predict
説明
fairnessLabels = predict(thresholder,Tbl)fairnessThresholder オブジェクト thresholder で table Tbl を使用して計算された公平性のラベルを返します。
fairnessLabels = predict(thresholder,X,attribute)fairnessThresholder オブジェクト thresholder で行列データ X と attribute で指定されたセンシティブ属性を使用して計算された公平性のラベルを返します。
例
バイナリ分類用の木アンサンブルに学習させ、センシティブ属性の各グループについての差異の影響を計算します。非参照グループの差異の影響の値を小さくするために、観測値を分類するスコアのしきい値を調整します。
データ census1994 を読み込みます。これには、データ セット adultdata とテスト データ セット adulttest が含まれています。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するために使用できる、米国国勢調査局の人口統計情報から構成されています。adultdata の最初の数行をプレビューします。
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
各行には、成人 1 人の人口統計情報が格納されています。age、marital_status、relationship、race、sex などのセンシティブ属性の情報が含まれます。3 列目の flnwgt に観測値の重みが格納されており、最後の列 salary は個人の年収が $50,000 以下 (<=50K) か $50,000 を超える (>50K) かを示します。
欠損値を含む観測値を削除します。
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
adultdata を学習セットと検証セットに分割します。観測値の 60% を学習セット trainingData に使用し、観測値の 40% を検証セット validationData に使用します。
rng("default") % For reproducibility c = cvpartition(adultdata.salary,"Holdout",0.4); trainingIdx = training(c); validationIdx = test(c); trainingData = adultdata(trainingIdx,:); validationData = adultdata(validationIdx,:);
学習データ セット trainingData を使用して木のブースティング アンサンブルに学習させます。table adultdata 内の変数名を使用して、応答変数、予測子変数、および観測値の重みを指定します。ランダム アンダーサンプリング ブースティングをアンサンブル集約法として使用します。
predictors = ["capital_gain","capital_loss","education", ... "education_num","hours_per_week","occupation","workClass"]; Mdl = fitcensemble(trainingData,"salary", ... PredictorNames=predictors, ... Weights="fnlwgt",Method="RUSBoost");
テスト データ セット adulttest 内の観測値について、給与の値を予測し、分類誤差を計算します。
labels = predict(Mdl,adulttest); L = loss(Mdl,adulttest)
L = 0.2080
テスト セットの観測値の約 80% について、給与の分類がモデルで正確に予測されています。
テスト セットのモデル予測を使用して、センシティブ属性 sex についての公平性メトリクスを計算します。特に、sex の各グループについての差異の影響を調べます。fairnessMetrics のオブジェクト関数 report と plot を使用して結果を表示します。
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames="sex",Predictions=labels, ... ModelNames="Ensemble",Weights="fnlwgt"); metricsResults.PositiveClass
ans = categorical
>50K
metricsResults.ReferenceGroup
ans = 'Male'
report(metricsResults,BiasMetrics="DisparateImpact")ans=2×4 table
ModelNames SensitiveAttributeNames Groups DisparateImpact
__________ _______________________ ______ _______________
Ensemble sex Female 0.73792
Ensemble sex Male 1
plot(metricsResults,"DisparateImpact")
差異の影響の値は、非参照グループ (Female) について、そのグループの陽性クラスの値 (>50K) をもつ予測の比率を参照グループ (Male) の陽性クラスの値をもつ予測の比率で除算したものです。差異の影響の値は 1 に近くなるのが理想的です。
非参照グループの差異の影響の値が改善するか試すために、関数 fairnessThresholder を使用してモデル予測を調整できます。この関数は、検証データを使用して、公平性の範囲を満たしながら精度が最大になる最適なスコアのしきい値を探します。最適なしきい値を下回る臨界領域の観測値については、参照グループと非参照グループで公平性の制約が保たれるように関数でラベルが変更されます。既定では、この関数は非参照グループの差異の影響の値が範囲 [0.8,1.25] になるスコアのしきい値を見つけようとします。
fairnessMdl = fairnessThresholder(Mdl,validationData,"sex","salary")
fairnessMdl =
fairnessThresholder with properties:
Learner: [1×1 classreg.learning.classif.CompactClassificationEnsemble]
SensitiveAttribute: 'sex'
ReferenceGroups: Male
ResponseName: 'salary'
PositiveClass: >50K
ScoreThreshold: 1.6749
BiasMetric: 'DisparateImpact'
BiasMetricValue: 0.9702
BiasMetricRange: [0.8000 1.2500]
