曲線フィッター アプリにおける近似の比較
対話型の曲線フィッター ワークフロー
次のトピックでは、6 次までの多項方程式と単項指数方程式を使用して国勢調査データに当てはめます。その手順では、以下を実行する方法を示します。
データを読み込み、異なるライブラリ モデルを使用してさまざまな近似を探索。
以下を使用して最適な近似を探索:
グラフィカルな近似結果の比較
近似係数および適合度の統計量を含む数値的な近似結果の比較
最適な近似結果を MATLAB® ワークスペースにエクスポートし、コマンド ラインでモデルを解析。
セッションを保存し、すべての近似およびプロットの MATLAB コードを生成。
データの読み込みと近似の作成
曲線フィッター アプリを使用してデータの近似を作成するには、その前にデータ変数を MATLAB ワークスペースに読み込まなければなりません。この例では、データは MATLAB ファイル census.mat に保存されています。
データを読み込みます。
load censusワークスペースには次の 2 つの新しい変数が含まれています。
cdateは、1790 年から 1990 年までの 10 年ごとの年度を示す列ベクトルです。popは、cdateの年度に対応する米国の人口数が記された列ベクトルです。
曲線フィッター アプリを開きます。
curveFitter
[曲線フィッター] タブの [データ] セクションで [データの選択] をクリックします。[近似データの選択] ダイアログ ボックスで、[X データ] リストと [Y データ] リストから、それぞれ変数名の
cdateとpopを選択します。曲線フィッター アプリによって、X 入力 (予測子) データと Y 出力 (応答) データに対する既定の近似が作成されプロットされます。既定の近似は線形多項式近似タイプです。[近似オプション] ペインに表示される近似設定を観察します。この近似は 1 次多項式です。
[近似オプション] ペインで、[次数] リストから
[2]を選択して、近似を 2 次多項式に変更します。曲線フィッター アプリにより、新しい近似がプロットされます。曲線フィッター アプリでは既定で [自動] が選択されているため、近似設定を変更すると、新しい近似が計算されます。データ セットが大きいケースでは再近似に時間がかかることがあるので、そのような場合は自動動作を無効にできます。[曲線フィッター] タブの [近似] セクションで [手動] をクリックします。
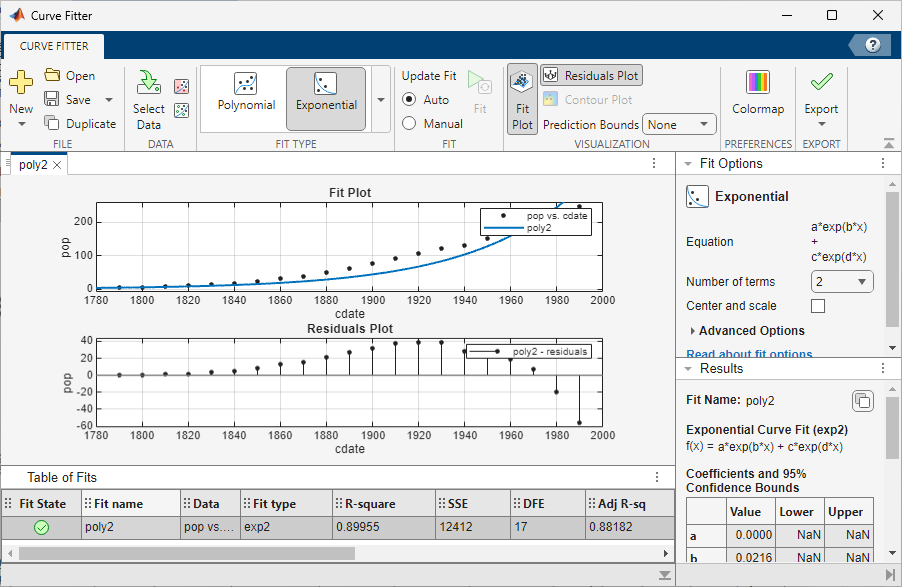
曲線フィッター アプリにより、2 次多項式を使用した国勢調査データの近似結果が [結果] ペインに表示され、ライブラリ モデル、近似係数および適合度の統計量をそこで確認できます。
近似の名前を変更します。[近似テーブル] ペインで、[近似名] 列の
untitled fit 1をダブルクリックしてpoly2と入力します。残差を表示します。[曲線フィッター] タブの [可視化] セクションで [残差プロット] をクリックします。
残差は、より適切に近似できる可能性を示しています。そのため、国勢調査データセットのさまざまな近似の探索を続けます。
新しい近似を追加して、その他のライブラリの方程式を試します。
[近似テーブル] ペインの近似を右クリックし、["poly2" を複製] を選択します。または、[曲線フィッター] タブの [ファイル] セクションで [複製] をクリックします。
ヒント
特定のタイプ (多項式など) の近似では、近似をコピーした方が必要な手順が少なくなるので、新しい近似を作成するのではなく、近似を複製します。複製した近似には、同じデータ選択と近似設定が含まれます。
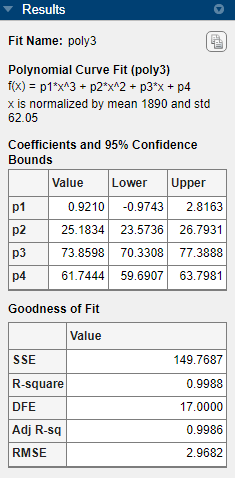
多項式の [次数] を
3に変更し、近似の名前をpoly3に変更します。高い次数の多項式を当てはめると、[結果] ペインに次の警告が表示されます。
Equation is badly conditioned. Remove repeated data points or try centering and scaling.
