回帰学習器で学習させた SVM 回帰モデルからのインクリメンタル学習モデルの初期化
この例では、回帰学習器アプリを使用して線形 SVM 回帰モデルの調整と学習を行う方法を示します。その後、コマンド ラインで、アプリでの学習から得た情報を使用して、線形 SVM 回帰用のインクリメンタル モデルを初期化し、学習を行います。
データの読み込みと前処理
2015 年のニューヨーク市住宅データ セットを読み込み、データをシャッフルします。このデータの詳細については、NYC Open Data を参照してください。
load NYCHousing2015 rng(1); % For reproducibility n = size(NYCHousing2015,1); idxshuff = randsample(n,n); NYCHousing2015 = NYCHousing2015(idxshuff,:);
数値安定性を得るために、SALEPRICE を 1e6 の尺度でスケールします。
NYCHousing2015.SALEPRICE = NYCHousing2015.SALEPRICE/1e6;
線形 SVM 回帰モデルにデータの約 1% を学習させ、残りのデータをインクリメンタル学習用に予約するとします。
回帰学習器はカテゴリカル変数をサポートします。ただし、インクリメンタル学習用モデルにはダミー コード化されたカテゴリカル変数が必要です。変数 BUILDINGCLASSCATEGORY および変数 NEIGHBORHOOD に含まれる水準は種類が多い (件数が少ないものもある) ことから、区画内にすべてのカテゴリが含まれない可能性が高くなります。そのため、すべてのカテゴリカル変数をダミー コード化します。ダミー変数の行列を数値変数の残りに連結します。
catvars = ["BOROUGH" "BUILDINGCLASSCATEGORY" "NEIGHBORHOOD"]; dumvars = splitvars(varfun(@(x)dummyvar(categorical(x)),NYCHousing2015, ... 'InputVariables',catvars)); NYCHousing2015(:,catvars) = []; idxnum = varfun(@isnumeric,NYCHousing2015,'OutputFormat','uniform'); NYCHousing2015 = [dumvars NYCHousing2015(:,idxnum)];
cvpartition を呼び出し、0.99 のホールドアウト (テスト) 標本比率を指定して、データを無作為に 1% と 99% のサブセットに分割します。1% と 99% の区画用のテーブルを作成します。
cvp = cvpartition(n,'HoldOut',0.99);
idxtt = cvp.training;
idxil = cvp.test;
NYCHousing2015tt = NYCHousing2015(idxtt,:);
NYCHousing2015il = NYCHousing2015(idxil,:);
回帰学習器を使用したモデルの調整と学習
コマンド ラインに regressionLearner と入力して、回帰学習器を開きます。
regressionLearner
あるいは、[アプリ] タブで [さらに表示] 矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] でアプリのアイコンをクリックします。
学習データ セットと変数を選択します。
[回帰学習器] タブで、[ファイル] セクションの [新規セッション] を選択し、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のデータ セット [NYCHousing2015tt] を選択します。
[応答] で、応答変数 [SALEPRICE] が選択されていることを確認します。
[セッションの開始] をクリックします。
アプリは既定で 5 分割交差検証を実施します。
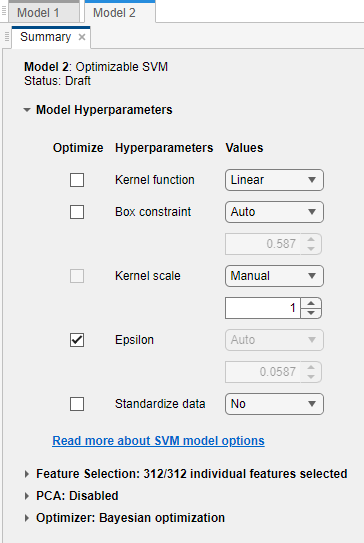
線形 SVM 回帰モデルを学習させます。ベイズ最適化を使用して [イプシロン] ハイパーパラメーターのみを調整します。
[回帰学習器] タブの [モデル] セクションで [さらに表示] 矢印をクリックしてアプリ ギャラリーを開きます。[サポート ベクター マシン] セクションで [最適化可能な SVM] をクリックします。
モデルの [概要] タブの [モデルのハイパーパラメーター] セクションで、次のようにします。
[イプシロン] を除くすべての使用可能なオプションの [最適化] ボックスの選択を解除します。
[カーネル スケール] の値を
[手動]および1に設定します。[データの標準化] の値を
[いいえ]に設定します。
[回帰学習器] タブの [学習] セクションで、[すべてを学習] をクリックして [選択を学習] を選択します。
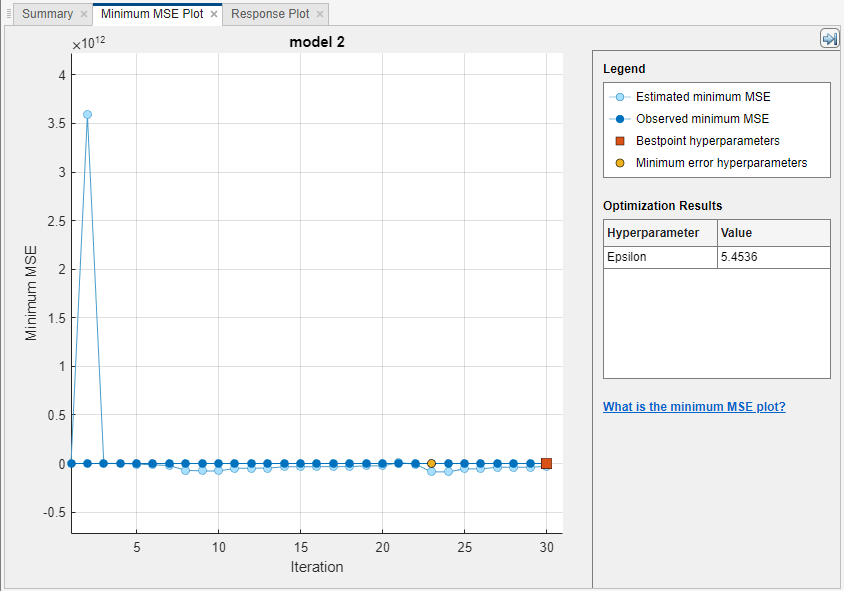
