std
標準偏差
構文
説明
S = std(A)A の要素の標準偏差を返します。既定では標準偏差が N-1 で正規化されます。N は観測値の数です。
Aが観測値のベクトルである場合、Sはスカラーです。Aが、列に確率変数をもち、行に観測値をもつ行列である場合、Sは各列に対応する標準偏差を含む行ベクトルになります。Aが多次元配列の場合、std(A)は、サイズが 1 でない最初の配列次元に沿って演算します。要素はベクトルとして扱われます。この次元におけるSのサイズは1になりますが、他のすべての次元のサイズはAと同じです。Aがスカラーの場合、Sは0です。Aが0行0列の空の配列である場合、SはNaNです。Aが table または timetable の場合、std(A)は、各変数の標準偏差を含む 1 行の table を返します。 (R2023a 以降)
S = std(___,missingflag)A の欠損値を含めるか省略するかを指定します。たとえば、std(A,"omitmissing") は標準偏差の計算時にすべての欠損値を無視します。既定では、std は欠損値を含めます。
例
入力引数
入力配列。ベクトル、行列、多次元配列、table または timetable として指定します。A がスカラーの場合、std(A) は 0 を返します。A が 0 行 0 列の空の配列である場合、std(A) は NaN を返します。
データ型: single | double | datetime | duration | table | timetable
複素数のサポート: あり
重み。次のいずれかの値に指定します。
0—N-1で正規化されます。ここで、Nは観測値の数です。観測値が 1 つだけの場合、重みは 1 になります。1—Nで正規化されます。標準偏差を計算する
Aの次元に対応する、非負のスカラー値の重みで構成されるベクトル。
データ型: single | double
演算の対象の次元。正の整数のスカラーとして指定します。次元を指定しない場合、既定値はサイズが 1 でない最初の配列次元です。
次元 dim は、長さが 1 に縮小した次元を示します。size(S,dim) は 1 ですが、他のすべての次元のサイズは変化しません。
m 行 n 列の入力行列 A を考えます。
std(A,0,1)は、Aの各列における要素の標準偏差を計算し、1行n列の行ベクトルを返します。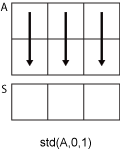
std(A,0,2)は、Aの各行における要素の標準偏差を計算し、m行1列の列ベクトルを返します。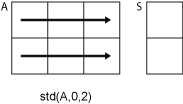
dim が ndims(A) よりも大きい場合、std(A) は A と同じサイズのゼロの配列を返します。
次元のベクトル。正の整数のベクトルとして指定します。各要素は入力配列の次元を表します。指定された操作次元の出力の長さは 1 で、その他は同じままです。
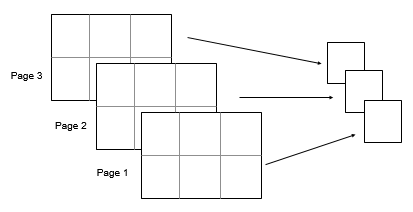
2×3×3 の入力配列 A を考えます。次に、std(A,0,[1 2]) は、要素が A の各ページに対して計算された標準偏差である 1×1×3 の配列を返します。
欠損値の条件。次の表の値のいずれかとして指定します。
| 値 | 入力データ型 | 説明 |
|---|---|---|
"includemissing" (R2023a 以降) | サポートされているすべてのデータ型 | 標準偏差の計算時に |
"includenan" | double, single, duration | |
"includenat" | datetime | |
"omitmissing" (R2023a 以降) | サポートされているすべてのデータ型 | A および w の欠損値を無視し、点の数を減らして標準偏差を計算します。操作次元のすべての要素がない場合、S の対応する要素がありません。 |
"omitnan" | double, single, duration | |
"omitnat" | datetime |