データを正規化するには、[近似オプション] ペインの [データのセンタリングとスケーリング] チェック ボックスをオンにします。
手順 a および b を繰り返し、6 次までの多項式近似を追加します。その後、指数近似を追加します。[曲線フィッター] タブの [ファイル] セクションで、[新規] をクリックして [新規近似] を選択します。[近似タイプ] セクションの矢印をクリックしてギャラリーを開き、[回帰モデル] セクションの [指数] をクリックします。
新しい近似ごとに、アプリで [結果] ペインの情報と残差プロットを確認します。
適切な近似の残差は、明確なパターンがなくランダムになります。同じ符号の残差が連続する傾向があるなど、なんらかのパターンがある場合は、より適切なモデルが存在する可能性を示しています。
スケーリングについて
この近似手順では非常に大きな値を含む行列の基底として cdate の値を使用するため、スケーリングについての警告が発生します。cdate の値の広がりが原因でスケーリングの問題が発生します。この問題に対処するために、cdate データを正規化することができます。正規化により予測子データがスケーリングされ、その後の数値計算の精度が向上します。たとえば、cdate の正規化は、データがゼロ平均と単位標準偏差になるようにセンタリングとスケーリングを行うことで可能です。
(cdate - mean(cdate))./std(cdate)
メモ:
正規化の後、予測子データが変化するため、近似係数の値も元のデータに比べて変化します。ただし、データの関数形式と結果として得られる適合度の統計量は変化しません。また、曲線フィッター アプリのプロットでは元のスケールでデータが表示されます。
最適な近似の決定
最適な近似を決定するには、グラフィカルな近似結果と数値的な近似結果の両方を検証する必要があります。
グラフィカルな近似結果の検証
近似と残差のグラフを検証することにより最適な近似を決定します。各近似のプロットを順に表示するには、[近似テーブル] ペインの近似をクリックします。グラフィカルな近似結果は以下を示しています。
多項方程式の近似と残差はどれも似ているため、最適なものを選択することが難しくなっています。
単項指数方程式の近似と残差は、全体的に近似が適切でないことを示しています。したがって、これは不適切な選択であり、最適な近似の候補から指数近似を削除できます。
2000 年より後の近似の振る舞いを検証します。国勢調査データの近似の目標は、最適な近似を外挿して将来の人口値を予測することです。
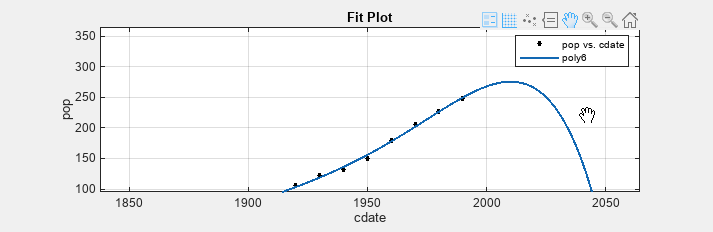
[近似テーブル] ペインの 6 次多項式近似をクリックし、この近似のプロットを表示します。
近似プロットで、座標軸ツール バーの [パン] ボタン
 をクリックして、2000 年より後の数年間の近似が見えるように移動します。残差プロットの座標軸の範囲は移動に合わせて調整されます。
をクリックして、2000 年より後の数年間の近似が見えるように移動します。残差プロットの座標軸の範囲は移動に合わせて調整されます。近似のプロットを検証します。データ範囲外での 6 次多項式近似の振る舞いから、これは外挿に適した選択ではないため、この近似は棄却できます。
