resubPredict
再代入による回帰木の応答の予測
構文
説明
例
carsmall データ セットを読み込みます。Displacement、Horsepower および Weight が応答 MPG の予測子であると考えます。
load carsmall
X = [Displacement Horsepower Weight];すべての観測値を使用して回帰木を成長させます。
Mdl = fitrtree(X,MPG);
再代入の MSE を計算します。
Yfit = resubPredict(Mdl); mean((Yfit - Mdl.Y).^2)
ans = 4.8952
resubLoss を使用すると同じ結果が得られます。
resubLoss(Mdl)
ans = 4.8952
carsmall データ セットを読み込みます。Weight が応答 MPG の予測子であると考えます。
load carsmall
idxNaN = isnan(MPG + Weight);
X = Weight(~idxNaN);
Y = MPG(~idxNaN);
n = numel(X);すべての観測値を使用して回帰木を成長させます。
Mdl = fitrtree(X,Y);
いくつかの枝刈りレベルで部分木の再代入の当てはめた値を計算します。
m = max(Mdl.PruneList);
pruneLevels = 1:4:m; % Pruning levels to consider
z = numel(pruneLevels);
Yfit = resubPredict(Mdl,Subtrees=pruneLevels);Yfit は、当てはめた値が含まれている n 行 z 列の行列です。各行は観測値に、各列は部分木に対応しています。
Yfit と Y のいくつかの列を X に対してプロットします。
sortDat = sortrows([X Y Yfit],1); % Sort all data with respect to X plot(repmat(sortDat(:,1),1,size(Yfit,2)+1),sortDat(:,2:end)) % Vectorize for efficiency lev = num2str((pruneLevels)',"Level %d MPG"); legend(["Observed MPG"; lev]) title("In-Sample Fitted Responses") xlabel("Weight (lbs)") ylabel("MPG") h = findobj(gcf); set(h(4:end),LineWidth=3) % Widen all lines
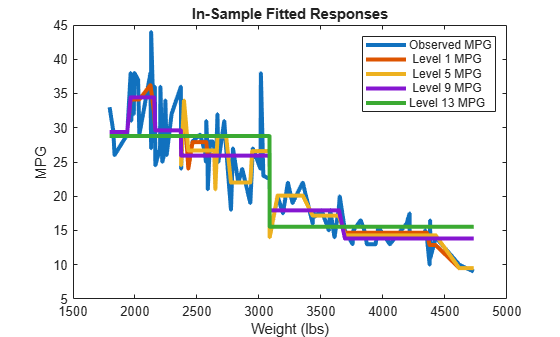
下位の枝刈りレベルでは、Yfit の値が上位レベルよりデータに近づく傾向があります。上位の枝刈りレベルでは、X の間隔が大きくなるのでフラットになる傾向があります。
入力引数
出力引数
拡張機能
バージョン履歴
R2011a で導入