FeatureSelectionNCARegression
近傍成分分析 (NCA) を使用する回帰用の特徴選択
説明
FeatureSelectionNCARegression には、近傍成分分析 (NCA) モデルのデータ、当てはめの情報、特徴量の重み、その他のモデル パラメーターが格納されます。fsrnca は、NCA を対角的に適用して特徴量の重みを学習し、FeatureSelectionNCARegression オブジェクトのインスタンスを返します。この関数は、特徴量の重みを正則化することにより特徴選択を実現します。
作成
FeatureSelectionNCARegression オブジェクトを作成するには、fsrnca を使用します。
プロパティ
オブジェクト関数
loss | 学習した特徴量の重みの精度をテスト データに対して評価 |
predict | 近傍成分分析 (NCA) 回帰モデルの使用による応答の予測 |
refit | 回帰用の近傍成分分析 (NCA) モデルの再当てはめ |
selectFeatures | Select important features for NCA classification or regression |
例
標本データを読み込みます。
load imports-85最初の 15 列には連続予測子変数が、16 列目には応答変数 (自動車の価格) が含まれています。近傍成分分析モデル用の変数を定義します。
Predictors = X(:,1:15); Y = X(:,16);
回帰用の近傍成分分析 (NCA) モデルを当てはめて、関連する特徴量を判別します。
mdl = fsrnca(Predictors,Y);
返された NCA モデル mdl は FeatureSelectionNCARegression オブジェクトです。このオブジェクトには、学習データ、モデルおよび最適化に関する情報が格納されています。このオブジェクトのプロパティ (特徴量の重みなど) には、ドット表記を使用してアクセスできます。
特徴量の重みをプロットします。
plot(mdl.FeatureWeights,"o") xlabel("Feature Index") ylabel("Feature Weight") grid on
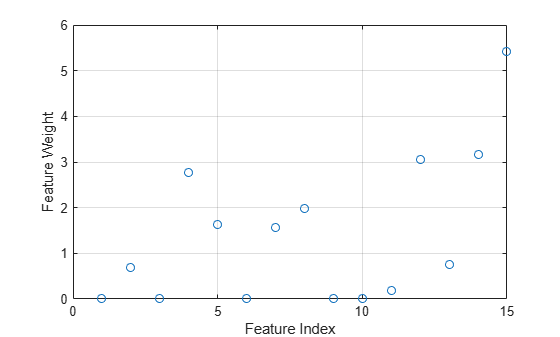
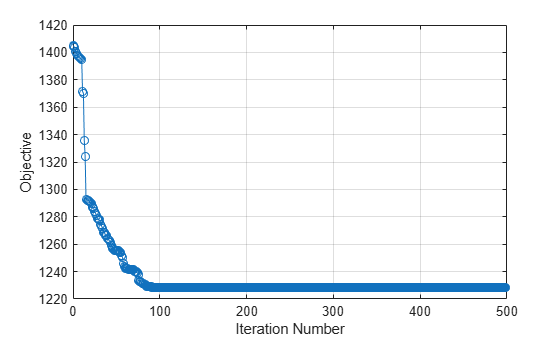
無関係な特徴量の重みはゼロになります。fsrnca を呼び出すときに Verbose=1 オプションを指定すると、最適化の情報がコマンド ラインに表示されます。目的関数と反復回数をプロットして最適化プロセスを可視化することもできます。
plot(mdl.FitInfo.Iteration,mdl.FitInfo.Objective,"o-") grid on xlabel("Iteration Number") ylabel("Objective")
ModelParameters プロパティは、モデルに関する詳細情報が含まれている struct です。このプロパティのフィールドには、ドット表記を使用してアクセスできます。たとえば、データが標準化されているかどうかを調べます。
mdl.ModelParameters.Standardize
ans = logical
0
0 は、NCA モデルを当てはめる前にデータが標準化されていないことを意味します。各予測子のスケールが非常に異なる場合は、fsrnca を呼び出すときに名前と値の引数 Standardize=true を使用して予測子を標準化することができます。
バージョン履歴
R2016b で導入
参考
predict | fsrnca | refit | loss | selectFeatures