bfsearch
グラフの幅優先検索
構文
説明
例
グラフを作成してプロットします。
s = [1 1 1 1 2 2 2 2 2]; t = [3 5 4 2 6 10 7 9 8]; G = graph(s,t); plot(G)

ノード 2 からグラフの幅優先検索を実行します。結果はノードの検出順序を示します。
v = bfsearch(G,2)
v = 10×1
2
1
6
7
8
9
10
3
4
5
有向グラフを作成してプロットします。
s = [1 1 1 2 3 3 3 4 6]; t = [2 4 5 5 6 7 4 1 4]; G = digraph(s,t); plot(G)

ノード 1 からグラフの幅優先検索を実行します。'allevents' を指定して、アルゴリズムのすべてのイベントを含む table を返します。
T = bfsearch(G,1,'allevents')T=14×4 table
Event Node Edge EdgeIndex
________________ ____ __________ _________
startnode 1 NaN NaN NaN
discovernode 1 NaN NaN NaN
edgetonew NaN 1 2 1
discovernode 2 NaN NaN NaN
edgetonew NaN 1 4 2
discovernode 4 NaN NaN NaN
edgetonew NaN 1 5 3
discovernode 5 NaN NaN NaN
finishnode 1 NaN NaN NaN
edgetodiscovered NaN 2 5 4
finishnode 2 NaN NaN NaN
edgetofinished NaN 4 1 8
finishnode 4 NaN NaN NaN
finishnode 5 NaN NaN NaN
アルゴリズムのステップを追跡するには、テーブル内のイベントを上から下に読み取ります。以下に例を示します。
アルゴリズムがノード 1 で開始されます。
ノード 1 とノード 2 の間のエッジが検出されます。
ノード 2 が検出されます。
以下同様です。
複数の要素をもつグラフの幅優先検索を実行し、検索結果に基づいてグラフのノードおよびエッジを強調表示します。
有向グラフを作成してプロットします。このグラフには、弱連結要素が 2 つあります。
s = [1 1 2 2 2 3 4 7 8 8 8 8]; t = [3 4 7 5 6 2 6 2 9 10 11 12]; G = digraph(s,t); p = plot(G,'Layout','layered');
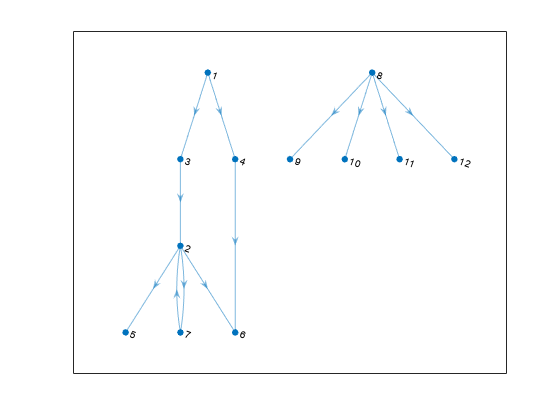
c = conncomp(G,'Type','weak')
c = 1×12
1 1 1 1 1 1 1 2 2 2 2 2
ノード 2 からグラフの幅優先検索を実行し、'edgetonew'、'edgetofinished' および 'startnode' のイベントにフラグを設定します。Restart を true に指定して、到達できないノードが残っている場合は必ず検索を再開します。
events = {'edgetonew','edgetofinished','startnode'};
T = bfsearch(G,2,events,'Restart',true)T=15×4 table
Event Node Edge EdgeIndex
______________ ____ __________ _________
startnode 2 NaN NaN NaN
edgetonew NaN 2 5 3
edgetonew NaN 2 6 4
edgetonew NaN 2 7 5
edgetofinished NaN 7 2 8
startnode 1 NaN NaN NaN
edgetonew NaN 1 3 1
edgetonew NaN 1 4 2
edgetofinished NaN 3 2 6
edgetofinished NaN 4 6 7
startnode 8 NaN NaN NaN
edgetonew NaN 8 9 9
edgetonew NaN 8 10 10
edgetonew NaN 8 11 11
edgetonew NaN 8 12 12
Restart が true の場合、'startnode' イベントはアルゴリズムが検索を再開する位置と時点に関する情報を返します。
イベントに基づいてグラフを強調表示します。
開始ノードを赤色にします。
緑のエッジは
'edgetonew'黒のエッジは
'edgetofinished'
highlight(p, 'Edges', T.EdgeIndex(T.Event == 'edgetonew'), 'EdgeColor', 'g') highlight(p, 'Edges', T.EdgeIndex(T.Event == 'edgetofinished'), 'EdgeColor', 'k') highlight(p,T.Node(~isnan(T.Node)),'NodeColor','r')

