時系列予測入門
この例では、Time Series Modelerアプリを使用して、時系列データをモデル化するためのシンプルな長短期記憶 (LSTM) ネットワークを作成する方法を示します。
時系列予測には、時間の経過とともに収集された以前の観測データ点に基づいて、将来の値を予測することが含まれます。再帰型ニューラル ネットワーク (例: LSTM ネットワークや GRU ネットワーク) やフィードフォワード ネットワーク (例: 多層パーセプトロンや畳み込みニューラル ネットワーク) などのアーキテクチャを使用して、時系列予測のために深層学習モデルに学習させることができます。
データの読み込み
時系列モデルに学習させる場合、使用できる入力データは 2 種類あります。
応答: 予測したい時系列。
予測子: これらは、応答に影響を与える外部 (外生) 時系列ですが、予測したい対象ではありません。予測子はオプションであり、応答のみを使用して自己回帰モデルに学習させることができます。
サンプルのエンジン データを読み込みます。モデルは、4 つの予測子 (スロットル位置、ウェイストゲート バルブ面積、エンジン速度、および点火時期) を使用して、単一の応答であるエンジン トルクの値を予測することを学習します。
load SIEngineData時系列モデラー アプリを開きます。[アプリ] ギャラリーで、[時系列モデラー] をクリックします。
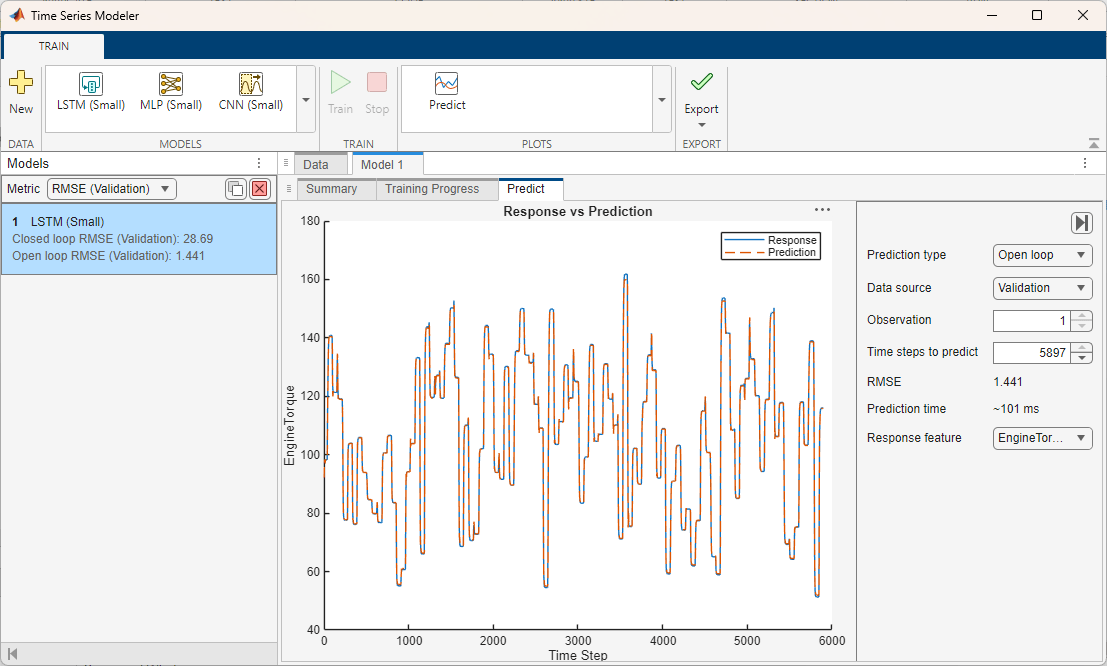
アプリにデータをインポートするには、[新規] をクリックします。[データのインポート] ダイアログ ボックスが開きます。ダイアログ ボックスで、[データ] として [応答と予測子を別々の変数からインポート] を選択します。応答として responses 変数を選択します。予測子には、predictors 変数を選択します。データの 20% を検証に使用し、80% を学習に使用します。
[インポート] をクリックします。
