このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
実験マネージャーを使用した分類モデルの調整
この例では、実験マネージャーを使用して機械学習分類器を最適化する方法を示します。目標は、交差検証損失が最小になる CreditRating_Historical データ セット用の分類器を作成することです。最初に、分類学習器アプリを使用して、利用可能なすべての分類モデルに学習データで学習させます。その後、最適なモデルを実験マネージャーにエクスポートして改良します。
実験マネージャーで、既定の設定を使用して交差検証損失を最小化します (つまり、交差検証の精度を最大化します)。損失の改善に役立つオプションを調べ、より詳しい実験を実行します。たとえば、一部のハイパーパラメーターの最適な値への固定、モデル調整プロセスへの有用なハイパーパラメーターの追加、ハイパーパラメーターの検索範囲の調整、学習データの調整、可視化のカスタマイズを行います。最終結果は、テスト セットの精度が向上した分類器です。
分類学習器から実験マネージャーにどのような場合にモデルをエクスポートするかの詳細については、分類学習器から実験マネージャーへのモデルのエクスポートを参照してください。
データの読み込みと分割
MATLAB® コマンド ウィンドウで、
CreditRating_Historical.datファイルを table に読み込みます。openExample("CreditRating_Historical.dat")[インポート ツール] が開きます。
[インポート] タブの [インポートされた変数] セクションで、[名前] ボックスに「
creditrating」と入力します。[インポート] セクションで、[選択のインポート] をクリックして [データのインポート] を選択します。予測子データには、法人顧客リストの財務比率と業種の情報が格納されています。応答変数には、格付機関が割り当てた信用格付けが格納されています。目標は、顧客の格付けを顧客の情報に基づいて予測する分類モデルを作成することです。変数
IDの各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID))はcreditratingに含まれる観測値の数に等しい)、変数IDは予測子としては適切ではありません。変数
IDを table から削除し、変数Industryをカテゴリカル変数に変換します。creditrating = removevars(creditrating,"ID"); creditrating.Industry = categorical(creditrating.Industry);応答変数
Ratingをカテゴリカル変数に変換し、カテゴリの順序を指定します。creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
データを 2 つのセットに分割します。観測値の約 80% を分類学習器でのモデルの学習に使用し、観測値の約 20% を最終的なテスト セット用に確保します。
cvpartitionを使用してデータを分割します。rng(0,"twister") % For reproducibility c = cvpartition(creditrating.Rating,"Holdout",0.2); trainingIndices = training(c); testIndices = test(c); creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