幅優先検索を使用してグラフが 2 部グラフかどうかを判定し、関連区画を返します。2 部グラフとは、グラフ内のノードを A および B の 2 セットに分割でき、グラフ内の各エッジが A のノードと B のノードを連結するグラフです。
有向グラフを作成してプロットします。
s = [1 1 1 1 2 2 4 5 6 7 8]; t = [2 3 6 8 5 10 6 6 10 3 10]; g = digraph(s,t); plot(g);

グラフの幅優先検索を使用して 2 部グラフかどうかを判定し、2 部グラフである場合は関連区画を返します。
events = {'edgetonew', 'edgetodiscovered', 'edgetofinished'};
T = bfsearch(g, 1, events, 'Restart', true);
partitions = false(1, numnodes(g));
is_bipart = true;
is_edgetonew = T.Event == 'edgetonew';
ed = T.Edge;
for ii=1:size(T, 1)
if is_edgetonew(ii)
partitions(ed(ii, 2)) = ~partitions(ed(ii, 1));
else
if partitions(ed(ii, 1)) == partitions(ed(ii, 2))
is_bipart = false;
break;
end
end
end
is_bipart
is_bipart = logical
1
g は 2 部グラフであるため、変数 partitions は各ノードが属する区画に関する情報を含みます。
'layered' レイアウトを指定し、変数 partitions を使用して 1 番目の層に現れるソース ノードを指定して、2 部グラフをプロットします。
partitions
partitions = 1×10 logical array
0 1 1 0 0 1 0 1 0 0
plot(g, 'Layout', 'layered', 'Source', find(partitions));

入力引数
出力引数
ヒント
dfsearchおよびbfsearchは有向グラフと無向グラフを同様に扱います。ノードsとノードtの間の無向エッジは、sからtへと、tからsへの双方向エッジと同様に扱われます。
アルゴリズム
幅優先検索アルゴリズムは開始ノード s から開始し、ノード インデックスの順序でその隣接ノードをすべて検査します。次に、それらの隣接ノードのそれぞれについて、順番に未訪問の隣接ノードを訪問します。開始ノードから到達可能なすべてのノードが訪問されるまで、アルゴリズムが継続します。
このアルゴリズムは、疑似コードで次のように記述できます。
Event startnode(S)
Event discovernode(S)
NodeList = {S}
WHILE NodeList is not empty
C = NodeList{1}
Remove first element from NodeList
FOR edge E from outgoing edges of node C, connecting to node N
Event edgetonew(C,E), edgetodiscovered(C,E) or edgetofinished(C,E)
(depending on the state of node N)
IF event was edgetonew
Event discovernode(N)
Append N to the end of NodeList
END
END
Event finishnode(C)
END
bfsearch は、新しいノードが検出された時点、あるノードから出るすべてのエッジが訪問された時点など、アルゴリズム内での異なるイベントを表すフラグを返すことができます。イベントのフラグを次の表に示します。
| イベントのフラグ | イベントの説明 |
|---|---|
'discovernode' | 新しいノードが検出されました。 |
'finishnode' | ノードから出るすべてのエッジが訪問されました。 |
'startnode' | このフラグは検索の開始ノードを示します。 |
'edgetonew' | エッジは未検出のノードに連結しています。 |
'edgetodiscovered' | エッジは以前検出したノードに連結しています。 |
'edgetofinished' | エッジは終了ノードに連結しています。 |
詳細は、events の入力引数の説明を参照してください。
メモ
開始ノードから到達できないノードが入力グラフに含まれている場合、'Restart' オプションにより検索でグラフ内の各ノードを訪問できます。この場合、'startnode' イベントは検索が再開されるたびに開始ノードを示します。
拡張機能
バージョン履歴
R2015b で導入