VGGish Preprocess

Libraries:
Audio Toolbox /
Deep Learning
Description
The VGGish Preprocess block generates mel spectrograms from an audio input that you can then feed to the VGGish pretrained network or to a network that accepts the same inputs as VGGish.
Examples
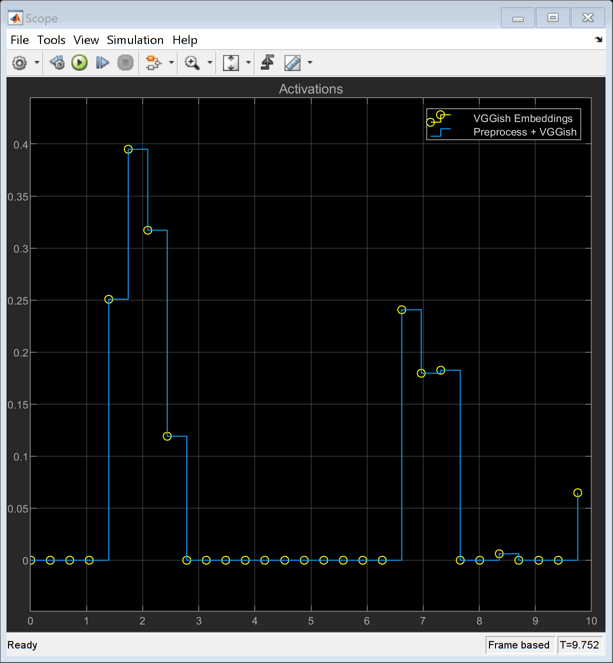
Compare VGGish Embeddings Block with Equivalent VGGish Blocks
Show that VGGish Embeddings block is equivalent to the cascade of VGGish Preprocess block and VGGish block.
Ports
Input
Output
Parameters
Block Characteristics
Data Types |
|
Direct Feedthrough |
|
Multidimensional Signals |
|
Variable-Size Signals |
|
Zero-Crossing Detection |
|
Algorithms
References
[1] Gemmeke, Jort F., Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events.” In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 776–80. New Orleans, LA: IEEE, 2017. https://doi.org/10.1109/ICASSP.2017.7952261.
[2] Hershey, Shawn, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, et al. “CNN Architectures for Large-Scale Audio Classification.” In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 131–35. New Orleans, LA: IEEE, 2017. https://doi.org/10.1109/ICASSP.2017.7952132.
Extended Capabilities
Version History
Introduced in R2022a