transform
構文
説明
transformedData = transform(remover,Tbl)Tbl の予測子データを disparateImpactRemover オブジェクト (remover) の変換に従って変換します。Tbl の予測子変数とセンシティブ属性は、remover の作成に使用した変数と同じ名前でなければなりません。変数の名前を確認するには、remover.PredictorNames および remover.SensitiveAttribute を使用します。
transformedData を返すために使用されたデータ変換の比率を確認するには、remover.RepairFraction を使用します。
transformedData = transform(remover,X,attribute)attribute を基準に変換されたデータ X を返します。
transformedData = transform(___,Name=Value)RepairFraction を使用してデータ変換の範囲を指定できます。値 1 は完全な変換を示し、値 0 は変換なしを示します。
例
バイナリ分類器に学習させ、モデルを使用してテスト データを分類し、センシティブ属性の各グループについての差異の影響を計算します。差異の影響の値を小さくするために、disparateImpactRemover を使用してからバイナリ分類器に再学習させます。テスト データ セットを変換し、観測値を再分類して、差異の影響の値を計算します。
学習データ adultdata およびテスト データ adulttest を含む、標本データ census1994 を読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するために使用できる、米国国勢調査局の人口統計情報から構成されています。学習データ セットの最初の数行をプレビューします。
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
各行には、成人 1 人の人口統計情報が格納されています。最後の列 salary は個人の年収が $50,000 以下か、$50,000 を超えるかどうかを示します。
adultdata と adulttest から欠損値を含む観測値を削除します。
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
モデルの学習に使用する連続数値予測子を指定します。
predictors = ["age","education_num","capital_gain","capital_loss", ... "hours_per_week"];
学習セット adultdata を使用してアンサンブル分類器に学習させます。応答変数として salary、観測値の重みとして fnlwgt を指定します。学習セットが不均衡であるため、RUSBoost アルゴリズムを使用します。モデルに学習させた後、テスト セット adulttest の観測値の給与 (クラス ラベル) を予測します。
rng("default") % For reproducibility mdl = fitcensemble(adultdata,"salary",Weights="fnlwgt", ... PredictorNames=predictors,Method="RUSBoost"); labels = predict(mdl,adulttest);
センシティブ属性 race を使用して学習セットの予測子を変換します。
[remover,newadultdata] = disparateImpactRemover(adultdata, ... "race",PredictorNames=predictors); remover
remover =
disparateImpactRemover with properties:
RepairFraction: 1
PredictorNames: {'age' 'education_num' 'capital_gain' 'capital_loss' 'hours_per_week'}
SensitiveAttribute: 'race'
remover は disparateImpactRemover オブジェクトであり、変数 remover.SensitiveAttribute を基準とする予測子 remover.PredictorNames の変換が格納されます。
remover に格納された同じ変換をテスト セットの予測子に適用します。メモ: 学習データ セットとテスト データ セットは、どちらも分類器に渡す前に変換する必要があります。
newadulttest = transform(remover,adulttest, ...
PredictorNames=predictors);mdl と同じタイプのアンサンブル分類器に今度は変換後の予測子データを使用して学習させます。前と同じように、テスト セット adulttest の観測値の給与 (クラス ラベル) を予測します。
rng("default") % For reproducibility newMdl = fitcensemble(newadultdata,"salary",Weights="fnlwgt", ... PredictorNames=predictors,Method="RUSBoost"); newLabels = predict(newMdl,newadulttest);
元のモデル (mdl) による予測と変換後のデータで学習させたモデル (newMdl) による予測について、差異の影響の値を比較します。差異の影響の値は、センシティブ属性のグループごとに、そのグループの陽性クラスの値をもつ予測の比率 () を参照グループの陽性クラスの値をもつ予測の比率 () で除算したものです。理想的な分類器による予測では、各グループの が に近くなります (つまり、差異の影響の値が 1 に近くなります)。
fairnessMetrics を使用して、mdl による予測と newMdl による予測の差異の影響の値を計算します。観測値の重みを含めます。オブジェクト関数 report を使用して、metricsResults オブジェクトに格納された差異の影響などのバイアス メトリクスを表示できます。
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames="race",Predictions=[labels,newLabels], ... Weights="fnlwgt",ModelNames=["Original Model","New Model"]); metricsResults.PositiveClass
ans = categorical