分類学習器でのモデルの学習
Parallel Computing Toolbox™ がある場合は、分類学習器アプリでモデルに並列に学習させることができます。モデルを並列に学習させた方がモデルを順番に学習させるよりも一般に速くなります。Parallel Computing Toolbox がない場合は、スキップして次の手順に進んでください。
アプリを開く前に、関数
parpoolを使用してプロセス ワーカーの並列プールを起動します。parpool("Processes")スレッド ワーカーではなくプロセス ワーカーの並列プールを起動しておけば、この後に実験マネージャーで確実に同じプールを使用できます。
メモ
実験マネージャーでは、スレッド プールを使用した並列計算はサポートされません。
分類学習器を開きます。[アプリ] タブをクリックしてから、[アプリ] セクションの右にある矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] グループの [分類学習器] をクリックします。
[学習] タブで、[ファイル] セクションの [新規セッション] をクリックし、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから table
[creditTrain]を選択します。応答変数と予測子変数が選択されます。既定の応答変数は[Rating]です。既定の検証オプションは 5 分割交差検証であるため、過適合が防止されます。[テスト] セクションで、[テスト データ セットの確保] チェック ボックスをクリックします。インポートされたデータの
15パーセントをテスト セットとして指定します。オプションはそのままで続行するため、[セッションの開始] をクリックします。
最適な分類器を得るために、事前設定されたすべてのモデルに学習させます。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[開始] グループで [すべて] をクリックします。[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。事前設定された各モデル タイプの学習が既定の複雑な木のモデルと共に 1 つずつ行われ、モデルが [モデル] ペインに表示されます。
最良の結果を見つけるには、検証精度に基づいて学習済みモデルを並べ替えます。[モデル] ペインで [並べ替え] リストを開き、
[精度 (検証)]を選択します。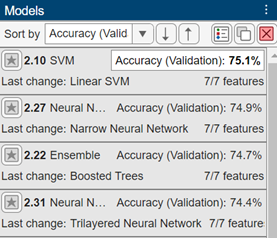
メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
最適なモデルの性能の評価
検証精度が最も高いモデルについて、各クラスにおける予測子の精度を調べます。[モデル] ペインで線形 SVM モデルを選択します。[学習] タブの [プロットと結果] セクションで [混同行列] をクリックします。真のクラスと予測したクラスの結果が含まれている行列が表示されます。青色の値は正しい分類を示し、赤色の値は誤った分類を示します。
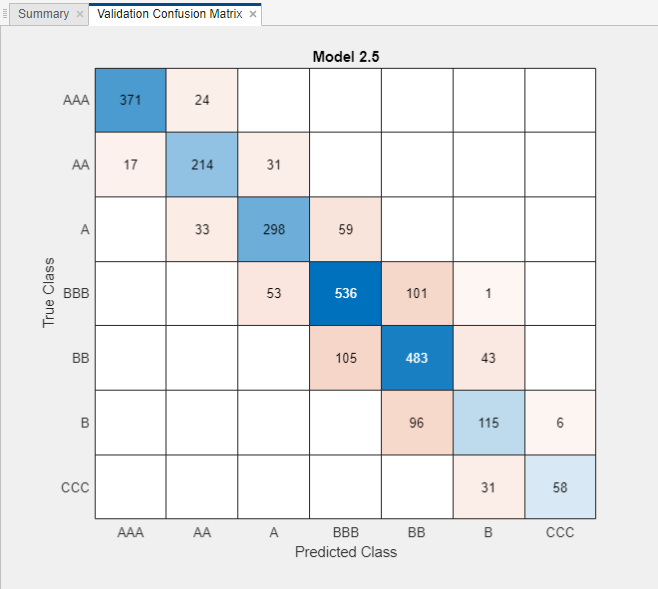
全体に、モデルの性能は良好です。特に、ほとんどの誤分類の予測値が真の値から 1 カテゴリしか離れていません。
