バイナリ分類の公平性の紹介
Statistics and Machine Learning Toolbox™ の関数 fairnessMetrics、fairnessWeights、disparateImpactRemover、および fairnessThresholder で、バイナリ分類の社会的バイアスを検出して軽減できます。まず、fairnessMetrics を使用して、バイアス メトリクスとグループ メトリクスでデータ セットまたは分類モデルの公平性を評価します。その後、fairnessWeights を使用して観測値を再重み付けするか、disparateImpactRemover を使用してセンシティブ属性による差異の影響を除去するか、fairnessThresholder を使用して分類しきい値を最適化します。
fairnessMetrics— 関数fairnessMetricsは、データ セットまたはバイナリ分類モデルのセンシティブ属性についての公平性メトリクス (バイアス メトリクスとグループ メトリクス) を計算します。データレベルの評価では、データの真のバイナリ ラベルを調べます。モデルレベルの評価では、1 つ以上のバイナリ分類モデルによって返される予測ラベルを真のラベルと予測ラベルの両方を使用して調べます。これらのメトリクスを使用して、データまたはモデルについて、各センシティブ属性のグループに対するバイアスがないかどうかを判別できます。fairnessWeights— 関数fairnessWeightsは、センシティブ属性と応答変数についての公平性の重みを計算します。センシティブ属性のグループと応答変数のクラス ラベルのすべての組み合わせについて、それぞれの重みの値が計算されます。その後、関数によって各観測値に対応する重みが割り当てられます。返される重みにより、センシティブ属性のグループ間に公平性が導入されます。名前と値の引数Weightsを使用して、これらの重みをfitcsvmなどの適切な学習関数に渡します。disparateImpactRemover— 関数disparateImpactRemoverは、センシティブ属性を使用してデータ セット内の連続予測子を変換することで、モデル予測に対するセンシティブ属性による差異の影響を除去するように試みます。変換されたデータ セットと変換が格納されたdisparateImpactRemoverオブジェクトが関数から返されます。変換されたデータ セットをfitcsvmなどの適切な学習関数に渡し、オブジェクトをオブジェクト関数transformに渡して、テスト データ セットなどの新しいデータ セットに変換を適用します。fairnessThresholder— 関数fairnessThresholderは、公平性の範囲を満たしながら精度が最大になるように最適なスコアのしきい値を探します。最適なしきい値を下回る臨界領域の観測値については、センシティブ属性の参照グループと非参照グループで公平性の制約が保たれるように関数でラベルが調整されます。fairnessThresholderオブジェクトを作成した後、オブジェクト関数predictとlossを新しいデータで使用して、公平性のラベルの予測と分類損失の計算をそれぞれ行うことができます。
公平性の重みを使用した統計的均一性差の軽減
ニューラル ネットワーク モデルに学習させ、センシティブ属性の各グループについての統計的均一性差 (SPD) を計算します。SPD の値を小さくするために、公平性の重みを計算し、ニューラル ネットワーク モデルに再学習させます。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。
creditrating = readtable("CreditRating_Historical.dat");変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
応答変数 Rating について、AAA、AA、A、および BBB の格付けを "good" の格付けのカテゴリに結合し、BB、B、および CCC の格付けを "poor" の格付けのカテゴリに結合します。
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
creditrating のデータでニューラル ネットワーク モデルに学習させます。より良い結果を得るために、モデルを当てはめる前に予測子を標準化します。学習させたモデルを使用して、学習データ セットのラベルを予測します。
rng("default") % For reproducibility netMdl = fitcnet(creditrating,"Rating",Standardize=true); netPredictions = predict(netMdl,creditrating);
モデル予測を使用して、センシティブ属性 Industry についての公平性メトリクスを計算します。特に、Industry の各グループについての統計的均一性差 (SPD) を調べます。
netMetricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry",Predictions=netPredictions); report(netMetricsResults,BiasMetrics="StatisticalParityDifference")
ans=12×4 table
ModelNames SensitiveAttributeNames Groups StatisticalParityDifference
__________ _______________________ ______ ___________________________
Model1 Industry 1 0.079969
Model1 Industry 2 0.1046
Model1 Industry 3 0
Model1 Industry 4 0.11218
Model1 Industry 5 0.066755
Model1 Industry 6 0.0080779
Model1 Industry 7 0.041107
Model1 Industry 8 0.10211
Model1 Industry 9 0.16267
Model1 Industry 10 0.16809
Model1 Industry 11 0.030313
Model1 Industry 12 0.049596
SPD の値の分布が理解しやすくなるように、箱ひげ図を使用して値をプロットします。
spdValues = netMetricsResults.BiasMetrics.StatisticalParityDifference; boxchart(spdValues) ylabel("Statistical Parity Difference") title("Distribution of Statistical Parity Differences")

SPD の値の中央値は約 0.06 で、公平なモデルの値 0 よりも高くなっています。
