このページは機械翻訳を使用して翻訳されました。最新版の英語を参照するには、ここをクリックします。
遺伝的アルゴリズムの仕組み
アルゴリズムの概要
遺伝的アルゴリズムの仕組みを以下にまとめます。
アルゴリズムはランダムな初期母集団を作成することから始まります。
次に、アルゴリズムは一連の新しい母集団を作成します。各ステップで、アルゴリズムは現在の世代の個体を使用して次の母集団を作成します。新しい母集団を作成するために、アルゴリズムは次の手順を実行します。
適応度値を計算して、現在の母集団の各メンバーにスコアを付けます。これらの値は生の適応度スコアと呼ばれます。
生の適応度のスコアをスケーリングして、より使いやすい範囲の値に変換します。これらのスケールされた値は期待値と呼ばれます。
期待に基づいて、親と呼ばれるメンバーを選択します。
現在の母集団の中で適応度が低い個体の一部が エリート として選択されます。これらのエリート個体は次の母集団に引き継がれます。
親から子を生成します。子は、単一の親にランダムな変更を加えることによって(突然変異)、または一対の親のベクトルエントリを組み合わせることによって(交叉)生成されます。
現在の母集団を子に置き換えて、次の世代を形成します。
停止基準の 1 つが満たされると、アルゴリズムは停止します。アルゴリズムの停止条件を参照してください。
アルゴリズムは線形制約と整数制約に対して修正された手順を実行します。整数制約と線形制約を参照してください。
アルゴリズムは非線形制約に合わせてさらに変更されます。遺伝的アルゴリズムのための非線形制約ソルバーアルゴリズムを参照してください。
初期母集団
アルゴリズムは、次の図に示すように、ランダムな初期母集団を作成することから始まります。
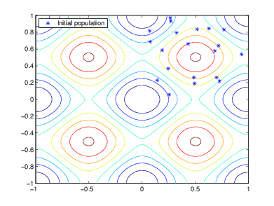
この例では、初期母集団には 20個体が含まれています。初期母集団のすべての個体は図の右上の象限に位置し、つまり、その座標は 0 から 1 の間にあることに注意してください。この例では、InitialPopulationRange オプションは [0;1] です。
関数の最小点がおおよそどこにあるかわかっている場合は、その点がその範囲の中央付近になるように InitialPopulationRange を設定する必要があります。たとえば、Rastrigin 関数の最小点が点 [0 0] の近くにあると考えられる場合、InitialPopulationRange を [-1;1] に設定できます。ただし、この例が示すように、遺伝的アルゴリズムでは、InitialPopulationRange の選択が最適ではない場合でも最小値を見つけることができます。
新しい世代の作成
各ステップで、遺伝的アルゴリズムは現在の母集団を使用して、次の世代を構成する子を作成します。アルゴリズムは、現在の母集団内の 親 と呼ばれる個体のグループを選択します。親は、自分の 遺伝子 (ベクトルのエントリ) を子に提供します。アルゴリズムは通常、より優れた適応度値を持つ個体を親として選択します。SelectionFcn オプションで、アルゴリズムが親を選択するために使用する関数を指定できます。選択オプションを参照してください。
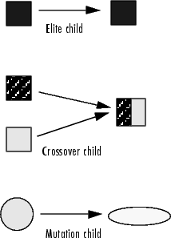
遺伝的アルゴリズムは、次の世代のために 3 種類の子を作成します。
エリートの子は、現在の世代の中で最適な適応度値を持つ個体です。これらの個体は自動的に次の世代まで生き残ります。
交叉 子は、一対の親のベクトルを組み合わせることによって作成されます。
突然変異 子は、単一の親にランダムな変更、つまり突然変異を導入することによって作成されます。
次の図は、3 種類の子を示しています。
突然変異と交叉 では、アルゴリズムが生成する各タイプの子の数を指定する方法と、交叉と突然変異を実行するために使用する関数について説明します。
次のセクションでは、アルゴリズムが交叉と突然変異の子を作成する方法について説明します。
交叉チルドレン
アルゴリズムは、現在の母集団内の親のペアを組み合わせることで交叉子を作成します。子ベクトルの各座標では、デフォルトの交叉関数により、2 つの親のいずれかから同じ座標にあるエントリ、つまり 遺伝子 がランダムに選択され、子に割り当てます。線形制約のある問題の場合、デフォルトの交叉関数は、親のランダムな加重平均として子を作成します。
突然変異による子
