vartestn
等分散性に関する複数標本検定
構文
説明
vartestn( は、データ ベクトル x)x の列が同じ分散の正規分布から派生しているという帰無仮説のバートレット検定に対して統計量の概要テーブルと箱ひげ図を返します。対立仮説は、データのすべての列の分散が同じとは限らないとします。
vartestn( は、1 つ以上の名前と値のペア引数で指定された追加オプションを使用して、等しくない分散の検定に対する統計量の概要テーブルと箱ひげ図を返します。たとえば、異なるタイプの仮説検定を指定するか、検定結果の表示設定を変更できます。x,Name,Value)
vartestn( は、1 つ以上の名前と値のペア引数で指定された追加オプションを使用して、等しくない分散の検定に対する統計量の概要テーブルと箱ひげ図を返します。たとえば、異なるタイプの仮説検定を指定するか、検定結果の表示設定を変更できます。x,group,Name,Value)
例
標本データを読み込みます。
load examgrades学生の試験の採点データの行列 grades の 5 つの列において分散が等しいという帰無仮説を検定します。
vartestn(grades)
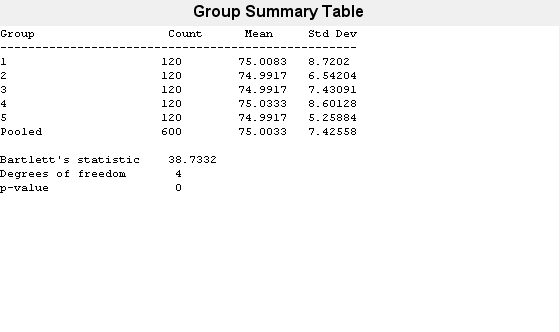
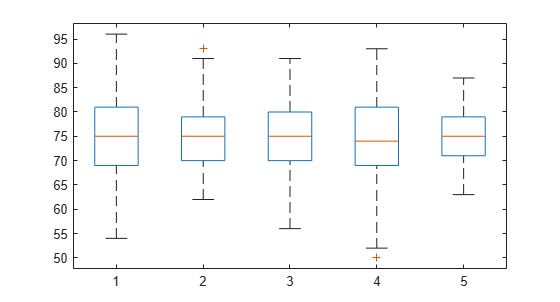
ans = 7.9086e-08
値が小さいので (p = 0)、少なくとも 1 つの列で分散が異なるという対立仮説が支持され、5 つの列すべてで分散が等しいという帰無仮説は vartestn によって棄却されることがわかります。
標本データを読み込みます。
load carsmallガロンあたりの走行マイル数 (MPG) の分散が、異なるモデル年において等しいという帰無仮説を検定します。
vartestn(MPG,Model_Year)
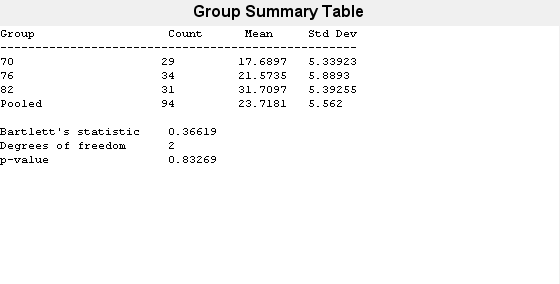
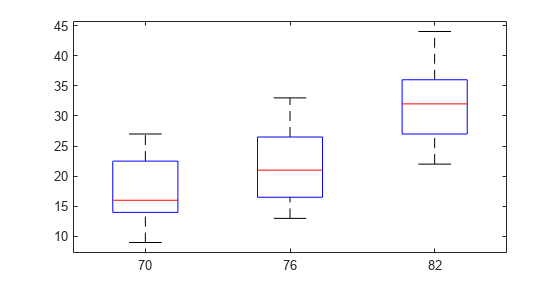
ans = 0.8327
値が大きいので (p = 0.83269)、ガロンあたりのマイル数 (MPG) の分散は異なるモデル年度で等しいという帰無仮説を vartestn が棄却しないことがわかります。
標本データを読み込みます。
load carsmallリーベンの検定を使用して、ガロンあたりの走行マイル数 (MPG) の分散が、異なるモデル年において等しいという帰無仮説を検定します。
p = vartestn(MPG,Model_Year,'TestType','LeveneAbsolute')
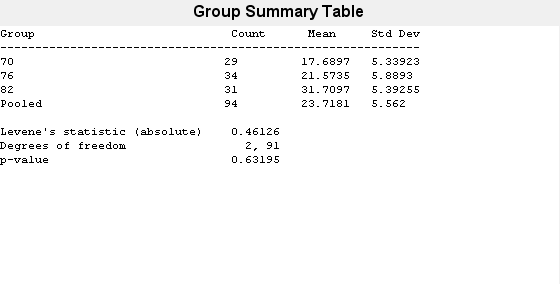
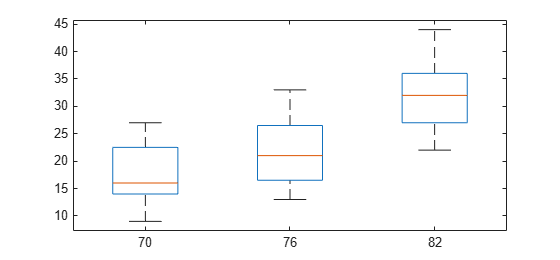
p = 0.6320
値が大きいので (p = 0.63195)、ガロンあたりのマイル数 (MPG) の分散は異なるモデル年度で等しいという帰無仮説を vartestn が棄却しないことがわかります。
標本データを読み込みます。
load examgradesブラウン・フォーサイス検定を使用して、学生の試験の採点データの行列 grades の 5 つの列において分散が等しいという帰無仮説を検定します。統計量の概要テーブルと箱ひげ図を非表示にします。
[p,stats] = vartestn(grades,'TestType','BrownForsythe','Display','off')
p = 1.3121e-06
stats = struct with fields:
fstat: 8.4160
df: [4 595]
値が小さいので (p = 1.3121e-06)、少なくとも 1 つの列で分散が異なるという対立仮説が支持され、5 つの列すべてで分散が等しいという帰無仮説は vartestn によって棄却されることがわかります。
入力引数
名前と値の引数
出力引数
詳細
バージョン履歴
R2006a より前に導入