estimateMAP
クラス: HamiltonianSampler
対数確率密度の最大値の推定
構文
xhat = estimateMAP(smp)
[xhat,fitinfo] = estimateMAP(smp)
[xhat,fitinfo] = estimateMAP(___,Name,Value)
説明
xhat = estimateMAP(smp)smp の対数確率密度の最大事後確率 (MAP) 推定を返します。
[ は、追加の当てはめ情報を xhat,fitinfo] = estimateMAP(smp)fitinfo で返します。
[ では、1 つ以上の名前と値のペアの引数を使用して追加オプションを指定します。名前と値のペアの引数は、他のすべての入力引数の後で指定します。xhat,fitinfo] = estimateMAP(___,Name,Value)
入力引数
名前と値の引数
出力引数
例
正規分布についてハミルトニアン モンテカルロ サンプラーを作成し、対数確率密度の最大事後確率 (MAP) 点を推定します。
はじめに、多変量正規対数確率密度およびその勾配を返す関数 normalDistGrad を MATLAB® パス上に保存します (normalDistGrad はこの例の終わりで定義します)。次に、引数を指定してこの関数を呼び出し、関数 hmcSampler の入力引数 logpdf を定義します。
means = [1;-1]; standevs = [1;0.3]; logpdf = @(theta)normalDistGrad(theta,means,standevs);
開始点を選択し、HMC サンプラーを作成します。
startpoint = zeros(2,1); smp = hmcSampler(logpdf,startpoint);
MAP 点 (確率密度が最大になる点) を推定します。'VerbosityLevel' の値を 1 に設定して、最適化時の情報をさらに表示します。
[xhat,fitinfo] = estimateMAP(smp,'VerbosityLevel',1); o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 6.689460e+00 | 1.111e+01 | 0.000e+00 | | 9.000e-03 | 0.000e+00 | YES |
| 1 | 4.671622e+00 | 8.889e+00 | 2.008e-01 | OK | 9.006e-02 | 2.000e+00 | YES |
| 2 | 9.759850e-01 | 8.268e-01 | 8.215e-01 | OK | 9.027e-02 | 1.000e+00 | YES |
| 3 | 9.158025e-01 | 7.496e-01 | 7.748e-02 | OK | 5.910e-01 | 1.000e+00 | YES |
| 4 | 6.339508e-01 | 3.104e-02 | 7.472e-01 | OK | 9.796e-01 | 1.000e+00 | YES |
| 5 | 6.339043e-01 | 3.668e-05 | 3.762e-03 | OK | 9.599e-02 | 1.000e+00 | YES |
| 6 | 6.339043e-01 | 2.488e-08 | 3.333e-06 | OK | 9.015e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 2.488e-08
Two norm of the final step = 3.333e-06, TolX = 1.000e-06
Relative infinity norm of the final gradient = 2.488e-08, TolFun = 1.000e-06
EXIT: Local minimum found.
最適化がローカル最小値に収束したことをさらにチェックするため、fitinfo.Objective フィールドをプロットします。このフィールドには、関数最適化の各反復における負の対数密度の値が含まれています。最終的な値はどれも非常に似ているので、最適化は収束しています。
fitinfo
fitinfo = struct with fields:
Iteration: [7×1 double]
Objective: [7×1 double]
Gradient: [2×1 double]
plot(fitinfo.Iteration,fitinfo.Objective,'ro-'); xlabel('Iteration'); ylabel('Negative log density');
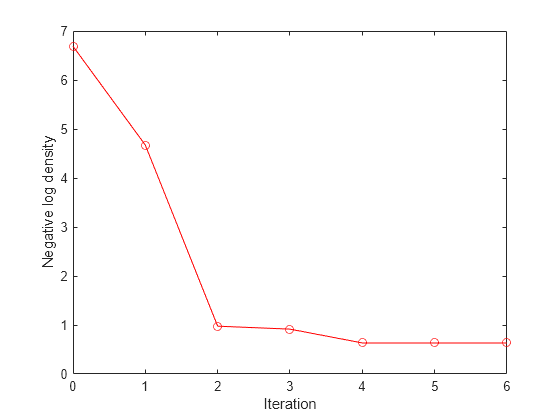
MAP 推定を表示します。当然、正しく最大値である変数 means に等しくなります。
xhat
xhat = 2×1
1.0000
-1.0000
means
means = 2×1
1
-1
関数 normalDistGrad は、startpoint と同じ長さの列ベクトルまたはスカラーとして指定された Mu に格納されている平均および Sigma に格納されている標準偏差を使用して、多変量正規確率密度の対数を返します。2 番目の出力引数は、対応する勾配です。
function [lpdf,glpdf] = normalDistGrad(X,Mu,Sigma) Z = (X - Mu)./Sigma; lpdf = sum(-log(Sigma) - .5*log(2*pi) - .5*(Z.^2)); glpdf = -Z./Sigma; end
ヒント
はじめに関数
hmcSamplerを使用してハミルトニアン モンテカルロ サンプラーを作成してから、estimateMAPを使用して MAP 点を推定します。HMC サンプラーを作成した後で、
HamiltonianSamplerクラスの他のメソッドを使用して、サンプラーの調整、標本の抽出、収束診断のチェックを行うことができます。tuneSamplerメソッドおよびdrawSamplesメソッドの開始点として MAP 推定を使用すると、調整とサンプリングの効率が向上する可能性があります。このワークフローの例については、ハミルトニアン モンテカルロの使用によるベイズ線形回帰を参照してください。
アルゴリズム
estimateMAPは、メモリ制限 Broyden-Fletcher-Goldfarb-Shanno (LBFGS) 準ニュートン オプティマイザーを使用して対数確率密度の最大値を探索します。Nocedal および Wright [1] を参照してください。
参照
[1] Nocedal, J. and S. J. Wright. Numerical Optimization, Second Edition. Springer Series in Operations Research, Springer Verlag, 2006.
バージョン履歴
R2017a で導入