数値的な近似結果の評価
グラフィカルな近似の検証でそれ以上近似を削除できない場合、数値的な近似結果を検証する必要があります。曲線フィッター アプリには、次の 2 種類の数値的な近似結果が表示されます。
適合度の統計量
近似係数の信頼限界
適合度の統計量は、曲線がデータをどの程度適切に近似できるかの判断に役立ちます。係数の信頼限界によって係数の精度が決まります。
数値的な近似結果を検証します。
近似ごとに、適合度の統計量が [結果] ペインに表示されます。
[近似テーブル] ペインですべての近似を同時に比較します。列見出しをクリックすると、統計量の結果で並べ替えることができます。
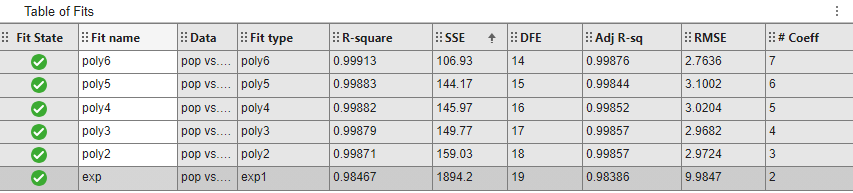
誤差の二乗和 (SSE) と自由度調整済み決定係数の統計量を検証すると、最適な近似の決定に役立ちます。RSSE の統計量は近似の最小二乗誤差であり、値がゼロに近いほど近似が適切であることを示します。一般に、自由度調整済み決定係数の統計量は、係数をモデルに追加するときに近似品質の最も優れた指標になります。R
expの最大の SSE は、この近似が適切でないことを示しています。これについては、近似と残差の検証により既に判断済みです。SSE 値が最小なのはpoly6です。ただし、データ範囲外でのこの近似の振る舞いから、これは外挿に適した選択ではありません。新しい軸の範囲を使用したプロットの検証により、この近似は棄却済みです。その次に SSE 値が適切なのは 5 次多項式近似
poly5であり、これが最適な近似である可能性があります。ただし、残りの多項式近似の SSE と自由度調整済み決定係数の値はすべて互いに非常に近い値です。R最適な近似の問題を解決するには、[結果] ペインで残りの近似の信頼限界を検証します。[近似テーブル] ペインで近似をクリックしてその近似の Figure を開き (既に開いている場合は Figure を選択)、[結果] ペインを確認します。各近似の Figure には、1 つの近似のプロットが複数表示されます。
5 次多項式
poly5と 2 次多項式poly2の近似の Figure を並べて表示します。結果を並べての検証は近似の評価に役立ちます。近似の Figure を 2 つ同時に表示するには、[近似] ペインで近似の Figure タブをドラッグ アンド ドロップします。または、近似の Figure タブの右端にある [ドキュメント アクション] ボタンをクリックします。
[すべて並べて表示]オプションを選択して、1 行 2 列または 2 行 1 列のレイアウトを指定します。
近似
poly5とpoly2の両方について [結果] ペインで係数と範囲 (p1、p2など) を比較します。係数の 95% 信頼限界が計算されます。係数の信頼限界によって係数の精度が決まります。[結果] ペインで方程式 (f(x)=p1*x+p2*x...) を確認し、各係数のモデル項を調べます。p2はPoly2の項p2*xとPoly5の項p2*x^4を示していることに注意してください。正規化した係数と正規化していない係数を直接比較しないでください。ヒント