このアルゴリズムは、個体の親の遺伝子をランダムに変更することで突然変異の子を作成します。デフォルトでは、制約のない問題の場合、アルゴリズムはガウス分布からのランダムベクトルを親に追加します。境界付きまたは線形制約のある問題の場合、子は実行可能なままです。
次の図は、初期母集団の子、つまり第 2世代の母集団を示しており、それらがエリート、交叉、または突然変異の子であるかどうかを示しています。
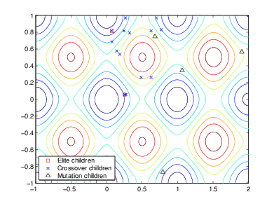
世代の陰謀
次の図は、反復 60、80、95、および 100 における母集団を示しています。
|
|
|
|
|
|
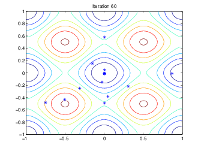
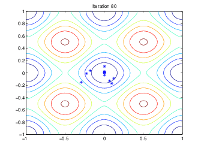
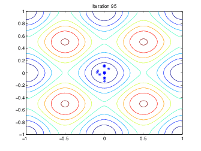
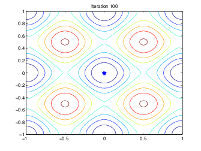
世代数が増えるにつれて、母集団内の個体は互いに近づき、最小点 [0 0] に近づきます。
アルゴリズムの停止条件
遺伝的アルゴリズムは、次のオプションを使用して停止するタイミングを決定します。opts = optimoptions('ga') を実行して各オプションのデフォルト値を確認してください。
MaxGenerations—世代数がMaxGenerationsに達するとアルゴリズムは停止します。MaxTime— アルゴリズムは、MaxTimeに等しい秒数の実行後に停止します。FitnessLimit—現在の母集団内の最適な点の適応度関数の値がFitnessLimit以下になったときに、アルゴリズムは停止します。MaxStallGenerations—MaxStallGenerationsにわたる適応度関数値の平均相対変化がFunction tolerance未満になると、アルゴリズムは停止します。MaxStallTime—MaxStallTimeに等しい秒数の間に目的関数に改善が見られない場合、アルゴリズムは停止します。FunctionTolerance— アルゴリズムは、MaxStallGenerationsにおける適応度関数値の平均相対変化がFunction tolerance未満になるまで実行されます。ConstraintTolerance—ConstraintToleranceは停止基準として使用されません。非線形制約に関する実現可能性を判断するために使用されます。また、max(sqrt(eps),ConstraintTolerance)は線形制約に関する実現可能性を決定します。
これらの条件のいずれかが満たされるとすぐにアルゴリズムは停止します。
選択
選択関数は、適応度スケーリング関数からのスケーリングされた値に基づいて、世代の親を選択します。スケーリングされた適応度値は期待値と呼ばれます。個体は親として複数回選択される可能性があり、その場合、その個体の遺伝子は複数の子に提供されます。デフォルトの選択オプション @selectionstochunif では、各親がそのスケール値に比例した長さの線の部分に対応する線がレイアウトされます。アルゴリズムは、等間隔で線に沿って移動します。各ステップで、アルゴリズムは到達したセクションから親を割り当てます。
より決定論的な選択オプションは @selectionremainder であり、これは次の 2 つのステップを実行します。
最初のステップでは、関数は各個体のスケール値の整数部分に従って決定論的に親を選択します。たとえば、個体のスケール値が 2.3 の場合、関数はその個体を親として 2 回選択します。
2 番目のステップでは、選択関数は、確率的均一選択と同様に、スケールされた値の小数部分を使用して追加の親を選択します。この関数は、個体のスケール値の小数部に比例する長さのセクションに線をレイアウトし、線に沿って等間隔で移動して親を選択します。
Topスケーリングを使用する場合のように、スケーリングされた値の小数部分がすべて 0 に等しい場合、選択は完全に決定論的であることに注意してください。
詳細およびその他の選択オプションについては、選択オプション を参照してください。
複製オプション
再生オプションは、遺伝的アルゴリズムが世代を作成する方法を制御します。オプションは
