正規表現
このトピックでは、正規表現とは何か、そしてそれを使用してテキストを検索する方法について説明します。正規表現は柔軟で強力ですが、複雑な構文を使用します。正規表現の代替方法にpattern("R2020b" 以降) があり、これは定義がより簡単で、コードが読みやすくなります。詳細については、パターン表現の作成を参照してください。
正規表現とは
正規表現は、特定のパターンを定義する一連の文字です。通常、プログラム入力の解析やテキスト ブロックの処理を行う際などに、テキスト内でパターンに一致する単語のグループを検索するのに使用します。
文字ベクトル 'Joh?n\w*' は正規表現の一例です。この文字列は Jo で始まり、オプションで h ('h?' で示される部分) が続き、次に n が続き、任意の数の "単語文字" (アルファベット、数字またはアンダースコア。'\w*' で示される部分) で終わるパターンを定義しています。このパターンは、次のすべてに一致します。
Jon, John, Jonathan, Johnny
正規表現は、テキスト内で特定の文字のサブセットを検索する特殊な方法です。strfind などの関数で行うように、完全に一致する文字を探す代わりに、正規表現では、文字の特定の "パターン" を検索できます。
たとえば、メートル法の速度を表現する方法には以下があります。
km/h km/hr km/hour kilometers/hour kilometers per hour
5 つの別々の検索コマンドを発行することで、テキスト内で上述の用語を見つけることができます。
strfind(text, 'km/h'); strfind(text, 'km/hour'); % etc.
しかし、さらに効率的な方法は、これらすべての検索用語に適用できる 1 つのフレーズを作成することです。
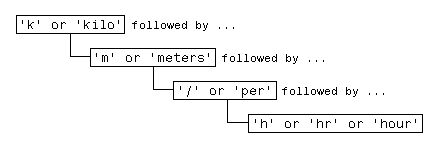
このフレーズを正規表現に変換すると (この節で後述)、次のようになります。
pattern = 'k(ilo)?m(eters)?(/|\sper\s)h(r|our)?';
これで、1 つのコマンドのみを使用して 1 つ以上の用語を見つけます。
text = ['The high-speed train traveled at 250 ', ... 'kilometers per hour alongside the automobile ', ... 'travelling at 120 km/h.']; regexp(text, pattern, 'match')
ans =
1×2 cell array
{'kilometers per hour'} {'km/h'}
正規表現による文字の検索と置換をサポートする MATLAB® 関数は、4 つあります。最初の 3 つは、受け入れる入力値、および返す出力値が同様です。詳細については、関数リファレンス ページのリンクをクリックしてください。
| 関数 | 説明 |
|---|---|
regexp | 正規表現と一致 |
regexpi | 大文字小文字を区別しない、正規表現の一致 |
regexprep | 正規表現を使用したテキストの一部の置き換え |
regexptranslate | テキストを正規表現に変換 |
最初の 3 つの関数のどれを呼び出す場合も、解析するテキストと正規表現を最初の 2 つの入力引数で渡します。regexprep を呼び出す場合は、置換のパターンを指定する式を追加の入力として渡します。
式の作成手順
テキストで特定の用語を検索するために正規表現を使用するには次の 3 つ手順に従います。
この節で示す例では、友達 5 人のグループに所属する連絡先情報を含むレコードを検索します。この情報には、各自の名前、電話番号、居住地、電子メール アドレスが含まれます。目的は、テキストから特定の情報を抽出することです。
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
例の最初の部分では、標準の電子メール アドレスの形式を表す正規表現を作成します。この表現を使用して、友達のグループの 1 人の電子メール アドレス情報を検索します。Janice の連絡先情報は cell 配列 contacts の 2 行目にあります。
contacts{2}
ans =
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'
手順 1 — テキストに固有のパターンを識別する
一般的な電子メール アドレスは次の標準的な構成要素から構成されます。ユーザーのアカウント名に続き、@ 記号、ユーザーの ISP (インターネット サービス プロバイダー) の名前、ドット (ピリオド)、ISP が属するドメインで構成されます。次の表では、左の列にこれらのコンポーネントを、右の欄に各コンポーネントの形式を一般化してまとめています。
| 電子メール アドレスに固有のパターン | 各パターンの一般的な説明 |
|---|---|
アカウント名で始まるjan_stephens . . . | 1 つ以上の小文字とアンダースコア |
'@' を追加するjan_stephens@ . . . | @ 記号 |
ISP を追加するjan_stephens@horizon . . . | 1 つ以上の小文字。アンダースコアなし |
ドット (ピリオド) を追加するjan_stephens@horizon. . . . | ドット (ピリオド) 文字 |
