このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
分類学習器アプリの誤分類コストを使用した分類器の学習および比較
この例では、分類学習器アプリで指定した誤分類コストを使用する分類器を作成して比較する方法を示します。学習前に誤分類コストを指定し、精度および総誤分類コスト結果を使用して学習済みモデルを比較します。
MATLAB® コマンド ウィンドウで、
CreditRating_Historical.datファイルを table に読み込みます。openExample("CreditRating_Historical.dat")[インポート ツール] が開きます。
[インポート] タブの [インポートされた変数] セクションで、[名前] ボックスに「
creditrating」と入力します。[インポート] セクションで、[選択のインポート] をクリックして [データのインポート] を選択します。
予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。すべての
A格付けを 1 つの格付けに統合します。BとCの格付けに対して同様に実行し、応答変数に 3 つの異なる格付けが含まれるようにします。3 つの格付けのうち、Aが最良でCが最悪と見なされます。Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A"],"A"); Rating = mergecats(Rating,["BBB","BB","B"],"B"); Rating = mergecats(Rating,["CCC","CC","C"],"C"); creditrating.Rating = Rating;
これらを顧客の格付けの誤分類に関連付けられたコストと仮定します。
顧客の予測された格付け ABC顧客の真の格付け A$0 $100 $200 B$500 $0 $100 C$1000 $500 $0 たとえば、
Cの格付け顧客をAの格付け顧客として誤分類するコストは $1000 です。このコストは、信用が高い顧客を信用が低い顧客として分類するより、信用が低い顧客を信用が高い顧客として分類するほうが、コストが高いことを示しています。誤分類コストを含む行列変数を作成します。クラス名と行列変数におけるそれらの順序を指定する別の変数を作成します。
ClassificationCosts = [0 100 200; 500 0 100; 1000 500 0]; ClassNames = categorical(["A","B","C"]);
ヒント
または、分類学習器アプリ内で誤分類コストを直接指定することもできます。詳細は、誤分類コストの指定を参照してください。
分類学習器を開きます。[アプリ] タブをクリックしてから、[アプリ] セクションの右にある矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] グループの [分類学習器] をクリックします。

[学習] タブの [ファイル] セクションで、[新規セッション]、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから table
creditratingを選択します。ダイアログ ボックスに示されているように、データ型に基づいて応答および予測子変数が選択されます。既定の応答変数は変数
Ratingです。既定の検証オプションは、過適合を防止する交差検証です。この例では、既定の設定を変更しないでください。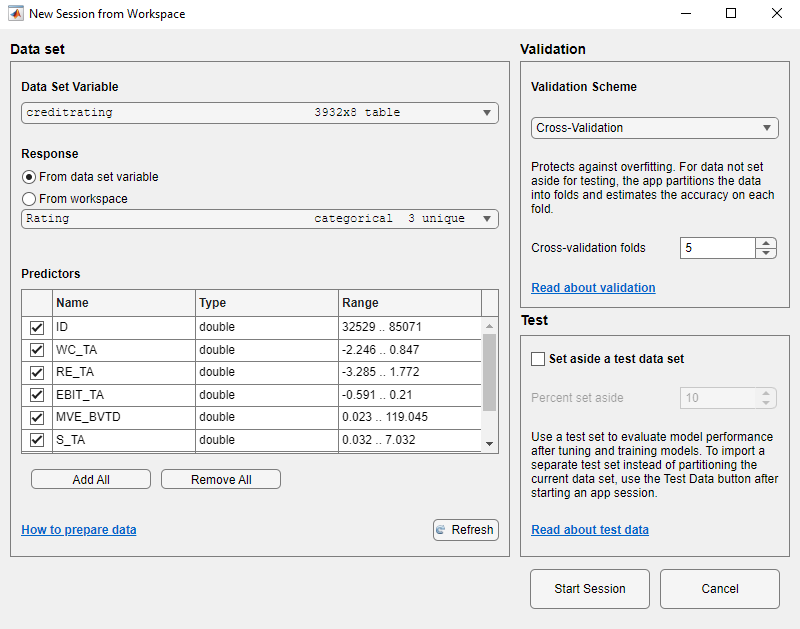
既定の設定をそのまま使用するには、[セッションの開始] をクリックします。
誤分類コストを指定します。[学習] タブの [オプション] セクションで [コスト] をクリックします。ダイアログ ボックスが開き、既定の誤分類コストが表示されます。
ダイアログ ボックスで [ワークスペースからインポート] をクリックします。