EliteCount—現在の世代で最高の適応度値を持ち、次の世代まで生き残ることが保証されている個体の数。これらの個体はエリートの子と呼ばれます。EliteCountが 1 以上の場合、最適な適応度値は世代ごとに減少するだけです。遺伝的アルゴリズムは適応度関数を最小化するため、これが期待通りの結果になります。EliteCountを高い値に設定すると、最も適応した個体が母集団を支配することになり、探索の効率が低下する可能性があります。CrossoverFraction— 交叉によって生成される、エリートの子以外の世代の個体の割合。突然変異と交叉を変化させる のトピック「交叉率の設定」では、CrossoverFractionの値が遺伝的アルゴリズムのパフォーマンスにどのように影響するかについて説明します。
エリート個体はすでに評価されているため、ga は繁殖中にエリート個体の適応度関数を再評価しません。この動作は、個体の適応度関数がランダムではなく、決定論的な関数であると想定しています。この動作を変更するには、出力関数を使用します。状態構造の EvalElites を参照してください。
突然変異と交叉
遺伝的アルゴリズムは、現在の世代の個体を使用して、次の世代を構成する子を作成します。アルゴリズムは、現在の世代で最適な適応度値を持つ個体に対応するエリートの子に加えて、
現在の世代の個体のペアからベクトルエントリ(遺伝子)を選択し、それらを組み合わせて子を形成することによって交叉子を生成する。
現在の世代の単一の個体にランダムな変更を適用して子を作成することにより、突然変異の子を作成する。
どちらのプロセスも遺伝的アルゴリズムに不可欠です。交叉により、アルゴリズムは異なる個体から最適な遺伝子を抽出し、それらを再結合して潜在的に優れた子を生成することができます。突然変異により母集団の多様性が増し、アルゴリズムがより良い適応度値を持つ個体を生成する可能性が高まります。
遺伝的アルゴリズムが突然変異と交叉を適用する方法の例については、新しい世代の作成 を参照してください。
次のように、アルゴリズムが作成する各タイプの子の数を指定できます。
EliteCountはエリートの子の数を指定します。CrossoverFractionは、エリートの子以外の、交叉子である母集団の割合を指定します。
たとえば、PopulationSize が 20、EliteCount が 2、CrossoverFraction が 0.8 の場合、次の世代の各タイプの子の数は次のようになります。
エリートの子の個体が 2 つあります。
エリートの子以外の個体は 18 個あるため、アルゴリズムは 0.8 * 18 = 14.4 を 14 に切り上げて交叉子の数を取得します。
エリートの子以外の残りの 4 個体は、突然変異の子です。
整数制約と線形制約
問題に整数または線形制約(境界を含む)がある場合、アルゴリズムは母集団の進化を変更します。
問題に整数制約と線形制約の両方がある場合、ソフトウェアは生成されたすべての個体をそれらの制約に関して実行可能になるように修正します。任意の作成関数、突然変異、または交叉関数を使用でき、母集団全体は整数制約と線形制約に関して実行可能なままになります。
問題に線形制約のみがある場合、ソフトウェアはそれらの制約に関して実行可能となるように個体を変更しません。線形制約に関して実現可能性を維持する作成、突然変異、および交叉関数を使用する必要があります。そうしないと、母集団が実行不可能になり、結果が実行不可能になる可能性があります。デフォルトの演算子は線形実現可能性を維持します: 作成の場合は
gacreationlinearfeasibleまたはgacreationnonlinearfeasible、突然変異の場合はmutationadaptfeasible、交叉の場合はcrossoverintermediate。
整数および線形実行可能性の内部アルゴリズムは、surrogateopt のアルゴリズムと似ています。問題に整数制約と線形制約がある場合、アルゴリズムはまず線形に実行可能点を作成します。次に、アルゴリズムは、点を線形に実行可能な状態に保つヒューリスティックを使用して、線形に実行可能点を整数に丸めることで、整数制約を満たそうとします。このプロセスで母集団を構築するのに十分な実行可能点を取得できなかった場合、アルゴリズムは intlinprog を呼び出して、境界、線形制約、および整数制約に関して実行可能点をさらに見つけようとします。
その後、突然変異または交叉によって新しい母集団メンバーが作成されると、アルゴリズムは同様の手順を実行して、新しいメンバーが整数かつ線形実行可能であることを確認します。各新しいメンバーは、必要に応じて、整数および線形制約と境界を満たしながら、元の値に可能な限り近くなるように変更されます。