各クラスにおける分類器の性能を調べます。[プロット] の [真陽性率 (TPR)]、[偽陰性率 (FNR)] オプションを選択します。TPR は、真のクラスごとの正しく分類された観測値の割合です。FNR は、真のクラスごとの誤って分類された観測値の割合です。
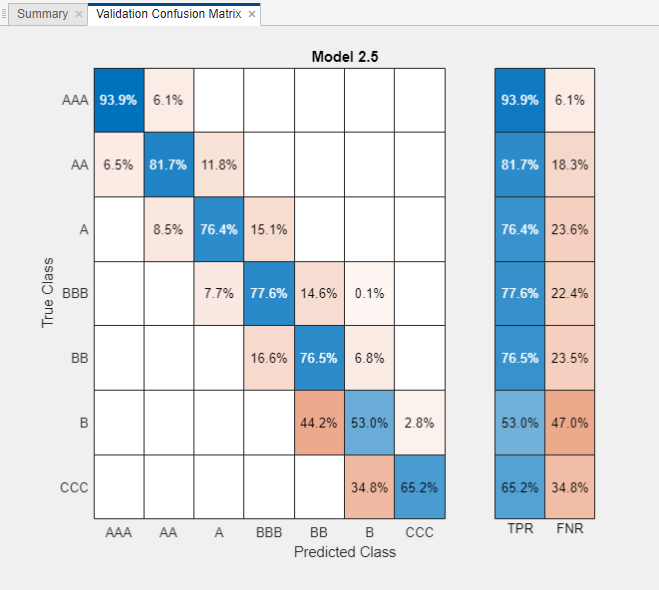
真の格付けが
AAAの観測値については 88% がモデルで正しく分類されていますが、真の格付けがBの観測値については分類が難しくなっています。モデルのテスト セット性能を確認します。[テスト] タブの [テスト] セクションで [選択項目をテスト] をクリックします。学習データと検証データを含むデータ セット全体で学習させたモデルのテスト セットの性能が計算されます。
モデルの検証精度とテスト精度を比較します。モデルの [概要] タブで、[学習結果] の [精度 (検証)] の値と [テスト結果] の [精度 (テスト)] の値を比較します。この例では、2 つの値がほぼ同じになっています。

実験マネージャーへのモデルのエクスポート
モデルの分類精度を改善できるか試すために、モデルを実験マネージャーにエクスポートします。[学習] タブで、[エクスポート] セクションの [モデルのエクスポート] をクリックし、[実験の作成] を選択します。[実験の作成] ダイアログ ボックスが開きます。
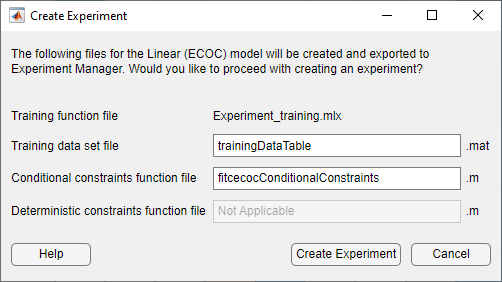
応答変数
Ratingにはクラスが複数あるため、効率的な線形 SVM モデルは、関数fitcecocを使用して学習させた (線形バイナリ学習器をもつ) マルチクラス ECOC モデルです。[実験の作成] ダイアログ ボックスで [実験の作成] をクリックします。アプリで実験マネージャーと新しいダイアログ ボックスが開きます。

ダイアログ ボックスで、実験のプロジェクトとして新規または既存のいずれかを選択します。この例では、新しいプロジェクトを作成し、[プロジェクト フォルダー名を指定] ダイアログ ボックスでファイル名を
TrainEfficientModelProjectと指定します。
既定のハイパーパラメーターでの実験の実行
実験を逐次的または並列に実行します。
メモ
Parallel Computing Toolbox がある場合は、時間の節約のために実験を並列に実行します。[実験マネージャー] タブの [実行] セクションで、[モード] リストから
[同時]を選択します。それ以外の場合は、[モード] の既定のオプションである
[逐次]を使用します。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
実験マネージャーで、実験の結果を表示する新しいタブが開きます。アプリでは、[Experiment1] タブにある [ハイパーパラメーター] のテーブルの指定に従って、試行ごとに異なる組み合わせのハイパーパラメーター値を使用してモデルの学習が行われます。
アプリで実験が実行された後、その結果を確認します。結果のテーブルで、[ValidationAccuracy] 列の矢印をクリックし、[降順に並べ替え] を選択します。
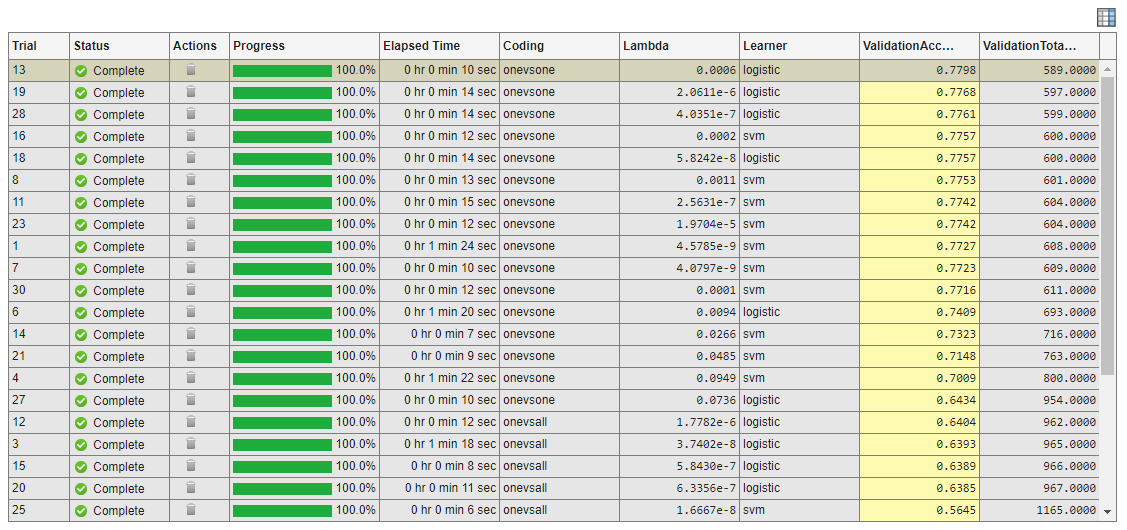
検証精度が高いモデルは [Coding] の値がすべて同じで、いずれも