>50K
metricsResults.ReferenceGroup
ans = 'White'
report(metricsResults,BiasMetrics="DisparateImpact")ans=5×5 table
Metrics SensitiveAttributeNames Groups Original Model New Model
_______________ _______________________ __________________ ______________ _________
DisparateImpact race Amer-Indian-Eskimo 0.41702 0.92804
DisparateImpact race Asian-Pac-Islander 1.719 0.9697
DisparateImpact race Black 0.60571 0.66629
DisparateImpact race Other 0.66958 0.86039
DisparateImpact race White 1 1
mdl による予測について、いくつかの差異の影響の値が業界標準の 0.8 を下回っており、1.25 を超える値も 1 つあります。これらの値は、陽性クラス >50K とセンシティブ属性 race を基準とする予測のバイアスを示しています。
mdl による予測の差異の影響の値に比べ、newMdl による予測の差異の影響の値は 1 に近くなっています。0.8 を下回る値もまだ 1 つあります。
オブジェクト関数 plot で返される棒グラフを使用して、差異の影響の値を視覚的に比較します。
plot(metricsResults,"DisparateImpact")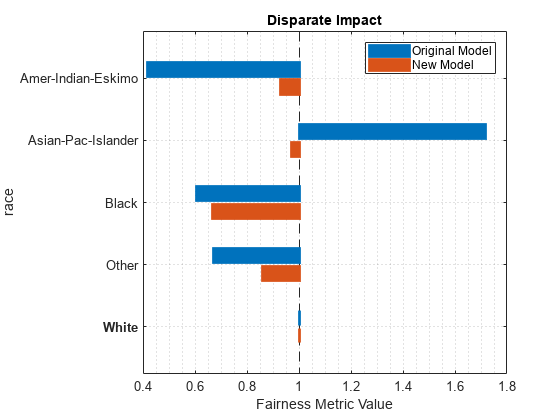
関数 disparateImpactRemover により、差異の影響のメトリクスに関しては、テスト セットに対するモデル予測が改善しているように見えます。
変換後の予測子がモデル予測の精度にマイナスの影響を与えていないかどうかをチェックします。2 つのモデル mdl と newMdl について、テスト セットの予測の精度を計算します。
accuracy = 1-loss(mdl,adulttest,"salary")accuracy = 0.8024
newAccuracy = 1-loss(newMdl,newadulttest,"salary")newAccuracy = 0.7955
テスト セットの精度について、変換後の予測子を使用して学習させたモデル (newMdl) でも元の予測子で学習させたモデル (mdl) と同等の精度になっています。
センシティブ属性を基準とする連続数値予測子の変換の範囲を指定します。関数 disparateImpactRemover の名前と値の引数 RepairFraction を使用します。
100 人の患者の医療情報を含む patients データ セットを読み込みます。変数 Gender と Smoker をカテゴリカル変数に変換します。1 と 0 の代わりに、Smoker と Nonsmoker というわかりやすいカテゴリ名を指定します。
load patients Gender = categorical(Gender); Smoker = categorical(Smoker,logical([1 0]), ... ["Smoker","Nonsmoker"]);
連続予測子 Diastolic と Systolic を含む行列を作成します。
X = [Diastolic,Systolic];
センシティブ属性 Gender の 2 つのグループの観測値を調べます。
femaleIdx = Gender=="Female"; maleIdx = Gender=="Male"; femaleX = X(femaleIdx,:); maleX = X(maleIdx,:);
センシティブ属性 Gender を使用して X の予測子 Diastolic と Systolic を変換します。修復率を 0.5 と指定します。値 1 は完全な変換を示し、値 0 は変換なしを示すことに注意してください。
[remover,newX50] = disparateImpactRemover(X,Gender, ...
RepairFraction=0.5);
femaleNewX50 = newX50(femaleIdx,:);
maleNewX50 = newX50(maleIdx,:);remover オブジェクトのオブジェクト関数 transform を使用して、予測子変数を完全に変換します。
newX100 = transform(remover,X,Gender,RepairFraction=1); femaleNewX100 = newX100(femaleIdx,:); maleNewX100 = newX100(maleIdx,:);
X の元の値、newX50 の部分的に修復した値、および newX100 の完全に変換した値での Diastolic の分布の違いを可視化します。関数 ksdensity を使用して、確率密度推定を計算して表示します。
t = tiledlayout(1,3); title(t,"Diastolic Distributions with Different " + ... "Repair Fractions") xlabel(t,"Diastolic") ylabel(t,"Density Estimate") nexttile ksdensity(femaleX(:,1)) hold on ksdensity(maleX(:,1)) hold off title("Fraction=0") ylim([0,0.07]) nexttile ksdensity(femaleNewX50{:,1}) hold on ksdensity(maleNewX50{:,1}) hold off title("Fraction=0.5") ylim([0,0.07]) nexttile ksdensity(femaleNewX100{:,1}) hold on ksdensity(maleNewX100{:,1}) hold off title("Fraction=1") ylim([0,0.07]) legend(["Female","Male"],Location="eastoutside")
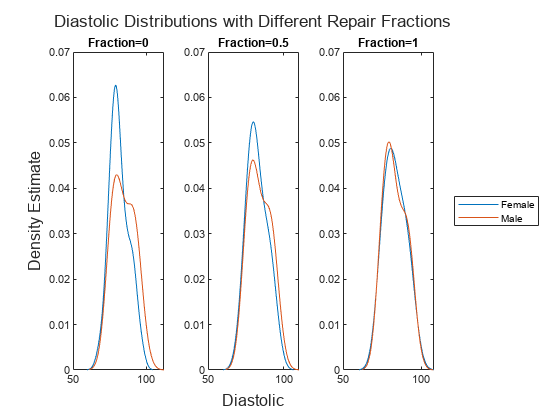
関数 disparateImpactRemover によって予測子変数 Diastolic の値が変換され、修復率が大きくなるほど、Female の値の分布と Male の値の分布がより似たような分布になっています。
入力引数
名前と値の引数
出力引数
バージョン履歴
R2022b で導入