公平性の重みを計算し、その重みを使用してニューラル ネットワーク モデルを再度当てはめます。前と同じように、予測子を標準化します。その後、新しいモデルを使用して学習データのラベルを予測します。
weights = fairnessWeights(creditrating,"Industry","Rating"); rng("default") % For reproducibility newNetMdl = fitcnet(creditrating,"Rating",Weights=weights, ... Standardize=true); newNetPredictions = predict(newNetMdl,creditrating);
新しい SPD の値を計算します。
newNetMetricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry",Predictions=newNetPredictions); report(newNetMetricsResults,BiasMetrics="StatisticalParityDifference")
ans=12×4 table
ModelNames SensitiveAttributeNames Groups StatisticalParityDifference
__________ _______________________ ______ ___________________________
Model1 Industry 1 0.054401
Model1 Industry 2 0.064459
Model1 Industry 3 0
Model1 Industry 4 0.071624
Model1 Industry 5 0.032567
Model1 Industry 6 -0.0051521
Model1 Industry 7 0.013268
Model1 Industry 8 0.074074
Model1 Industry 9 0.11629
Model1 Industry 10 0.11538
Model1 Industry 11 0.026125
Model1 Industry 12 0.012243
SPD の値の 2 つの分布を表示します。左の箱ひげ図は、元のモデルを使用して計算された SPD の値を示しています。右の箱ひげ図は、公平性の重み付きで学習させた新しいモデルを使用して計算された SPD の値を示しています。
spdValuesUpdated = newNetMetricsResults.BiasMetrics.StatisticalParityDifference; boxchart([spdValues spdValuesUpdated]) xticklabels(["Without Weights","With Weights"]) ylabel("Statistical Parity Difference") title("Distribution of Statistical Parity Differences")

新しい SPD の値の中央値は約 0.04 で、前の中央値の 0.06 よりも 0 に近くなっています。新しい SPD の値の最大値は約 0.11 で、これも前の最大値の約 0.16 よりも 0 に近くなっています。
予測による差異の影響の軽減
バイナリ分類器に学習させ、モデルを使用してテスト データを分類し、センシティブ属性の各グループについての差異の影響を計算します。差異の影響の値を小さくするために、disparateImpactRemover を使用してからバイナリ分類器に再学習させます。テスト データ セットを変換し、観測値を再分類して、差異の影響の値を計算します。
学習データ adultdata およびテスト データ adulttest を含む、標本データ census1994 を読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するために使用できる、米国国勢調査局の人口統計情報から構成されています。学習データ セットの最初の数行をプレビューします。
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
各行には、成人 1 人の人口統計情報が格納されています。最後の列 salary は個人の年収が $50,000 以下か、$50,000 を超えるかどうかを示します。
adultdata と adulttest から欠損値を含む観測値を削除します。
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
モデルの学習に使用する連続数値予測子を指定します。
predictors = ["age","education_num","capital_gain","capital_loss", ... "hours_per_week"];
学習セット adultdata を使用してアンサンブル分類器に学習させます。応答変数として salary、観測値の重みとして fnlwgt を指定します。学習セットが不均衡であるため、RUSBoost アルゴリズムを使用します。モデルに学習させた後、テスト セット adulttest の観測値の給与 (クラス ラベル) を予測します。
rng("default") % For reproducibility mdl = fitcensemble(adultdata,"salary",Weights="fnlwgt", ... PredictorNames=predictors,Method="RUSBoost"); labels = predict(mdl,adulttest);
センシティブ属性 race を使用して学習セットの予測子を変換します。
[remover,newadultdata] = disparateImpactRemover(adultdata, ... "race",PredictorNames=predictors); remover
remover =
disparateImpactRemover with properties:
RepairFraction: 1
PredictorNames: {'age' 'education_num' 'capital_gain' 'capital_loss' 'hours_per_week'}
SensitiveAttribute: 'race'
remover は disparateImpactRemover オブジェクトであり、変数 remover.SensitiveAttribute を基準とする予測子 remover.PredictorNames の変換が格納されます。
remover に格納された同じ変換をテスト セットの予測子に適用します。メモ: 学習データ セットとテスト データ セットは、どちらも分類器に渡す前に変換する必要があります。
newadulttest = transform(remover,adulttest, ...