ドメインで終わるjan_stephens@horizon.net | com または net |
手順 2 — 正規表現として各パターンを表現する
この手順では、手順 1 で作成した一般的な形式を正規表現のセグメントに変換します。次にそれらのセグメントを結合して表現全体を形成します。
次の表では、左の欄に一般化した形式の説明をまとめています(これは、手順 1 の表の右の欄から取り込んだものです)。2 番目の欄は、文字パターンを表す演算子またはメタ文字を示しています。
| 各セグメントの説明 | パターン |
|---|---|
| 1 つ以上の小文字とアンダースコア | [a-z_]+ |
@ 記号 | @ |
| 1 つ以上の小文字。アンダースコアなし | [a-z]+ |
| ドット (ピリオド) 文字 | \. |
com または net | (com|net) |
これらのパターンを 1 つの文字ベクトルに組み立てて、次のような式を完成します。
email = '[a-z_]+@[a-z]+\.(com|net)';
手順 3 — 適切な検索関数を呼び出す
この手順では、手順 2 で作成した正規表現を使用して、グループに属する友達の 1 人の電子メール アドレスを一致させます。この検索は、関数 regexp を使用して行います。
この節で前述した連絡先情報のリストは次のとおりです。各メンバーのレコードは、cell 配列 contacts の 1 行を占めています。
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
次に手順 2 で作成した電子メール アドレスを表す正規表現を示します。
email = '[a-z_]+@[a-z]+\.(com|net)';
関数 regexp を呼び出し、cell 配列 contacts の 2 行目と正規表現 email を渡すと、Janice の電子メール アドレスが返されます。
regexp(contacts{2}, email, 'match')
ans =
1×1 cell array
{'jan_stephens@horizon.net'}
MATLAB では、文字ベクトルは左から右へと解析され、解析の進行と同時にベクトルが処理済みになっていきます。一致する文字が見つかると、regexp でその場所が記録され、最後に一致した文字の直後から文字ベクトルの解析が再開されます。
今度はリストの 5 番目のメンバーについて同じ呼び出しを行います。
regexp(contacts{5}, email, 'match')
ans =
1×1 cell array
{'jason_blake@mymail.com'}
さらに、入力引数の cell 配列全体を使用すると、リスト内の全員の電子メール アドレスを検索することもできます。
regexp(contacts, email, 'match');
演算子と文字
以下の節で説明があるように、正規表現には、一致するパターンを指定する文字、メタ文字、演算子、トークンおよびフラグを含めることができます。
メタ文字
メタ文字は、文字、文字の範囲、数字および空白文字を表します。メタ文字を使用して文字の汎用パターンを構築します。
メタ文字 | 説明 | 例 |
|---|---|---|
| 空白を含む任意の単一文字 |
|
| 大かっこ内の任意の文字。次の文字は文字どおり扱われます。 |
|
| 大かっこ内を除く任意の文字。次の文字は文字どおり扱われます。 |
|
|
|
|
| アルファベット、数字またはアンダースコア文字。英語の文字セットでは、 |
|
| アルファベット、数字またはアンダースコア以外の任意の文字。英語の文字セットでは、 |
|
| 任意の空白文字。 |
|
| 任意の空白文字以外の文字。 |
|
| 任意の数字。 |
|
| 任意の数字以外の文字。 |
|
| 8 進数値 |
|
| 16 進数値 |
|
文字表現
演算子 | 説明 |
|---|---|
| アラーム (ビープ) |
| バックスペース |
| フォーム フィード |
| 改行 |
| キャリッジ リターン |
| 水平タブ |
| 垂直タブ |
| 正規表現で特別な意味をもつ文字を、リテラルとして一致させる文字 (たとえば、 |
量指定子
量指定子は、一致するテキスト内でパターンが発生しなければならない回数を指定します。
量指定子 | 表現の出現回数 | 例 |
|---|---|---|
| 0 回以上の繰り返し。 |
|
| 0 回または 1 回。 |
|
| 1 回以上の繰り返し。 |
|
|
|
|
|
|
|
| 正確に
|
|
量指定子は次の表に示すように、3 つのモードで表示できます。q は前の表の任意の量指定子を表します。
モード | 説明 | 例 |
|---|---|---|
| 最長一致表現。できるだけ多くの文字と一致します。 | たとえば、テキスト |
| 最短一致表現。できるだけ少ない文字と一致します。 | たとえば、テキスト |
| 独占的表現。できる限り多く一致しますが、テキスト部分の再スキャンは実行しません。 | たとえば、テキスト |
グループ化演算子
グループ化演算子を使用すると、トークンをキャプチャしたり、1 つの演算子を複数の要素に適用したり、特定のグループ内のバックトラッキングを無効にすることができます。
グループ化演算子 | 説明 | 例 |
|---|---|---|
| 式の要素をグループ化し、トークンをキャプチャします。 |
