margin
単純ベイズ分類器の分類マージン
説明
m = margin(Mdl,tbl,ResponseVarName)tbl に含まれている予測子データと tbl.ResponseVarName に含まれているクラス ラベルを使用して、学習済みの単純ベイズ分類器 Mdl の分類マージン (m) を返します。
例
単純ベイズ分類器のテスト標本分類マージンを推定します。観測マージンは、観測された真のクラスのスコアから、該当するクラスのすべてのスコアの中で最大の偽のクラスのスコアを差し引いたものです。
fisheriris データ セットを読み込みます。150 本のアヤメについて 4 つの測定値が含まれる数値行列 X を作成します。対応するアヤメの種類が含まれる文字ベクトルの cell 配列 Y を作成します。
load fisheriris X = meas; Y = species; rng('default') % for reproducibility
Y のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。テスト用の 30% のホールドアウト標本を指定します。
cv = cvpartition(Y,'HoldOut',0.30);学習インデックスとテスト インデックスを抽出します。
trainInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
予測子 XTrain とクラス ラベル YTrain を使用して、単純ベイズ分類器に学習させます。クラス名を指定することが推奨されます。fitcnb は、各予測子が条件付き正規分布に従うと仮定しています。
Mdl = fitcnb(XTrain,YTrain,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 105
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl は学習させた ClassificationNaiveBayes 分類器です。
テスト標本分類マージンを推定します。
m = margin(Mdl,XTest,YTest); median(m)
ans = 1.0000
テスト標本分類マージンのヒストグラムを表示します。
histogram(m,length(unique(m)),'Normalization','probability') xlabel('Test Sample Margins') ylabel('Probability') title('Probability Distribution of the Test Sample Margins')

分類器のマージンは比較的大きいことが推奨されます。
複数のモデルによるテスト標本マージンを比較することにより、特徴選択を実行します。この比較のみに基づくと、マージンが最大である分類器が最適なモデルです。
fisheriris データ セットを読み込みます。予測子 X とクラス ラベル Y を指定します。
load fisheriris X = meas; Y = species; rng('default') % for reproducibility
Y のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。テスト用の 30% のホールドアウト標本を指定します。cvPartition によりデータ セットの分割が定義されます。
cv = cvpartition(Y,'Holdout',0.30);学習インデックスとテスト インデックスを抽出します。
trainInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
次の 2 つのデータ セットを定義します。
fullXにはすべての予測子が含まれます。partXには最後の 2 つの予測子が含まれます。
fullX = XTrain; partX = XTrain(:,3:4);
各予測子セットの単純ベイズ分類器に学習させます。
fullMdl = fitcnb(fullX,YTrain); partMdl = fitcnb(partX,YTrain);
fullMdl および partMdl は学習済みの ClassificationNaiveBayes 分類器です。
分類器ごとにテスト標本マージンを推定します。
fullM = margin(fullMdl,XTest,YTest); median(fullM)
ans = 1.0000
partM = margin(partMdl,XTest(:,3:4),YTest); median(partM)
ans = 1.0000
箱ひげ図を使用してモデルごとのマージンの分布を表示します。
boxplot([fullM partM],'Labels',{'All Predictors','Two Predictors'}) ylim([0.98 1.01]) % Modify the y-axis limits to see the boxes title('Boxplots of Test Sample Margins')
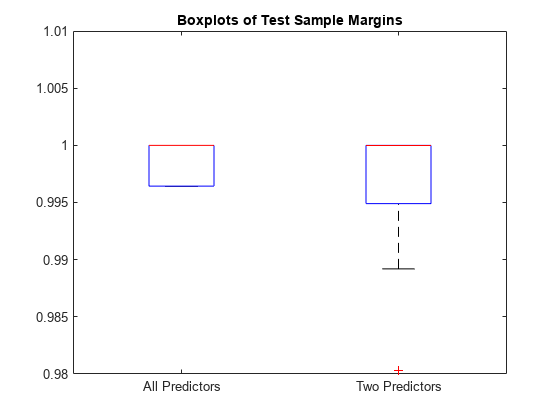
fullMdl (すべての予測子のモデル) および partMdl (2 つの予測子のモデル) のマージンは、同じ中央値で同様の分布を示しています。partMdl では複雑度が低減されますが、外れ値が存在しています。
入力引数
詳細
拡張機能
バージョン履歴
R2014b で導入