onevsoneになっていることに注目してください。精度が最も高いモデルの混同行列を確認します。[実験マネージャー] タブの [結果の確認] セクションで [混同行列 (検証)] をクリックします。アプリの [可視化] ペインにモデルの混同行列が表示されます。
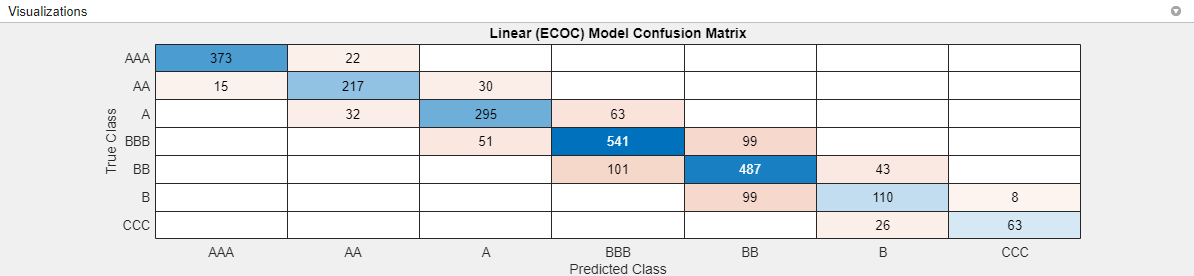
このモデルでは、すべての誤分類の予測値が真の値から 1 カテゴリしか離れていません。
ハイパーパラメーターとハイパーパラメーター値の調整
このデータ セットには 1 対 1 の符号化設計が最適であるように見えます。より優れた分類器が得られるか試すために、
Codingハイパーパラメーターの値をonevsoneに固定して実験をもう一度実行します。[Experiment1] タブをクリックします。[ハイパーパラメーター] のテーブルでCodingハイパーパラメーターの行を選択します。次に、[削除] をクリックします。符号化設計の値を指定するには、学習関数ファイルを開きます。[学習関数] セクションで [編集] をクリックします。アプリで
Experiment1_training1.mlxファイルが開きます。関数
fitcecocが使用されているコード行をファイルで検索します。この関数は、マルチクラスの線形分類器の作成に使用されます。符号化設計の値を名前と値の引数として指定します。ここでは、fitcecocの 2 つの呼び出しについて、'Coding','onevsone'を追加して次のように調整します。classificationLinear = fitcecoc(predictors, response, ... 'Learners', template, ecocParamsNameValuePairs{:}, ... 'ClassNames', classNames, 'Coding', 'onevsone');
classificationLinear = fitcecoc(trainingPredictors, ... trainingResponse, 'Learners', template, ... ecocParamsNameValuePairs{:}, 'ClassNames', classNames, ... 'Coding', 'onevsone');
コードの変更を保存し、ファイルを閉じます。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
実験で評価されるモデルをさらに変えるために、モデル調整プロセスに正則化ハイパーパラメーターを追加します。[Experiment1] タブの [ハイパーパラメーター] セクションで、[追加] の横にある矢印をクリックして [推奨リストから追加] を選択します。[推奨リストから追加] ダイアログ ボックスで、
Regularizationハイパーパラメーターを選択し、[追加] をクリックします。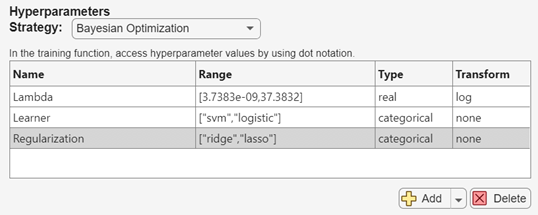
モデルで調整できるハイパーパラメーターの詳細については、分類学習器から実験マネージャーへのモデルのエクスポートを参照してください。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
正則化項 (ラムダ) の値の範囲を調整します。[Experiment1] タブの [ハイパーパラメーター] のテーブルで、上限が
3.7383e-02になるようにLambdaの範囲を変更します。[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