アプリは、最適化が進行するにしたがってモデルの汎化最小 MSE のプロットを表示します。アプリでアルゴリズムが最適化されるまでに時間がかかることがあります。
学習済みの最適化された線形 SVM 回帰モデルをエクスポートします。
[回帰学習器] タブの [エクスポート] セクションで [モデルのエクスポート] を選択し、[モデルのエクスポート] を選択します。
[モデルのエクスポート] ダイアログ ボックスで [OK] をクリックします。
アプリは、学習済みのモデルを構造体配列 trainedModel で他の変数と共にワークスペースに渡します。回帰学習器を閉じます。
エクスポートされたモデルのインクリメンタル モデルへの変換
コマンド ラインで、trainedModel から学習済みの SVM 回帰モデルを抽出します。
Mdl = trainedModel.RegressionSVM;
モデルをインクリメンタル モデルに変換します。
IncrementalMdl = incrementalLearner(Mdl) IncrementalMdl.Epsilon
IncrementalMdl =
incrementalRegressionLinear
IsWarm: 1
Metrics: [1×2 table]
ResponseTransform: 'none'
Beta: [312×1 double]
Bias: 12.3802
Learner: 'svm'
Properties, Methods
ans =
5.4536IncrementalMdl は、線形 SVM 回帰モデルを使用したインクリメンタル学習用の incrementalRegressionLinear モデル オブジェクトです。incrementalLearner は、Mdl から学習した Epsilon ハイパーパラメーターの係数および最適化された値を使用して、IncrementalMdl を初期化します。そのため、IncrementalMdl とデータを predict に渡すことで応答を予測できます。また、IsWarm プロパティは true です。つまり、インクリメンタル学習関数は、インクリメンタル学習の最初からモデルの性能を測定します。
インクリメンタル学習の実装
インクリメンタル学習関数は浮動小数点行列のみを受け入れるため、予測子と応答データの行列を作成します。
Xil = NYCHousing2015il{:,1:(end-1)};
Yil = NYCHousing2015il{:,end};関数 updateMetricsAndFit を使用して、99% のデータ区画でインクリメンタル学習を実行します。500 個の観測値を一度に処理して、データ ストリームをシミュレートします。各反復で次を行います。
updateMetricsAndFitを呼び出し、観測値の入力チャンクを所与として、モデルのイプシロン不感応損失の累積とウィンドウを更新します。前のインクリメンタル モデルを上書きして、Metricsプロパティ内の損失を更新します。損失と最後に推定された係数 β313 を保存します。
% Preallocation nil = sum(idxil); numObsPerChunk = 500; nchunk = floor(nil/numObsPerChunk); ei = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta313 = [IncrementalMdl.Beta(end); zeros(nchunk,1)]; % Incremental learning for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx)); ei{j,:} = IncrementalMdl.Metrics{"EpsilonInsensitiveLoss",:}; beta313(j + 1) = IncrementalMdl.Beta(end); end
IncrementalMdl は、ストリーム内のすべてのデータで学習させた incrementalRegressionLinear モデル オブジェクトです。
パフォーマンス メトリクスと推定された係数 β313 のトレース プロットをプロットします。
figure subplot(2,1,1) h = plot(ei.Variables); xlim([0 nchunk]) ylabel('Epsilon Insensitive Loss') legend(h,ei.Properties.VariableNames) subplot(2,1,2) plot(beta313) ylabel('\beta_{313}') xlim([0 nchunk]) xlabel('Iteration')

累積の損失は各反復 (500 個の観測値のチャンク) ごとに徐々に変化しますが、ウィンドウの損失には急な変動があります。メトリクス ウィンドウの既定値は 200 なので、updateMetricsAndFit は 500 個の観測値のチャンクごとに最新の 200 個の観測値に基づいて性能を測定します。
β313 は急激に変動した後、updateMetricsAndFit が観測値のチャンクを処理するたびに平坦になります。