HDL フィルター アーキテクチャ
フィルター設計を実現するときに速度と面積のトレードオフをよりよくコントロールできるように、HDL Coder™ ソフトウェアにはアーキテクチャのオプションが用意されています。生成される HDL コードで目的のトレードオフを達成するには、完全なパラレル アーキテクチャを指定するか、いくつかのシリアル アーキテクチャの 1 つを選択することができます。シリアル アーキテクチャを構成するには、SerialPartitionおよびReuseAccumのパラメーターを使用します。スループット向上のためにフレームベース フィルターを選択することもできます。
フィルター設計の速度パフォーマンスを向上させるには、パイプライン パラメーターを使用します。スカラー入力フィルターの場合、AddPipelineRegisters、フレームベース フィルターの場合、AdderTreePipelineを使用して、フィルターの加算器ロジックにパイプラインを追加します。MultiplierInputPipeline と MultiplierOutputPipeline を使用して、各乗算器の前と後にパイプライン ステージを指定します。InputPipelineとOutputPipelineを使用して、フィルターの前と後のパイプライン ステージの数を設定します。設定可能なさまざまなパイプライン ステージの位置をアーキテクチャ図に示します。
完全なパラレル アーキテクチャ
このオプションは既定のアーキテクチャです。完全なパラレル アーキテクチャでは、各フィルター タップで専用の乗算器と加算器を使用します。タップは並列で実行されます。完全なパラレル アーキテクチャは速度に対して最適化されています。ただし、シリアル アーキテクチャよりもより多くの乗算器と加算器を必要とするため、より多くのチップ面積を消費します。完全なパラレル実装による直接型フィルター構造と転置フィルター構造のアーキテクチャと、構成可能なパイプライン ステージの位置を図に示します。
直接型

既定では、このブロックには線形加算器ロジックが実装されます。AddPipelineRegisters を有効にすると、加算器ロジックがパイプライン化された加算器ツリーとして実装されます。加算器ツリーには、完全精度のデータ型が使用されます。検証モデルを生成する場合、検証時の不一致を避けるため、元のモデルで完全精度を使用しなければなりません。
転置構成
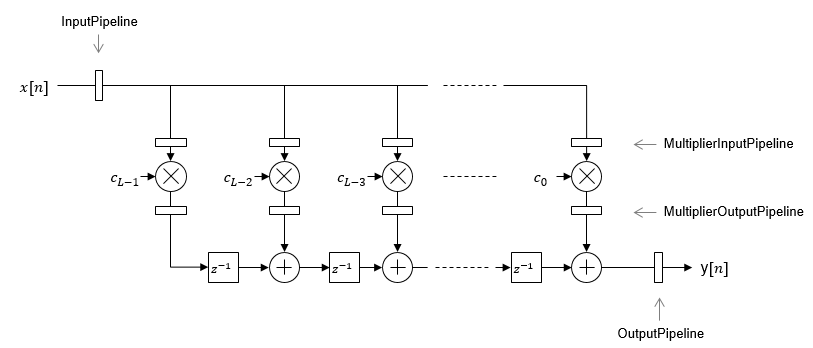
AddPipelineRegisters パラメーターは、転置フィルター実装には影響しません。
シリアル アーキテクチャ
シリアル アーキテクチャではハードウェア リソースを時間内で再利用し、チップ面積を節約します。シリアル アーキテクチャを構成するには、SerialPartitionおよびReuseAccumのパラメーターを使用します。使用可能なシリアル アーキテクチャのオプションは、"完全なシリアル"、"部分的なシリアル"、"カスケード シリアル" です。
完全なシリアル
完全なシリアル アーキテクチャは乗算器と加算器リソースを順番に再利用することで面積を節約します。たとえば、4 タップ フィルターの設計は単一の乗算器と加算器を使用し、タップごとに積和演算を 1 回実行します。設計の積和セクションはフィルターの入出力サンプル レートの 4 倍で実行されます。このように設計することで、多少速度が低下し、より多くの電力を消費しながらも、面積を節約できます。
完全なシリアル アーキテクチャでは、システム クロックはフィルターのサンプル レートに比べより高いレートで実行されます。したがって、あるフィルター設計では、完全なシリアル アーキテクチャで達成可能な最大速度はパラレル アーキテクチャよりも低くなります。
部分的なシリアル
部分的なシリアル アーキテクチャは、完全なパラレルおよび完全なシリアル アーキテクチャ間に存在する速度と面積のあらゆるトレードオフに対応します。
部分的なシリアル アーキテクチャでは、フィルター タップは多くのシリアル パーティションにグループ化されます。各パーティション内のタップは連続して実行されますが、パーティションは互いに並行して実行されます。パーティションの出力は最終出力で合計されます。
部分的なシリアル アーキテクチャを選択する場合、パーティションの数と長さ (タップ数) をパーティションごとに指定します。たとえば 4 タップ フィルターに、それぞれ 2 つのタップをもつ 2 つのパーティションを指定するとします。システム クロックはフィルターのサンプル レートの 2 倍で実行されます。