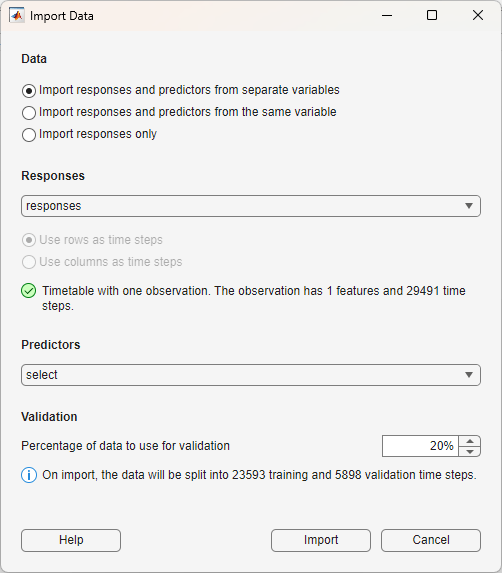
アプリには、データ セットの概要と共に、応答と予測子の両方について、学習データと検証データにおける個別の観測値のプレビューが表示されます。学習データまたは検証データとなるデータ ソースを選択できるほか、プレビューする観測値を選択することもできます。
モデルの選択
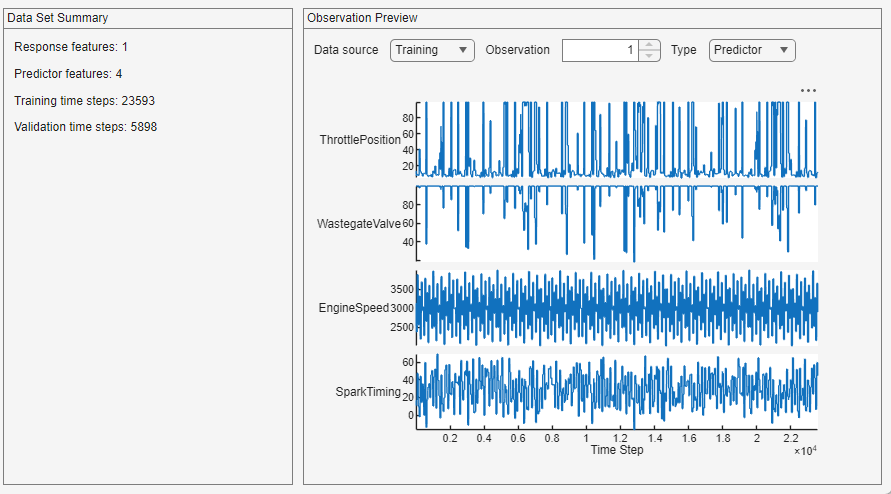
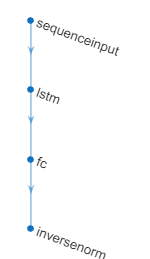
[モデル] ギャラリーから深層学習モデルを選択します。選択すべきモデルはタスクによって異なります。この例では、[LSTM (小)] を選択します。既定では、このネットワークに 4 つの層があります。アプリを使用して、ネットワークの深さと学習可能なパラメーター (隠れユニット) の数を変更できます。
モデルの学習
モデルに学習させるには、[学習] をクリックします。学習中、アプリは学習情報、平均絶対誤差 (MAE) と損失 (RMSE) のプロット、および学習診断を表示します。
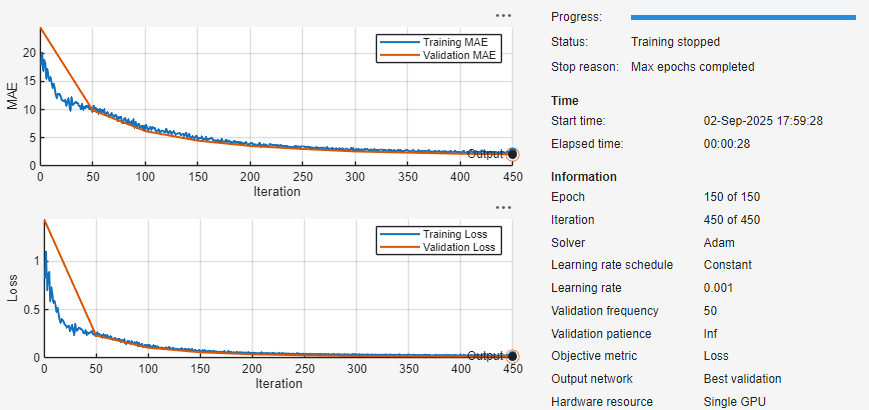
モデルのテスト
モデルを使用して値を予測するには、[予測] をクリックします。選択された観測値について、アプリは実際の値と予測値を表示します。学習済みモデルの RMSE 値を確認することもできます。この値は、モデルが検証データに対してどの程度適切に機能するかを示します。
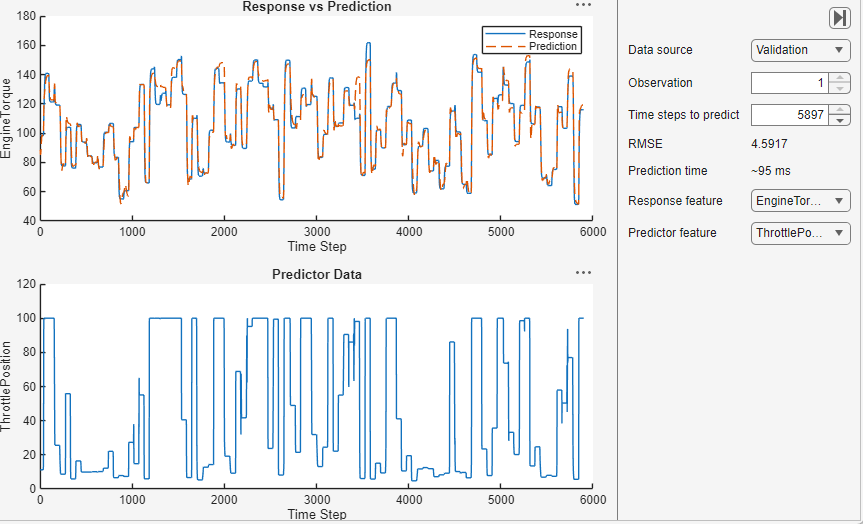
モデルのエクスポート
学習済みのモデルのパフォーマンスが十分である場合、それをエクスポートし、新しいテスト データに対して使用できます。モデルをエクスポートし、テスト データの新しい値を予測するコードを生成するには、[エクスポート] をクリックします。
参考
dlnetwork | trainingOptions | trainnet | scores2label | ディープ ネットワーク デザイナー