学習データの指定
実験をもう一度実行する前に、
creditTrainのすべての観測値を使用するように指定します。学習データを分類学習器にインポートするときに一部の観測値をテスト用に確保したため、これまでの実験では、いずれもcreditTrainデータ セットの観測値を 85% しか使用していません。実験ファイルを格納する
TrainEfficientModelProjectフォルダーにcreditTrainデータ セットをファイルfullTrainingData.matとして保存します。これを行うには、MATLAB ワークスペースで変数名creditTrainを右クリックし、[名前を付けて保存] をクリックします。ダイアログ ボックスでファイル名と場所を指定し、[保存] をクリックします。[Experiment1] タブの [学習関数] セクションで [編集] をクリックします。
Experiment1_training1.mlxファイルでloadコマンドを検索します。コードを次のように調整して、creditTrainデータ セット全体をモデルの学習に使用するように指定します。% Load training data fileData = load("fullTrainingData.mat"); trainingData = fileData.creditTrain;
[Experiment1] タブの [説明] セクションで、観測値の数を table
creditTrainの行数に相当する3146に変更します。[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
モデルの学習や調整では、すべての予測子を使用する代わりに予測子のサブセットを使用できます。ここでは、モデル学習プロセスから変数
Industryを除外します。[Experiment1] タブの [学習関数] セクションで [編集] をクリックします。
Experiment1_training1.mlxファイルで、変数predictorNamesおよびisCategoricalPredictorを指定しているコード行を検索します。コードを次のように調整して、変数Industryに対する参照を削除します。predictorNames = {'WC_TA', 'RE_TA', 'EBIT_TA', 'MVE_BVTD', 'S_TA'};isCategoricalPredictor = [false, false, false, false, false];
[Experiment1] タブの [説明] セクションで、予測子の数を
5に変更します。[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
混同行列のカスタマイズ
実験マネージャーの各試行で返される可視化をカスタマイズできます。ここでは、真陽性率と偽陰性率を表示するように検証の混同行列をカスタマイズします。[Experiment1] タブの [学習関数] セクションで [編集] をクリックします。
Experiment1_training1.mlxファイルで関数confusionchartを検索します。この関数は、学習させた各モデルについての検証の混同行列を作成します。真のクラスのそれぞれについて、正しく分類された観測値と誤って分類された観測値の個数を、対応する予測クラスの観測値数に対する割合で表示するように指定します。コードを次のように調整します。cm = confusionchart(response, validationPredictions, ... 'RowSummary', 'row-normalized');