次に示すように広いスペースでプロットと結果を表示して比較するには、[近似テーブル] ペインを下にドラッグします。[結果] ペインを非表示にしてプロットのみを表示することもできます。
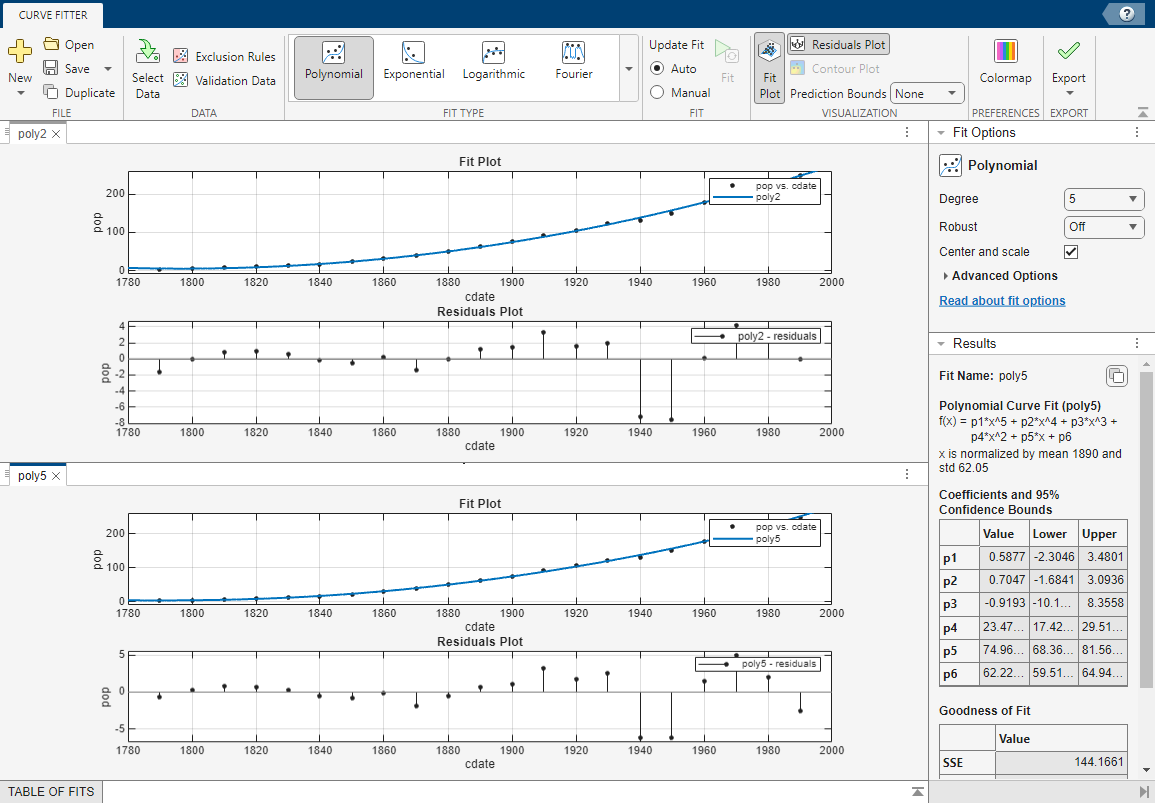
5 次多項式の係数
p1、p2およびp3については、範囲がゼロと交差します。そのため、これらの係数がゼロではないという確信はもてません。高次数のモデル項の係数がゼロになる場合、それらの項は近似に寄与しておらず、このモデルが国勢調査データに過適合していることを示しています。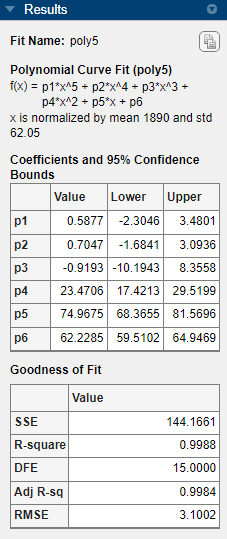
一方、2 次近似
poly2ではp1、p2、p3の信頼限界が小さくゼロと交差しません。これは、近似係数がかなり正確に求められたことを示しています。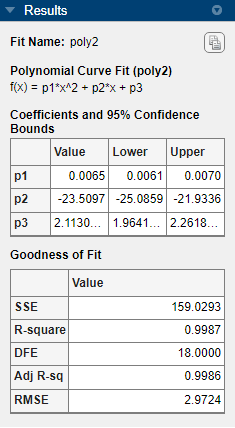
こうして、グラフィカルな近似結果と数値的な近似結果の両方を検証すると、国勢調査データを外挿するための最適な近似として
poly2を選択することになります。
メモ:
定数項、1 次および 2 次の項に関連する近似係数は正規化されたどの多項方程式でもほぼ同一です。ただし、多項式の次数が大きくなると、高次の項に関連する係数範囲がゼロと交差し、過適合の可能性があることがわかります。
ワークスペースでの最適な近似の解析
選択した近似および関連する近似結果を MATLAB ワークスペースにエクスポートできます。[曲線フィッター] タブの [エクスポート] セクションで [エクスポート] をクリックし、[ワークスペースにエクスポート] を選択します。近似は MATLAB オブジェクトとして保存され、関連する近似結果は構造体として保存されます。
[近似テーブル] ペインで
poly2近似を右クリックし、["poly2" をワークスペースに保存] を選択します。または、[エクスポート] をクリックして [ワークスペースにエクスポート] を選択します。アプリからダイアログ ボックスが表示されます。
[OK] をクリックし、近似を既定の名前で保存します。
fittedmodelは Curve Fitting Toolbox™ のcfitオブジェクトとして保存されます。whos fittedmodelName Size Bytes Class Attributes fittedmodel 1x1 925 cfit
cfit オブジェクトの fittedmodel を調べ、モデル、近似係数、近似係数の信頼限界を表示します。
fittedmodel
Linear model Poly2:
fittedmodel(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)goodness 構造体を調べ、適合度の統計量を表示します。
goodness
goodness =
struct with fields:
sse: 159.0293
rsquare: 0.9987
dfe: 18
adjrsquare: 0.9986