|
| グループ化はしますが、トークンはキャプチャしません。 |
グループ化を使用しない場合、 |
| アトミックにグループ化します。一致を検索するためにグループ内のバックトラッキングを実行せず、トークンをキャプチャしません。 |
|
| 式
左小かっこの後に |
|
アンカー
式内のアンカーは、文字ベクトルまたは単語の最初または最後と一致します。
アンカー | 一致対象 | 例 |
|---|---|---|
| 入力テキストの最初。 |
|
| 入力テキストの最後。 |
|
| 単語の最初。 |
|
| 単語の最後。 |
|
前後参照アサーション
前後参照アサーションは、目的の一致の直前または直後のパターン (一致の一部ではない) を検索します。
ポインターは現在の位置のままで、test 式に対応する文字はキャプチャも破棄もされません。このため、前方参照アサーションは、オーバーラップしている文字グループと一致することがあります。
前後参照アサーション | 説明 | 例 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
式の "前に" 前方アサーションを指定する場合、演算は論理 AND と等価になります。
演算 | 説明 | 例 |
|---|---|---|
|
|
|
|
|
|
詳細については、正規表現における先読みアサーションを参照してください。
論理演算子と条件付き演算子
論理演算子と条件演算子を使用すると、特定の条件の状態をテストし、その結果を使用して次に一致するパターン (ある場合) を決定できます。これらの演算子は、論理 OR および if または if/else 条件をサポートします(AND 条件については、前後参照アサーションを参照してください)。
条件には、トークン、前後参照アサーションまたは (?@cmd) 形式の動的表現を使用できます。動的表現は、論理値または数値を返さなければなりません。
条件演算子 | 説明 | 例 |
|---|---|---|
| 式
|
|
| 条件 | Windows® システムで実行する場合、 |
| 条件 |
|
トークン演算子
トークンは正規表現の一部をかっこで囲んで定義した、一致テキストの一部です。テキスト内のシーケンスによってトークンを参照することも (順序トークン)、コードの保守を簡単にしたり、出力を読み取りやすくしたりするために、トークンに名前を割り当てることもできます。
順序トークン演算子 | 説明 | 例 |
|---|---|---|
| かっこで囲まれた式と一致する文字をトークンでキャプチャします。 |
|
|
|
|
|
|
|
名前付きトークン演算子 | 説明 | 例 |
|---|---|---|
| かっこで囲まれた式と一致する文字を名前付きトークンでキャプチャします。 |
|
|
|
|
| 名前付きトークンが見つかった場合は |
|
メモ
式に入れ子にされたかっこがある場合、MATLAB は一番外側のかっこのペアに対応するトークンをキャプチャします。たとえば '(and(y|rew))' という検索パターンの場合、MATLAB は 'andrew' に対するトークンを作成しますが、'y' や 'rew' に対するトークンは作成しません。
詳細については、正規表現におけるトークンを参照してください。
動的表現
動的表現を使用すると、MATLAB コマンドまたは正規表現を実行して一致するテキストを特定できます。
動的表現を囲む小かっこでは、キャプチャするグループを "作成しません"。
演算子 | 説明 | 例 |
|---|---|---|
|
解析時、 |
|
|
|
|
|
|
|
動的表現内では、次の演算子を使って置換語句を定義します。
置換演算子 | 説明 |
|---|---|
| 入力テキストの現在の一致部分 |
| 入力テキストの現在の一致の前にある部分 |
| 入力テキストの現在の一致の後にある部分 ( |
|
|
| 名前付きトークン |
| MATLAB で |
詳細については、動的正規表現を参照してください。
コメント
comment 演算子では、コードを管理しやすくするために、コメントを挿入できます。コメントのテキストは、入力テキストで一致を検索する際には、MATLAB によって無視されます。
文字 | 説明 | 例 |
|---|---|---|
(?#comment) | 正規表現にコメントを挿入します。コメントのテキストは、入力の検索時に無視されます。 |
|
検索フラグ
検索フラグは、一致する式の動作を変更します。
フラグ | 説明 |
|---|---|
(?-i) | 大文字と小文字を区別します。 |
(?i) | 大文字と小文字を区別しません。 |
(?s) | パターン内のドット ( |
(?-s) | パターン内のドットを改行文字以外の任意の文字と一致させます。 |
(?-m) | テキストの始めと終わりで |
(?m) | 行の始めと終わりで |
(?-x) | 検索時に空白文字とコメントを含めます (既定)。 |
(?x) | 検索時に空白文字とコメントを無視します。空白文字と |
フラグによって修正される式は、かっこの後に
(?i)\w*
のように表示されるか、かっこの中に表示でき、次のようにコロン (:) を使ってフラグから切り離すことができます。
(?i:\w*)
後者の構文を使用すると、大きな式の部分の動作を変更できます。
参考
regexp | regexpi | regexprep | regexptranslate | pattern