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
結果のテーブルで、[ValidationAccuracy] 列の矢印をクリックし、[降順に並べ替え] を選択します。
精度が最も高いモデルの混同行列を確認します。[実験マネージャー] タブの [結果の確認] セクションで [混同行列 (検証)] をクリックします。アプリの [可視化] ペインにモデルの混同行列が表示されます。
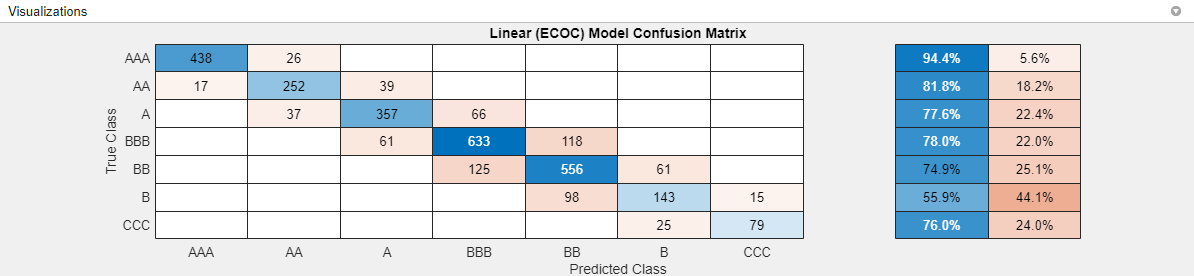
分類学習器で学習させた最適なモデルと同様に、このモデルでは真の格付けが
Bの観測値の分類が難しくなっています。ただし、真の格付けがCCCの観測値の分類については、このモデルの方が優れています。
最終モデルのエクスポートと使用
実験マネージャーで学習させたモデルを MATLAB ワークスペースにエクスポートできます。最後に実行された実験から得られた最適なモデルを選択します。[実験マネージャー] タブで、[エクスポート] セクションの [エクスポート] をクリックし、[学習の出力] を選択します。
[エクスポート] ダイアログ ボックスで、ワークスペース変数名を
finalLinearModelに変更して [OK] をクリックします。新しい変数がワークスペースに表示されます。
エクスポートした
finalLinearModel構造体を使用して、新しいデータによる予測を行います。構造体は、分類学習器アプリからエクスポートした学習済みモデルを使用する場合と同じように使用できます。詳細については、エクスポートしたモデルを使用した新しいデータについての予測を参照してください。ここでは、
creditTestのテスト データのラベルを予測します。testLabels = finalLinearModel.predictFcn(creditTest);
真のテスト データの応答と予測されたラベルを使用して、混同行列を作成します。
cm = confusionchart(creditTest.Rating,testLabels, ... "RowSummary","row-normalized");
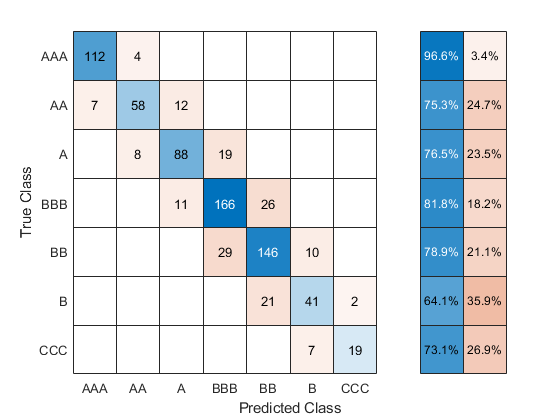
混同行列の値を使用してモデルのテスト セットの精度を計算します。
testAccuracy = sum(diag(cm.NormalizedValues))/ ... sum(cm.NormalizedValues,"all")
0.8015
この調整後のモデルのテスト セットの精度 (80.2%) の方が、分類学習器での効率的な線形 SVM 分類器のテスト セットの精度 (76.4%) よりも優れています。ただし、調整後のモデルでは
creditTestの観測値をテスト データとして使用しているのに対し、分類学習器のモデルではcreditTrainの観測値のサブセットをテスト データとして使用している点に注意してください。
参考
アプリ
関数
トピック
- 分類学習器から実験マネージャーへのモデルのエクスポート
- 新しいデータを予測するための分類モデルのエクスポート
- 実験の管理 (Deep Learning Toolbox)