edge
一般化加法モデル (GAM) の分類エッジ
説明
e = edge(Mdl,Tbl,ResponseVarName)Tbl 内の予測子データと Tbl.ResponseVarName 内の真のクラス ラベルを使用して、一般化加法モデル Mdl の分類エッジ (e) を返します。
e = edge(___,Name,Value)
例
一般化加法モデルのテスト標本分類マージンおよびエッジを推定します。テスト標本マージンは観測された真のクラスのスコアから偽のクラスのスコアを差し引いたもので、テスト標本エッジはマージンの平均です。
fisheriris データ セットを読み込みます。versicolor と virginica のアヤメについての 2 つのがく片と 2 つの花弁の測定値が含まれる数値行列 X を作成します。対応するアヤメの種類が含まれる文字ベクトルの cell 配列 Y を作成します。
load fisheriris inds = strcmp(species,'versicolor') | strcmp(species,'virginica'); X = meas(inds,:); Y = species(inds,:);
Y のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。テスト用の 30% のホールドアウト標本を指定します。
rng('default') % For reproducibility cv = cvpartition(Y,'HoldOut',0.30);
学習インデックスとテスト インデックスを抽出します。
trainInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
予測子 XTrain とクラス ラベル YTrain を使用して、GAM に学習させます。クラス名を指定することが推奨されます。
Mdl = fitcgam(XTrain,YTrain,'ClassNames',{'versicolor','virginica'});
Mdl は ClassificationGAM モデル オブジェクトです。
テスト標本分類マージンおよびエッジを推定します。
m = margin(Mdl,XTest,YTest); e = edge(Mdl,XTest,YTest)
e = 0.8000
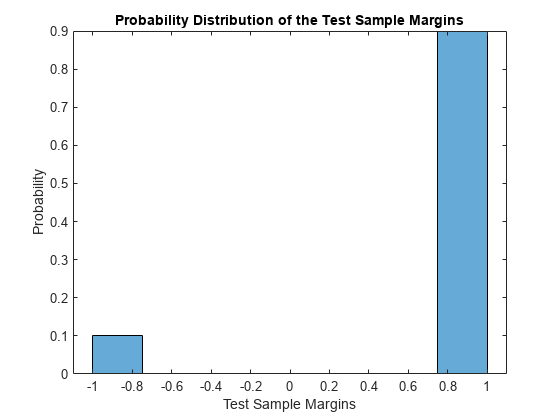
テスト標本分類マージンのヒストグラムを表示します。
histogram(m,length(unique(m)),'Normalization','probability') xlabel('Test Sample Margins') ylabel('Probability') title('Probability Distribution of the Test Sample Margins')
一般化加法モデルのテスト標本加重エッジ (マージンの加重平均) を推定します。
fisheriris データ セットを読み込みます。versicolor と virginica のアヤメについての 2 つのがく片と 2 つの花弁の測定値が含まれる数値行列 X を作成します。対応するアヤメの種類が含まれる文字ベクトルの cell 配列 Y を作成します。
load fisheriris idx1 = strcmp(species,'versicolor') | strcmp(species,'virginica'); X = meas(idx1,:); Y = species(idx1,:);
一部の測定値の品質は、旧式のテクノロジーが測定に使用されたために低いと仮定します。この効果をシミュレートするために、20 個の測定値で構成されるランダムなサブセットにノイズを追加します。
rng('default') % For reproducibility idx2 = randperm(size(X,1),20); X(idx2,:) = X(idx2,:) + 2*randn(20,size(X,2));
Y のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。テスト用の 30% のホールドアウト標本を指定します。
cv = cvpartition(Y,'HoldOut',0.30);学習インデックスとテスト インデックスを抽出します。
trainInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
予測子 XTrain とクラス ラベル YTrain を使用して、GAM に学習させます。クラス名を指定することが推奨されます。
Mdl = fitcgam(XTrain,YTrain,'ClassNames',{'versicolor','virginica'});
Mdl は ClassificationGAM モデル オブジェクトです。
テスト標本エッジを推定します。
e = edge(Mdl,XTest,YTest)
e = 0.8000
平均マージンは約 0.80 です。
ノイズを含む測定値の影響を減らす方法の 1 つは、他の観測値よりも低く重み付けすることです。品質が高い観測値には、他の観測値の 2 倍の重みを与える重みベクトルを定義します。
n = size(X,1); weights = ones(size(X,1),1); weights(idx2) = 0.5; weightsTrain = weights(trainInds); weightsTest = weights(testInds);
予測子 XTrain、クラス ラベル YTrain、および重み weightsTrain を使用して、GAM に学習させます。
Mdl_W = fitcgam(XTrain,YTrain,'Weights',weightsTrain,... 'ClassNames',{'versicolor','virginica'});
加重スキームを使用して、テスト標本の加重エッジを推定します。
e_W = edge(Mdl_W,XTest,YTest,'Weights',weightsTest)e_W = 0.8770
加重平均マージンは約 0.88 です。この結果は、平均すると、加重分類器ラベルのラベルの方が信頼度が高いことを示します。
テスト標本マージンおよびエッジを調べて、線形項が含まれる GAM を線形項と交互作用項の両方が含まれる GAM と比較します。この比較のみに基づくと、マージンおよびエッジが最大である分類器が最適なモデルです。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereY のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。テスト用の 30% のホールドアウト標本を指定します。
rng('default') % For reproducibility cv = cvpartition(Y,'Holdout',0.30);
学習インデックスとテスト インデックスを抽出します。
trainInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
予測子の線形項と交互作用項の両方が格納されている GAM に学習させます。p 値が 0.05 以下である利用可能な交互作用項をすべて含めるように指定します。
Mdl = fitcgam(XTrain,YTrain,'Interactions','all','MaxPValue',0.05)
Mdl =
ClassificationGAM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'logit'
Intercept: 3.0398
Interactions: [561×2 double]
NumObservations: 246
Properties, Methods
Mdl は ClassificationGAM モデル オブジェクトです。Mdl には利用可能なすべての交互作用項が含まれています。
Mdl のテスト標本マージンおよびエッジを推定します。
M = margin(Mdl,XTest,YTest); E = edge(Mdl,XTest,YTest)
E = 0.7848
交互作用項を含めずに Mdl のテスト標本マージンおよびエッジを推定します。
M_nointeractions = margin(Mdl,XTest,YTest,'IncludeInteractions',false); E_nointeractions = edge(Mdl,XTest,YTest,'IncludeInteractions',false)
E_nointeractions = 0.7871
箱ひげ図を使用してマージンの分布を表示します。
boxplot([M M_nointeractions],'Labels',{'Linear and Interaction Terms','Linear Terms Only'}) title('Box Plots of Test Sample Margins')

マージン M と M_nointeractions は同様の分布を示しますが、線形項のみを含む分類器のテスト標本エッジの方が大きくなります。分類器のマージンは比較的大きいことが推奨されます。
入力引数
名前と値の引数
詳細
バージョン履歴
R2021a で導入