rmse: 2.9724output 構造体を調べ、残差などの近似に関連する追加情報を表示します。
output
output =
struct with fields:
numobs: 21
numparam: 3
residuals: [21×1 double]
Jacobian: [21×3 double]
exitflag: 1
algorithm: 'QR factorization and solve'
iterations: 1さまざまな後処理関数を使用して、指定したデータ範囲で近似を評価 (内挿または外挿)、微分または積分することができます。
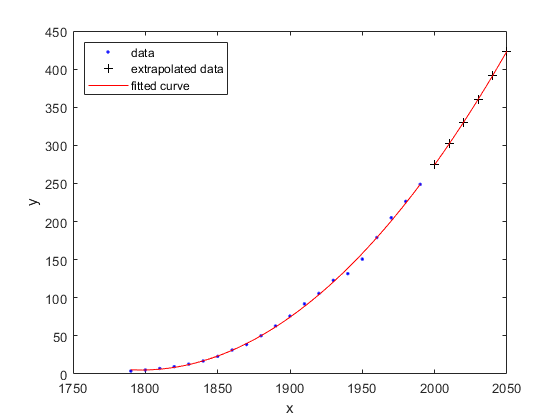
たとえば、fittedmodel を値のベクトルについて評価して 2050 年まで外挿します。
x = 2000:10:2050; y = fittedmodel(x)
y = 274.6221 301.8240 330.3341 360.1524 391.2790 423.7137
plot(fittedmodel,cdate,pop) hold on plot(fittedmodel,x,y,"k+") hold off legend(["data","","extrapolated data","fitted curve"], ... "Location","northwest")
対話型およびコマンド ラインでの近似解析の例や手順の詳細、すべての後処理関数のリストについては、近似の後処理を参照してください。
コマンド ラインを使用したこの対話型の国勢調査データの解析を再現する例については、多項式の曲線近似を参照してください。
作業の保存
曲線フィッター アプリには、作業を保存するための複数のオプションが用意されています。1 つ以上の近似および関連する近似結果を変数として MATLAB ワークスペースに保存できます。さらに、この保存した情報をドキュメンテーションにするために、またはデータの外挿と解析を拡張するために使用できます。作業を MATLAB ワークスペース変数に保存するだけでなく、次のことができます。
現在の曲線近似セッションを保存します。[曲線フィッター] タブの [ファイル] セクションで、[保存] をクリックして [セッションの保存] を選択します。セッション ファイルには、セッション内のすべての近似と変数が含まれていて、レイアウトが記憶されています。セッションを保存して再度開くを参照してください。
近似と、それに関連するプロットを再作成するための MATLAB コードを生成します。[エクスポート] セクションで、[エクスポート] をクリックして [コード生成] を選択します。曲線フィッター アプリは、現在選択されている近似のコードを生成し、そのファイルを MATLAB エディターに表示します。
近似とプロットを再作成するには、コマンド ラインから元のデータを入力引数に指定してそのファイルを呼び出します。また、このファイルを新しいデータと共に呼び出し、複数のデータ セットの近似プロセスを自動化できます。詳細については、曲線フィッター アプリからのコードの生成を参照してください。