カスケード シリアル
カスケード シリアル アーキテクチャは部分的なシリアル アーキテクチャによく似ています。部分的なシリアル アーキテクチャと同様に、フィルター タップは互いに並行して実行される多くのシリアル パーティションにグループ化されます。ただし、各パーティションの累計された出力は直前のパーティションのアキュムレータに渡されます。したがって、すべてのパーティションの出力は最初のパーティションのアキュムレータで計算されます。この手法は "アキュムレータの再利用" と呼ばれます。最後の加算器を必要とせず、面積を節約します。
カスケード シリアル アーキテクチャでは、出力への最後の総和の計算を完了するためにシステム クロックで追加の 1 サイクルを必要とします。したがって、システム クロックの周波数は非カスケードの部分的なシリアル アーキテクチャで使用されるクロックに対して多少増やさなければなりません。
カスケードシリアル アーキテクチャを生成するには、アキュムレータの再利用を有効にした部分的なシリアル アーキテクチャを指定します。シリアル パーティションを指定しない場合、HDL Coder では最適な分割が自動的に選択されます。
シリアル アーキテクチャ内のレイテンシ
フィルターのシリアル化は、設計の合計レイテンシを 1 クロック サイクル増加させます。シリアル アーキテクチャは、積を順次追加するためにアキュムレータ (レジスタをもつ加算器) を使用します。すべてのシリアル パーティションの合計結果を保管するために追加の最終レジスタが使用されるので、処理に 1 クロック サイクルの追加が必要になります。このレイテンシをモデル化するために、HDL Coder は、生成されるモデルのフィルター ブロックの後に Delay ブロックを挿入します。
シリアル アーキテクチャの完全精度
シリアル アーキテクチャを選択すると、コード ジェネレーターは完全精度で HDL コードを生成します。したがって、HDL Coder で生成されるモデルも強制的に完全精度になります。検証モデルを生成する場合、検証時の不一致を避けるため、元のモデルで完全精度を使用しなければなりません。
フレームベース アーキテクチャ
フレームベース アーキテクチャを選択し、M サンプルの入力フレームを指定すると、完全にパラレルなフィルター アーキテクチャがコード ジェネレーターで実装されます。このフィルターには、入力サンプル 1 つにつき M 個のパラレル サブフィルターが含まれます。
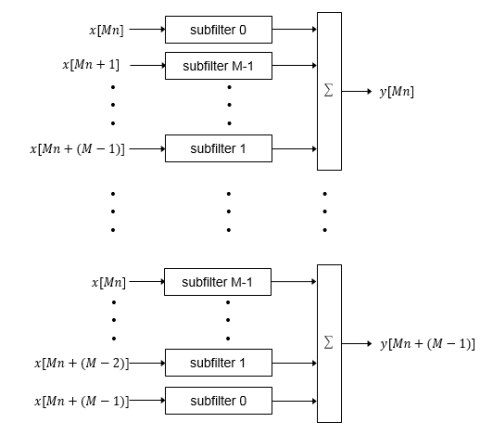
各サブフィルターには、M 個目ごとの係数が含まれます。サブフィルターの結果が加算され、各係数の総和を 1 つの入力サンプルに乗算したものが、それぞれの出力サンプルになります。
| サブフィルター | 係数 |
|---|---|
| 0 | c0,cM, ... |
| 1 | ca,cM+1, ... |
| M–1 | cM–1,c2M–1, ... |
次の図は、フレーム サイズが 2 サンプル (M = 2) のフィルター アーキテクチャと、6 つの係数のフィルター長を示しています。入力は 2 つの値をもつベクトルで、サンプルを時間で表しています。入力サンプル x[2n] および x[2n+1] は、n 番目の入力ペアです。各ストリームのサンプルは 1 つおきに、2 つのパラレル サブフィルターに送られます。これら 4 つのサブフィルターの結果が合計され、2 つの出力サンプルが生成されます。このように、各出力サンプルは、各係数の総和に、入力サンプルの 1 つを乗算したものになります。
これらの総和は、パイプライン化された加算器ツリーとして実装されます。AdderTreePipelineを設定すると、加算器ツリーのレベル間のパイプライン ステージ数を指定できます。クロック速度を向上させるには、このパラメーターを 2 に設定することを推奨します。実際の FPGA の DSP ブロックにこれらの乗算器をフィッティングするには、MultiplierInputPipeline と MultiplierOutputPipeline を使用して、乗算器の前と後にパイプライン ステージを追加します。

対称または非対称の係数については、フィルター アーキテクチャは係数乗算器を再利用するため、必要に応じて、乗算器ステージと総和ステージの間に設計上の遅延が追加されます。