GoogLeNet を使用したイメージの分類
この例では、事前学習済みの深層畳み込みニューラル ネットワーク GoogLeNet を使用してイメージを分類する方法を説明します。
GoogLeNet は、100 万個を超えるイメージで学習しており、イメージを 1000 個のオブジェクト カテゴリ (キーボード、マグ カップ、鉛筆、多くの動物など) に分類できます。このネットワークは広範囲にわたるイメージについての豊富な特徴表現を学習しています。このネットワークは入力としてイメージを取り、イメージ内のオブジェクトのラベルを各オブジェクト カテゴリの確率と共に出力します。
事前学習済みのネットワークの読み込み
関数 imagePretrainedNetwork を使用して、事前学習済みの GoogLeNet ネットワークと対応するクラス名を読み込みます。この手順には、Deep Learning Toolbox™ Model for GoogLeNet Network サポート パッケージが必要です。必要なサポート パッケージがインストールされていない場合、ダウンロード用リンクが表示されます。
イメージ分類用の異なる事前学習済みネットワークを読み込むこともできます。別の事前学習済みネットワークを試すには、この例を MATLAB® で開き、別のネットワークを選択します。たとえば、GoogLeNet よりも高速なネットワークである SqueezeNet を試すことができます。この例は、他の事前学習済みネットワークを使用して実行することもできます。使用可能なすべてのネットワークについては、事前学習済みの深層ニューラル ネットワークを参照してください。
[net,classNames] = imagePretrainedNetwork( "googlenet");
"googlenet");分類するイメージのサイズは、ネットワークの入力サイズと同じでなければなりません。GoogLeNet では、ネットワークの Layers プロパティの最初の要素はイメージ入力層です。ネットワーク入力サイズはイメージ入力層の InputSize プロパティです。
inputSize = net.Layers(1).InputSize
inputSize = 1×3
224 224 3
10 個のクラス名をランダムに表示します。
numClasses = numel(classNames); disp(classNames(randperm(numClasses,10)))
"speedboat"
"window screen"
"isopod"
"wooden spoon"
"lipstick"
"drake"
"hyena"
"dumbbell"
"strawberry"
"custard apple"
イメージの読み取り
分類するイメージを読み取って表示します。
I = imread("peppers.png");
figure
imshow(I)
イメージのサイズ変更と分類
イメージのサイズを表示します。このイメージは 384 x 512 ピクセルで 3 つのカラー チャネル (RGB) があります。
size(I)
ans = 1×3
384 512 3
imresize を使用して、イメージのサイズをネットワークの入力サイズに変更します。このサイズ変更では、イメージの縦横比が多少変化します。
X = imresize(I,inputSize(1:2)); figure imshow(X)

用途によっては、異なる方法でイメージのサイズを変更する必要がある場合もあります。たとえば、I(1:inputSize(1),1:inputSize(2),:) を使用して、イメージの左上隅をトリミングできます。Image Processing Toolbox™ がある場合は、関数 imcrop を使用できます。
ニューラル ネットワークを使用して予測を行います。単一のイメージを使用して予測を行うには、関数predictを使用します。このイメージのデータ型は uint8 です。ニューラル ネットワークを使用して予測を行うには、イメージをデータ型 single に変換します。GPU を使用するには、データを gpuArray に変換します。GPU を使用するには、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。そうでない場合、関数は CPU を使用します。
X = single(X); if canUseGPU X = gpuArray(X); end scores = predict(net,X);
関数 predict は、各クラスの確率を返します。分類スコアをカテゴリカル ラベルに変換するには、関数 scores2label を使用します。
[label,score] = scores2label(scores,classNames);
元のイメージを、予測ラベル、およびイメージがそのラベルを持つ予測確率と共に表示します。
figure
imshow(I)
title(string(label) + ", " + string(score))
上位の予測の表示
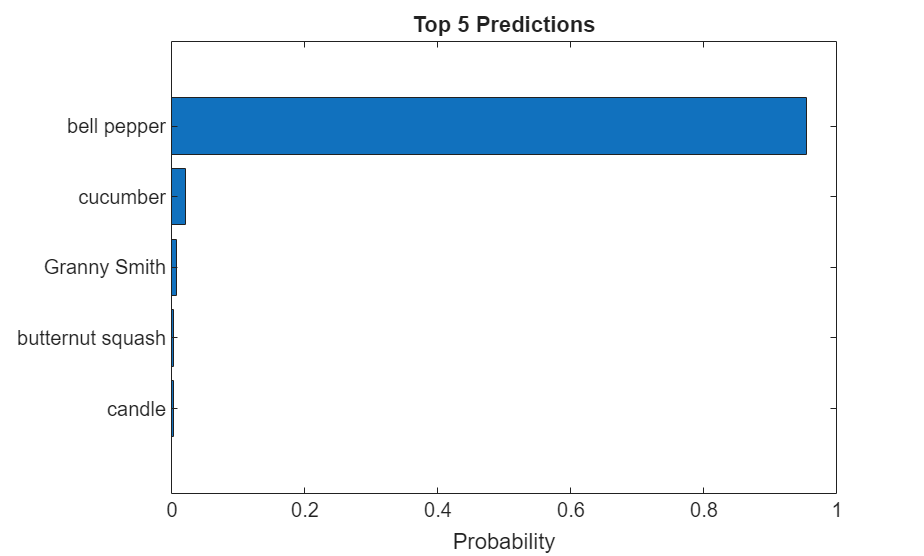
上位 5 つの予測ラベルとそれらに対応する確率をヒストグラムとして表示します。ネットワークはイメージを非常に多くのオブジェクト カテゴリに分類しますが、多くのカテゴリは似ているため、ネットワークを評価するときは、通常、上位 5 つの精度を考慮します。このネットワークは高い確率でこのイメージをピーマンとして分類します。
[~,idx] = sort(scores,"descend"); idx = idx(5:-1:1); classNamesTop = classNames(idx); scoresTop = scores(idx); figure barh(scoresTop) xlim([0 1]) title("Top 5 Predictions") xlabel("Probability") yticklabels(classNamesTop)
参照
[1] Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. "Going deeper with convolutions." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1-9. 2015.
[2] BVLC GoogLeNet Model. https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
参考
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | testnet | minibatchpredict | scores2label | predict