[インポート] ダイアログ ボックスで、
[ClassificationCosts]をコスト変数、[ClassNames]をコスト変数内のクラス順序として選択します。[インポート] をクリックします。
[誤分類コスト] ダイアログ ボックスで、値が更新されます。[保存して適用] をクリックして変更を保存します。新しい誤分類コストは [モデル] ペインの既存のドラフト モデルに適用されるほか、[学習] タブの [モデル] セクションのギャラリーを使用して作成する新しいドラフト モデルに適用されます。

複雑な木、中程度の木、粗い木を同時に学習させます。複雑な木のモデルは [モデル] ペインに既に含まれています。中程度の木と粗い木のモデルをドラフト モデルのリストに追加します。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[決定木] グループで [中程度の木] をクリックします。ドラフトの中程度の木が作成され、[モデル] ペインに追加されます。モデル ギャラリーを再度開き、[決定木] グループで [粗い木] をクリックします。ドラフトの粗い木が作成され、[モデル] ペインに追加されます。
[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。3 つの木のモデルの学習が行われます。
メモ
Parallel Computing Toolbox™ がある場合は、[並列の使用] ボタンが既定でオンになります。[すべてを学習] をクリックして [すべてを学習] または [選択を学習] を選択すると、ワーカーの並列プールが開きます。この間、ソフトウェアの対話的な操作はできません。プールが開いた後、モデルの学習を並列で実行しながらアプリの操作を続けることができます。
Parallel Computing Toolbox がない場合は、[すべてを学習] メニューの [バックグラウンド学習を使用] チェック ボックスが既定でオンになります。オプションを選択してモデルに学習させると、バックグラウンド プールが開きます。プールが開いた後、モデルの学習をバックグラウンドで実行しながらアプリの操作を続けることができます。

メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
[モデル] ペインに、各モデルの正しく予測された応答の割合を示す検証精度のスコアがあります。最も高い [精度 (検証)] のスコアが四角で囲まれて強調表示されます。
モデルをクリックして結果を表示します。これは、[概要] タブに表示されます。このタブを開くには、モデルを右クリックして [概要] を選択します。
各クラスにおける予測子の精度を調べます。[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [混同行列 (検証)] をクリックします。選択したモデルに対する真のクラスと予測したクラスの結果が含まれている行列が表示されます (この場合は、中程度の木)。

予測クラスごとに結果をプロットして偽発見率を調査することもできます。[プロット] の [陽性の予測値 (PPV) 偽発見率 (FDR)] オプションを選択します。
中程度の木の混同行列で、対角の下の要素には小さな割合の値があります。これらの値は、モデルが顧客の真の格付けよりも高い格付けを割り当てないようにしていることを示しています。

ツリー モデルの総誤分類コストを比較します。モデルの総誤分類コストを調べるには、[モデル] ペインでモデルを選択してから、[概要] タブで [学習結果] セクションを確認します。たとえば、中程度の木には結果が 3 つあります。
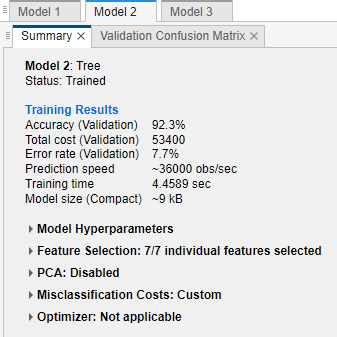
あるいは、総誤分類コストに基づいてモデルを並べ替えることができます。[モデル] ペインで [並べ替え] リストを開き、
[総コスト (検証)]を選択します。一般的に、精度が高く、総誤分類コストが低いモデルを選択します。この例では、3 つのモデルのうち、中程度の木に最高の検証精度の値と最低の総誤分類コストがあります。
ワークフローで行うように、誤分類コストなしでモデルの特徴選択および変換または調整を実行できます。ただし、性能を評価する際に常にモデルの総誤分類コストをチェックします。エクスポートされたモデルとエクスポートされたコードの誤分類コストを確認する方法の詳細については、エクスポートされたモデルと生成されたコードの誤分類コストを参照してください。