selectModels
クラス: ClassificationLinear
正則化されたバイナリ線形分類モデルのサブセットの選択
説明
入力引数
出力引数
例
ロジスティック回帰学習器を使用する線形分類モデルに適した LASSO ペナルティの強度を決定するため、テスト標本の分類誤差率を比較します。
NLP のデータ セットを読み込みます。カスタムな分類損失の指定で説明されているようにデータを前処理します。
load nlpdata Ystats = Y == 'stats'; X = X'; rng(10); % For reproducibility Partition = cvpartition(Ystats,'Holdout',0.30); testIdx = test(Partition); XTest = X(:,testIdx); YTest = Ystats(testIdx);
~ の範囲で対数間隔で配置された 11 個の正則化強度を作成します。
Lambda = logspace(-6,-0.5,11);
各正則化強度を使用するバイナリ線形分類モデルに学習をさせます。SpaRSA を使用して目的関数を最適化します。目的関数の勾配の許容誤差を 1e-8 に下げます。
CVMdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'CVPartition',Partition,'Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8)
CVMdl =
ClassificationPartitionedLinear
CrossValidatedModel: 'Linear'
ResponseName: 'Y'
NumObservations: 31572
KFold: 1
Partition: [1×1 cvpartition]
ClassNames: [0 1]
ScoreTransform: 'none'
Properties, Methods
学習済みの線形分類モデルを抽出します。
Mdl = CVMdl.Trained{1}Mdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'logit'
Beta: [34023×11 double]
Bias: [-12.1061 -12.1061 -12.1061 -12.1061 -12.1061 -6.2137 -5.0657 -4.2469 -3.4386 -3.2542 -2.9792]
Lambda: [1.0000e-06 3.5481e-06 1.2589e-05 4.4668e-05 1.5849e-04 5.6234e-04 0.0020 0.0071 0.0251 0.0891 0.3162]
Learner: 'logistic'
Properties, Methods
Mdl は ClassificationLinear モデル オブジェクトです。Lambda は正則化強度のシーケンスなので、Mdl はそれぞれが Lambda の各正則化強度に対応する 11 個のモデルであると考えることができます。
テスト標本の分類誤差を推定します。
ce = loss(Mdl,X(:,testIdx),Ystats(testIdx),'ObservationsIn','columns');
11 個の正則化強度があるので、ce は 1 行 11 列の分類誤差率のベクトルです。
Lambda の値が大きくなると、予測子変数がスパースになります。これは分類器の品質として優れています。データ セット全体を使用し、モデルの交差検証を行ったときと同じオプションを指定して、各正則化強度について線形分類モデルに学習をさせます。モデルごとに非ゼロの係数を特定します。
Mdl = fitclinear(X,Ystats,'ObservationsIn','columns',... 'Learner','logistic','Solver','sparsa','Regularization','lasso',... 'Lambda',Lambda,'GradientTolerance',1e-8); numNZCoeff = sum(Mdl.Beta~=0);
同じ図に、各正則化強度についてのテスト標本の誤差率と非ゼロ係数の頻度をプロットします。すべての変数を対数スケールでプロットします。
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(ce),... log10(Lambda),log10(numNZCoeff + 1)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} classification error') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') title('Test-Sample Statistics') hold off
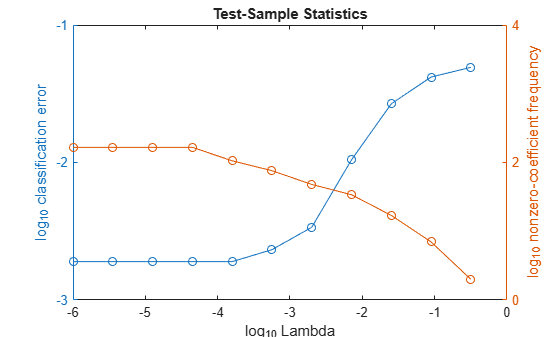
予測子変数のスパース性と分類誤差の低さのバランスがとれている正則化強度のインデックスを選択します。この場合、 ~ の値で十分なはずです。
idxFinal = 7;
選択した正則化強度のモデルを Mdl から選択します。
MdlFinal = selectModels(Mdl,idxFinal);
MdlFinal は、1 つの正則化強度が含まれている ClassificationLinear モデルです。新しい観測値のラベルを推定するには、MdlFinal と新しいデータを predict に渡します。
ヒント
複数のバイナリ線形分類予測モデルを構築する方法の 1 つに、次のようなものがあります。
データの一部をテスト用にホールドアウトします。
fitclinearを使用してバイナリ線形分類モデルに学習をさせます。名前と値のペアの引数'Lambda'を使用して正則化強度のグリッドを指定し、学習データを与えます。fitclinearは 1 つのClassificationLinearモデル オブジェクトを返しますが、これには各正則化強度に対するモデルが含まれています。各正則化モデルの品質を判断するため、返されたモデル オブジェクトとホールドアウトされたデータを
lossなどに渡します。満足できる正則化モデルのサブセットのインデックス (
idx) を識別し、返されたモデルとインデックスをselectModelsに渡します。selectModelsは 1 つのClassificationLinearモデル オブジェクトを返しますが、これにはnumel(idx)個の正則化モデルが含まれています。新しいデータのクラス ラベルを予測するため、データと正則化モデルのサブセットを
predictに渡します。