maineffectsplot
グループ化されたデータの主効果プロット
説明
maineffectsplot( は、1 つ以上の名前と値の引数を使用して追加オプションを指定します。たとえば、グループ化変数の名前やプロットする統計量を指定できます。Y,group,Name=Value)
例
carsmall データ セットを読み込みます。
load carsmall;モデル年と気筒数の 2 つのグループ化変数を使用して、自動車の重量に対する主効果プロットを作成します。
maineffectsplot(Weight,{Model_Year,Cylinders}, ...
VarNames=["Model Year","# of Cylinders"])
最初のサブプロットは、モデル年が後になるほど自動車の平均重量が減ることを示しています。2 番目のサブプロットは、気筒数と共に自動車の平均重量が急激に増えることを示しています。
carsmall データ セットを読み込みます。
load carsmall;Weight の予測子データとシミュレーションでノイズを加えた 4 セットの Weight の観測値を格納する行列 Y を作成します。
rng(0,"twister") % For reproducibility noise_std = 10; Y = [Weight, ... Weight+noise_std*randn(size(Weight)), ... Weight+noise_std*randn(size(Weight)), ... Weight+noise_std*randn(size(Weight)), ... Weight+noise_std*randn(size(Weight))];
モデル年と気筒数の 2 つのグループ化変数を使用して、自動車の重量の観測値に対する主効果プロットを作成します。観測値の標準偏差をプロットします。
maineffectsplot(Y,{Model_Year,Cylinders},Statistic="std", ...
VarNames=["Model Year","# of Cylinders"])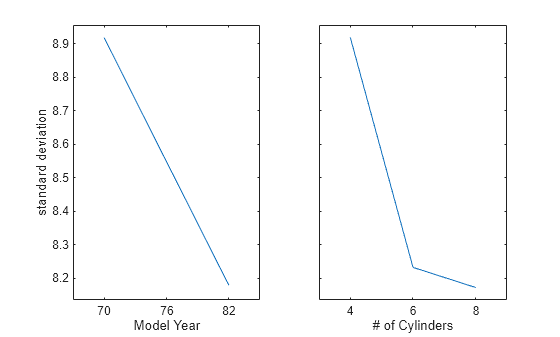
サブプロットは、モデル年と気筒数のどちらについても、それらと共に自動車の重量の標準偏差が減ることを示しています。
入力引数
名前と値の引数
出力引数
バージョン履歴
R2006b で導入