PredictorNames=predictors);mdl と同じタイプのアンサンブル分類器に今度は変換後の予測子データを使用して学習させます。前と同じように、テスト セット adulttest の観測値の給与 (クラス ラベル) を予測します。
rng("default") % For reproducibility newMdl = fitcensemble(newadultdata,"salary",Weights="fnlwgt", ... PredictorNames=predictors,Method="RUSBoost"); newLabels = predict(newMdl,newadulttest);
元のモデル (mdl) による予測と変換後のデータで学習させたモデル (newMdl) による予測について、差異の影響の値を比較します。差異の影響の値は、センシティブ属性のグループごとに、そのグループの陽性クラスの値をもつ予測の比率 () を参照グループの陽性クラスの値をもつ予測の比率 () で除算したものです。理想的な分類器による予測では、各グループの が に近くなります (つまり、差異の影響の値が 1 に近くなります)。
fairnessMetrics を使用して、mdl による予測と newMdl による予測の差異の影響の値を計算します。観測値の重みを含めます。オブジェクト関数 report を使用して、metricsResults オブジェクトに格納された差異の影響などのバイアス メトリクスを表示できます。
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames="race",Predictions=[labels,newLabels], ... Weights="fnlwgt",ModelNames=["Original Model","New Model"]); metricsResults.PositiveClass
ans = categorical
>50K
metricsResults.ReferenceGroup
ans = 'White'
report(metricsResults,BiasMetrics="DisparateImpact")ans=5×5 table
Metrics SensitiveAttributeNames Groups Original Model New Model
_______________ _______________________ __________________ ______________ _________
DisparateImpact race Amer-Indian-Eskimo 0.41702 0.92804
DisparateImpact race Asian-Pac-Islander 1.719 0.9697
DisparateImpact race Black 0.60571 0.66629
DisparateImpact race Other 0.66958 0.86039
DisparateImpact race White 1 1
mdl による予測について、いくつかの差異の影響の値が業界標準の 0.8 を下回っており、1.25 を超える値も 1 つあります。これらの値は、陽性クラス >50K とセンシティブ属性 race を基準とする予測のバイアスを示しています。
mdl による予測の差異の影響の値に比べ、newMdl による予測の差異の影響の値は 1 に近くなっています。0.8 を下回る値もまだ 1 つあります。
オブジェクト関数 plot で返される棒グラフを使用して、差異の影響の値を視覚的に比較します。
plot(metricsResults,"DisparateImpact")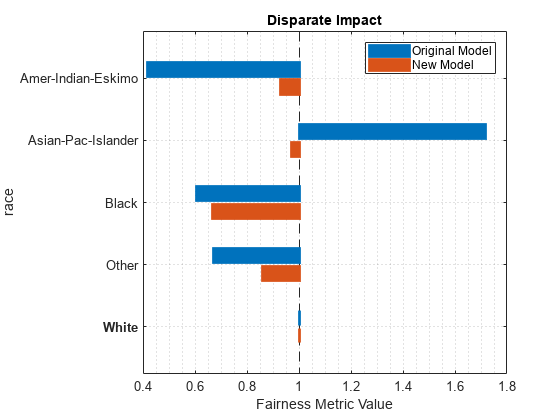
関数 disparateImpactRemover により、差異の影響のメトリクスに関しては、テスト セットに対するモデル予測が改善しているように見えます。
変換後の予測子がモデル予測の精度にマイナスの影響を与えていないかどうかをチェックします。2 つのモデル mdl と newMdl について、テスト セットの予測の精度を計算します。
accuracy = 1-loss(mdl,adulttest,"salary")accuracy = 0.8024
newAccuracy = 1-loss(newMdl,newadulttest,"salary")newAccuracy = 0.7955
テスト セットの精度について、変換後の予測子を使用して学習させたモデル (newMdl) でも元の予測子で学習させたモデル (mdl) と同等の精度になっています。
参考
fairnessMetrics | fairnessWeights | disparateImpactRemover | transform | fairnessThresholder | loss | predict