分類コストで学習されたモデルの MATLAB コードを生成すると、生成されたコードには、名前と値の引数 Cost を介して学習関数に渡されるコスト行列が含められます。