pcmatchfeatures
点群の間の一致する特徴を検出
構文
説明
indexPairs = pcmatchfeatures(features1,features2)
[ は、前述の構文の任意の入力引数の組み合わせを使用して、一致する特徴の間の正規化されたユークリッド距離を返します。indexPairs,scores] = pcmatchfeatures(___)
[___] = pcmatchfeatures(___, は、前述の構文の任意の引数の組み合わせに加え、1 つ以上の名前と値のペアの引数を使用してオプションを指定します。たとえば、Name,Value)'MatchThreshold',0.03 は、一致する特徴についての正規化された距離のしきい値を 0.03 に設定します。
例
MAT ファイルから点群データを読み込みます。
ld = load("livingRoom.mat");
ptCloud1 = ld.livingRoomData{1};
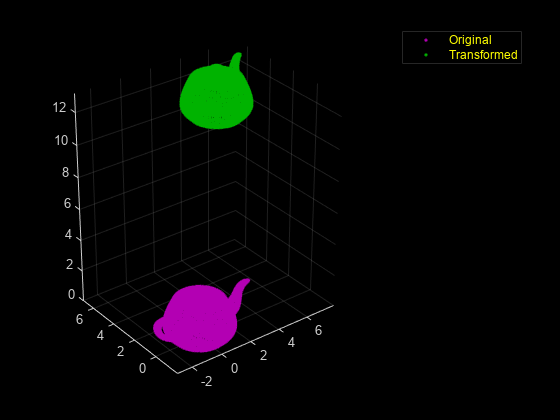
ptCloud2 = ld.livingRoomData{2};読み込まれた点群を可視化します。
figure pcshowpair(ptCloud1,ptCloud2)
点群をダウンサンプリングします。
gridSize = 0.05; ptCloud1 = pcdownsample(ptCloud1,"gridNearest",gridSize); ptCloud2 = pcdownsample(ptCloud2,"gridNearest",gridSize);
各点群の特徴を検出します。
features1 = extractFPFHFeatures(ptCloud1); features2 = extractFPFHFeatures(ptCloud2);
一致する特徴を検出します。
indexPairs = pcmatchfeatures(features1,features2,ptCloud1,ptCloud2);
一致した点を選択します。
matchedPoints1 = select(ptCloud1,indexPairs(:,1)); matchedPoints2 = select(ptCloud2,indexPairs(:,2));
一致した特徴を可視化します。
figure
pcshowMatchedFeatures(ptCloud1,ptCloud2,matchedPoints1,matchedPoints2,Method="montage")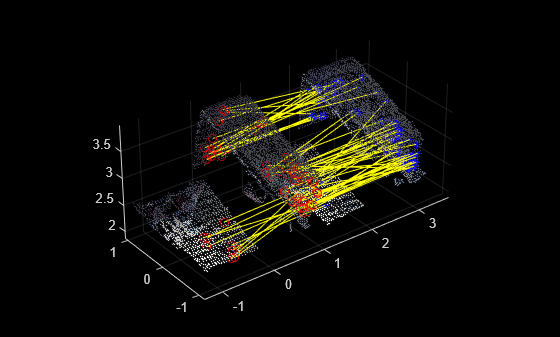
入力引数
名前と値の引数
出力引数
参照
[1] Muja, Marius and David G. Lowe. "Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration." In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications, 331-40. Lisboa, Portugal: SciTePress - Science and Technology Publications, 2009. https://doi.org/10.5220/0001787803310340.
[2] Zhou, Qian-Yi, Jaesik Park, and Vladlen Koltun. "Fast global registration." In European Conference on Computer Vision, pp. 766-782. Springer, Cham, 2016.