ValidationLoss: 0.2017
fairnessMdl は fairnessThresholder モデル オブジェクトです。アンサンブル モデル Mdl の関数 predict が返すスコアは事後確率ではないことに注意してください。スコアの範囲は であり、各観測値の最大スコアは 0 より大きくなります。最大スコアが新しいスコアのしきい値 (fairnessMdl.ScoreThreshold) より小さい観測値について、fairnessMdl オブジェクトの関数 predict で予測が調整されます。非参照グループの観測値の場合、関数はその観測値を陽性クラスに予測します。参照グループの観測値の場合、関数はその観測値を陰性クラスに予測します。これらの調整の結果として予測ラベルが常に変わるとは限りません。
新しいスコアのしきい値を使用してテスト セットの予測を調整し、分類誤差を計算します。
fairnessLabels = predict(fairnessMdl,adulttest); fairnessLoss = loss(fairnessMdl,adulttest)
fairnessLoss = 0.2064
新しい分類誤差は元の分類誤差と同程度です。
Mdl を使用して計算した元の予測と fairnessMdl を使用して計算した調整後の予測の 2 セットのテストの予測で、それらの差異の影響の値を比較します。
newMetricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames="sex",Predictions=[labels,fairnessLabels], ... ModelNames=["Original","Adjusted"],Weights="fnlwgt"); newMetricsResults.PositiveClass
ans = categorical
>50K
newMetricsResults.ReferenceGroup
ans = 'Male'
report(newMetricsResults,BiasMetrics="DisparateImpact")ans=2×5 table
Metrics SensitiveAttributeNames Groups Original Adjusted
_______________ _______________________ ______ ________ ________
DisparateImpact sex Female 0.73792 1.0048
DisparateImpact sex Male 1 1
plot(newMetricsResults,"di")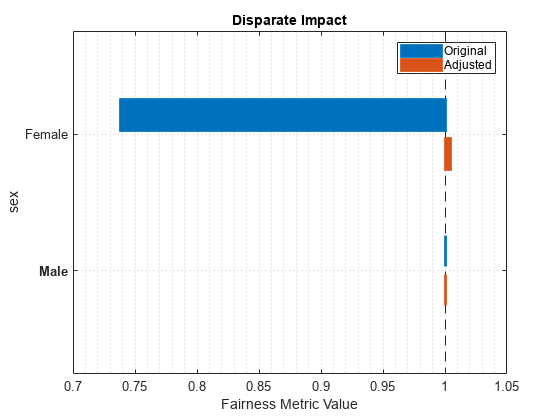
調整後の予測を使用した場合の方が、非参照グループ (Female) の差異の影響の値が 1 に近くなっています。
サポート ベクター マシン (SVM) モデルに学習させ、センシティブ属性の各グループについての統計的均一性差 (SPD) を計算します。非参照グループの SPD の値を小さくするために、観測値を分類するスコアのしきい値を調整します。
100 人の患者の医療情報を含む patients データ セットを読み込みます。変数 Gender と Smoker を categorical 変数に変換します。1 と 0 の代わりに、Smoker と Nonsmoker というわかりやすいカテゴリ名を指定します。
load patients Gender = categorical(Gender); Smoker = categorical(Smoker,logical([1 0]), ... ["Smoker","Nonsmoker"]);
連続予測子 Diastolic と Systolic を含む行列を作成します。センシティブ属性として Gender、応答変数として Smoker を指定します。
X = [Diastolic,Systolic]; attribute = Gender; Y = Smoker;
データを学習セットと検証セットに分割します。半分の観測値を学習に使用し、半分の観測値を検証に使用します。
rng("default") % For reproducibility cv = cvpartition(Y,"Holdout",0.5); trainX = X(training(cv),:); trainAttribute = attribute(training(cv)); trainY = Y(training(cv)); validationX = X(test(cv),:); validationAttribute = attribute(test(cv)); validationY = Y(test(cv));
学習データでサポート ベクター マシン (SVM) バイナリ分類器に学習させます。モデルを当てはめる前に予測子を標準化します。学習させたモデルを使用してラベルを予測し、検証データ セットのスコアを計算します。
mdl = fitcsvm(trainX,trainY,Standardize=true); [labels,scores] = predict(mdl,validationX);
検証データ セットについて、センシティブ属性と応答変数の情報を 1 つのグループ化変数 groupTest に結合します。
groupTest = validationAttribute.*validationY; names = string(categories(groupTest))
names = 4×1 string
"Female Smoker"
"Female Nonsmoker"
"Male Smoker"
"Male Nonsmoker"
SVM モデルで誤分類される検証観測値を見つけます。
wrongIdx = (validationY ~= labels);
wrongX = validationX(wrongIdx,:);
names(5) = "Misclassified";検証データをプロットします。各点の色は、その観測値のセンシティブ属性のグループとクラス ラベルを示します。円で囲まれた点は、誤分類された観測値を示します。
figure hold on gscatter(validationX(:,1),validationX(:,2), ... validationAttribute.*validationY) plot(wrongX(:,1),wrongX(:,2), ... "ko",MarkerSize=8) legend(names) xlabel("Diastolic") ylabel("Systolic") title("Validation Data") hold off
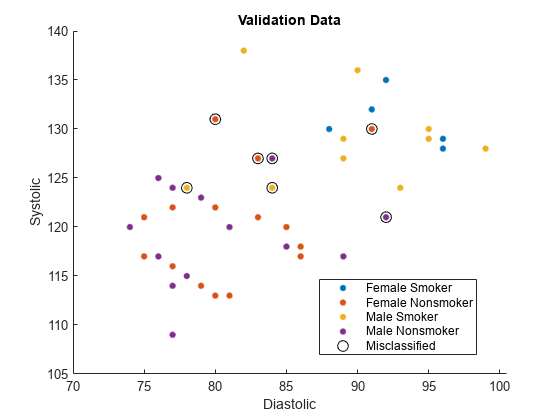
モデル予測を使用して、センシティブ属性についての公平性メトリクスを計算します。特に、validationAttribute の各グループについての統計的均一性差 (SPD) を調べます。
metricsResults = fairnessMetrics(validationAttribute,validationY, ...
