cgsl_0201: 冗長の Unit Delay ブロックと Memory ブロック
| ID: タイトル | cgsl_0201: 冗長の Unit Delay ブロックと Memory ブロック | ||
|---|---|---|---|
| 説明 | コード生成のためにモデルを準備する場合、以下に従ってください。 | ||
| A | 冗長の Unit Delay ブロックと Memory ブロックを削除する。 | ||
| 根拠 | A | 冗長の Unit Delay ブロックと Memory ブロックはグローバル メモリを余分に使用する。モデルから冗長性を除去すると、モデルの動作に影響することなくメモリ使用量を減らせる。 | |
| 最終更新 | R2013a | ||
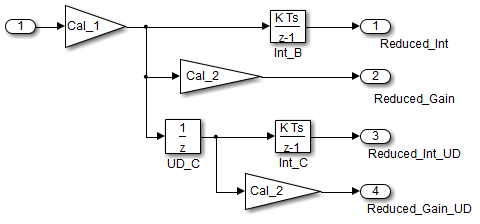
| 例 | 推奨: 統合 Unit Delays
void Reduced(void)
{
ConsolidatedState_2 = Matrix_UD_Test - (Cal_1 * DWork.UD_3_DSTATE + Cal_2 *
DWork.UD_3_DSTATE);
DWork.UD_3_DSTATE = ConsolidatedState_2;
} | ||
非推奨: 冗長 Unit Delays
void Redundant(void)
{
RedundantState = (Matrix_UD_Test - Cal_2 * DWork.UD_1B_DSTATE) - Cal_1 *
DWork.UD_1A_DSTATE;
DWork.UD_1B_DSTATE = RedundantState;
DWork.UD_1A_DSTATE = RedundantState;
} | |||
Unit Delay ブロックと Memory ブロックは、可換かつ配分的な代数プロパティを示します。ブロックが 1 つの駆動信号の計算式の一部である場合は、結果を変えずに、Unit Delay ブロックと Memory ブロックを計算式の新しい位置に移動できます。
前の例で一番上のパスの場合、ブロックの計算式は以下のようになります。
一番下のパスの場合、計算式は以下のようになります。
一方、計算式に第 2 の信号を加えた場合は、Unit Delay ブロックの位置が結果に影響します。次の例が示すように、上下のパス間の時間サンプルの歪みにより、Unit Delay ブロックの位置は結果に影響します。
ソースが 1 つで移動先が複数の場合、比較はさらに複雑になります。たとえば、次のモデルでは、2 つの Unit Delay ブロックを 1 つの Unit Delay にリファクタリングできます。
ブラック ボックスの視点からは、2 つのモデルは等価です。しかし、メモリと計算の視点からは、2 つのモデル間に差異があります。 {
real_T rtb_Gain4;
rtb_Gain4 = Cal_1 * Redundant;
Y.Redundant_Gain = Cal_2 * rtb_Gain4;
Y.Redundant_Int = DWork.Int_A;
Y.Redundant_Int_UD = DWork.UD_A;
Y.Redundant_Gain_UD = DWork.UD_B;
DWork.Int_A = 0.01 * rtb_Gain4 + DWork.Int_A;
DWork.UD_A = Y.Redundant_Int;
DWork.UD_B = Y.Redundant_Gain;
}{
real_T rtb_Gain1;
real_T rtb_UD_C;
rtb_Gain1 = Cal_1 * Reduced;
rtb_UD_C = DWork.UD_C;
Y.Reduced_Gain_UD = Cal_2 * DWork.UD_C;
Y.Reduced_Gain = Cal_2 * rtb_Gain1;
Y.Reduced_Int = DWork.Int_B;
Y.Reduced_Int_UD = DWork.Int_C;
DWork.UD_C = rtb_Gain1;
DWork.Int_B = 0.01 * rtb_Gain1 + DWork.Int_B;
DWork.Int_C = 0.01 * rtb_UD_C + DWork.Int_C;
}この場合は、最初のモデルの方が効率的です。最初のコード例では、3 つのグローバル変数、すなわち、Unit Delay ブロックから 2 つ (DWork.UD_A と DWork.UD_B)、離散時間積分器から 1 つ (DWork.Int_A) です。2 番目のコード例では、Unit Delay が生成するグローバル変数 1 つ (Dwork.UD_C) への削減を示していますが、冗長の Discrete Time Integrator ブロック (DWork.Int_B と DWork.Int_C) により、グローバル変数が 2 つあります。Discrete Time Integrator ブロックのパスによって、ローカル変数 1 つ (rtb_UD_C) と計算 2 つが追加で発生します。 それに対し、以下のリファクタリングしたモデル (2 番目) は効率的です。
{
real_T rtb_Gain4_f:
real_T rtb_Int_D;
rtb_Gain4_f = Cal_1 * U.Input;
rtb_Int_D = DWork.Int_D;
Y.R_Int_Out = DWork.UD_D;
Y.R_Gain_Out = DWork.UD_E;
DWork.Int_D = 0.01 * rtb_Gain4_f + DWork.Int_D;
DWork.UD_D = rtb_Int_D;
DWork.UD_E = Cal_2 * rtb_Gain4_f;
}{
real_T rtb_UD_F;
rtb_UD_F = DWork.UD_F;
Y.Gain_Out = Cal_2 * DWork.UD_F;
Y.Int_Out = DWork.Int_E;
DWork.UD_F = Cal_1 * U.Input;
DWork.Int_E = 0.01 * rtb_UD_F + DWork.Int_E;
}リファクタリングしたモデルのコードは、ルート信号の分岐に冗長の Unit Delay がないため、より効率的です。 | |||