optimalleaforder
階層クラスタリングの最適な葉ノードの順序
説明
例
linkage を使用して、階層バイナリ クラスター ツリーを作成します。次に、既定の順序を使用したデンドログラムと、最適な葉ノードの順序を使用したデンドログラムを比較します。
標本データを生成します。
rng(0,"twister") % For reproducibility X = rand(10,2);
距離ベクトルと階層バイナリ クラスタリング ツリーを作成します。距離とクラスタリング ツリーを使用して、最適な葉ノードの順序を判断します。
D = pdist(X);
tree = linkage(D,"average");
leafOrder = optimalleaforder(tree,D);既定の順序を使用したデンドログラムと、最適な葉ノードの順序を使用したデンドログラムをプロットします。
figure() subplot(2,1,1) dendrogram(tree) title("Default Leaf Order") subplot(2,1,2) dendrogram(tree,reorder=leafOrder) title("Optimal Leaf Order")
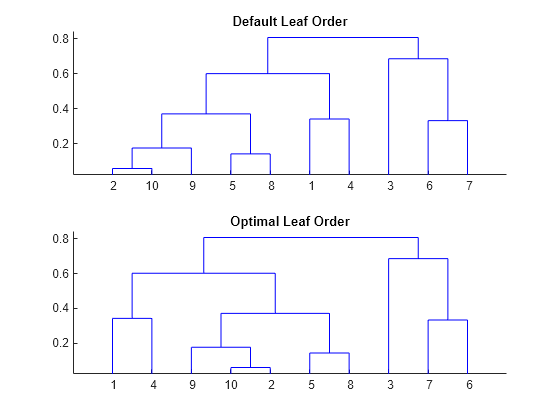
下の図における葉の順序は、leafOrder の要素に対応しています。最適な葉の順序では、隣接する葉の間で類似度の合計が最大になるようにツリーの枝が反転しています。
leafOrder
leafOrder = 1×10
1 4 9 10 2 5 8 3 7 6
標本データの散布図を作成し、点にラベルを付けます。
figure()
plot(X(:,1),X(:,2),".")
text(X(:,1),X(:,2),num2str((1:size(X,1))'))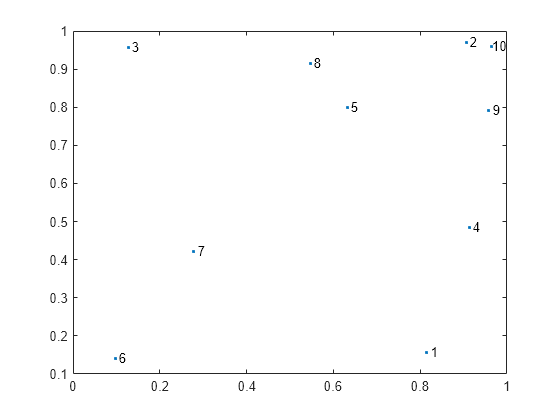
既定の葉の順序では、点 1 と 4 は点 3 と 8 の隣にあります。最適な葉の順序では、点 1 と 4 は点 9 の隣にあり、それらの相対的な位置が散布図に反映されています。
標本データを生成します。
rng('default') % For reproducibility X = rand(10,2);
距離ベクトルと階層バイナリ クラスタリング ツリーを作成します。
D = pdist(X);
tree = linkage(D,'average');逆の距離相似変換を使用して、最適な葉ノードの順序を判断します。
leafOrder = optimalleaforder(tree,D,'Transformation','inverse')
leafOrder = 1×10
1 4 9 10 2 5 8 3 7 6
入力引数
名前と値の引数
出力引数
参照
[1] Bar-Joseph, Z., Gifford, D.K., and Jaakkola, T.S. (2001). "Fast optimal leaf ordering for hierarchical clustering." Bioinformatics Vol. 17, Suppl 1:S22–9. PMID: 11472989.
バージョン履歴
R2012b で導入
参考
dendrogram | linkage | pdist