Predictions=labels);
metricsResults.ReferenceGroupans = 'Female'
metricsResults.PositiveClass
ans = categorical
Nonsmoker
report(metricsResults,BiasMetrics="StatisticalParityDifference")ans=2×4 table
ModelNames SensitiveAttributeNames Groups StatisticalParityDifference
__________ _______________________ ______ ___________________________
Model1 x1 Female 0
Model1 x1 Male -0.064412
figure
plot(metricsResults,"StatisticalParityDifference")
SPD の値は、非参照グループ (Male) において、センシティブ属性の値が Male の場合に患者が陽性クラス (Nonsmoker) になる確率とセンシティブ属性の値が Female の場合に患者が陽性クラスになる確率 (参照グループでの確率) の差です。SPD の値は 0 に近くなるのが理想的です。
非参照グループの SPD の値が改善するか試すために、関数 fairnessThresholder を使用してモデル予測を調整できます。この関数は、公平性の範囲を満たしながら精度が最大になるように最適なスコアのしきい値を探します。最適なしきい値を下回る臨界領域の観測値については、参照グループと非参照グループで公平性の制約が保たれるように関数でラベルが変更されます。既定では、SPD のバイアス メトリクスを使用する場合、この関数は非参照グループの SPD の値が範囲 [–0.05,0.05] になるスコアのしきい値を見つけようとします。
fairnessMdl = fairnessThresholder(mdl,validationX, ... validationAttribute,validationY, ... BiasMetric="StatisticalParityDifference")
fairnessMdl =
fairnessThresholder with properties:
Learner: [1×1 classreg.learning.classif.CompactClassificationSVM]
SensitiveAttribute: [50×1 categorical]
ReferenceGroups: Female
ResponseName: 'Y'
PositiveClass: Nonsmoker
ScoreThreshold: 0.5116
BiasMetric: 'StatisticalParityDifference'
BiasMetricValue: -0.0209
BiasMetricRange: [-0.0500 0.0500]
ValidationLoss: 0.1200
fairnessMdl は fairnessThresholder モデル オブジェクトです。
更新後の方が非参照グループの SPD の値が 0 に近いことに注目してください。
newNonReferenceSPD = fairnessMdl.BiasMetricValue
newNonReferenceSPD = -0.0209
新しいスコアのしきい値を使用して検証データの予測を調整します。fairnessMdl オブジェクトの関数 predict で、最大スコアがスコアのしきい値より小さい各観測値の予測が調整されます。非参照グループの観測値の場合、関数はその観測値を陽性クラスに予測します。参照グループの観測値の場合、関数はその観測値を陰性クラスに予測します。これらの調整の結果として予測ラベルが常に変わるとは限りません。
fairnessLabels = predict(fairnessMdl,validationX, ...
validationAttribute);予測が fairnessMdl で切り替えられた観測値を見つけます。
differentIdx = (labels ~= fairnessLabels);
differentX = validationX(differentIdx,:);
names(5) = "Switched Prediction";検証データをプロットします。各点の色は、その観測値のセンシティブ属性のグループとクラス ラベルを示します。四角で囲まれた点は、ラベルが fairnessThresholder モデルで切り替えられた観測値を示します。
figure hold on gscatter(validationX(:,1),validationX(:,2), ... validationAttribute.*validationY) plot(differentX(:,1),differentX(:,2), ... "ks",MarkerSize=8) legend(names) xlabel("Diastolic") ylabel("Systolic") title("Validation Data") hold off

入力引数
出力引数
バージョン履歴
R2023a で導入