音声信号圧縮のための DCT
この例では、離散コサイン変換 (DCT) を使用した音声信号の圧縮方法を説明します。
女性と男性が発声する「strong」という単語が含まれているファイルを読み込みます。この信号は 8 kHz でサンプリングされています。
load('strong.mat') % To hear, type soundsc(her,fs), pause(1), soundsc(him,fs)
離散コサイン変換を使用して、女性の音声信号を圧縮します。信号を DCT 基底ベクトルに分解します。分解構造の項は、信号内のサンプルと同数になります。ベクトル X の展開係数は、各成分に蓄積されたエネルギー量を調整します。係数を一番大きいものから順に並べ替えます。
x = her';
X = dct(x);
[XX,ind] = sort(abs(X),'descend');信号のエネルギーの 99.9% がいくつの DCT 係数で表されるかを求めます。その数を全体に対するパーセント比で表現します。
need = 1; while norm(X(ind(1:need)))/norm(X)<0.999 need = need+1; end xpc = need/length(X)*100;
残りの 0.1% のエネルギーを含む係数を 0 に設定します。圧縮表現から信号を再構成します。元の信号、再構成した信号および 2 つの差分をプロットします。
X(ind(need+1:end)) = 0; xx = idct(X); plot([x;xx;x-xx]') legend('Original',[int2str(xpc) '% of coeffs.'],'Difference', ... 'Location','best')
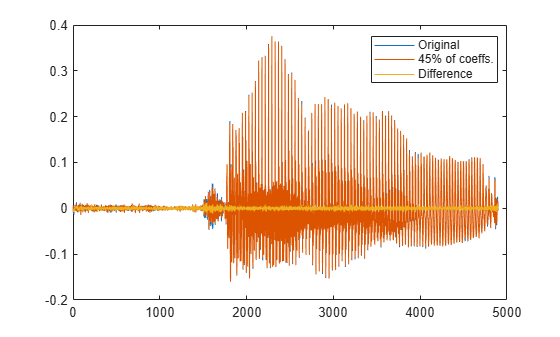
% To hear, type soundsc(x,fs), pause(1), soundsc(xx,fs)男性の音声について解析を繰り返します。エネルギーの 99.9% がいくつの DCT 係数で表されるかを求め、その数を全体に対するパーセント比で表現します。
y = him'; Y = dct(y); [YY,ind] = sort(abs(Y),'descend'); need = 1; while norm(Y(ind(1:need)))/norm(Y)<0.999 need = need+1; end ypc = need/length(Y)*100;
残りの係数を 0 に設定し、圧縮されたバージョンから信号を再構成します。元の信号、再構成した信号および 2 つの差分をプロットします。
Y(ind(need+1:end)) = 0; yy = idct(Y); plot([y;yy;y-yy]') legend('Original',[int2str(ypc) '% of coeffs.'],'Difference', ... 'Location','best')
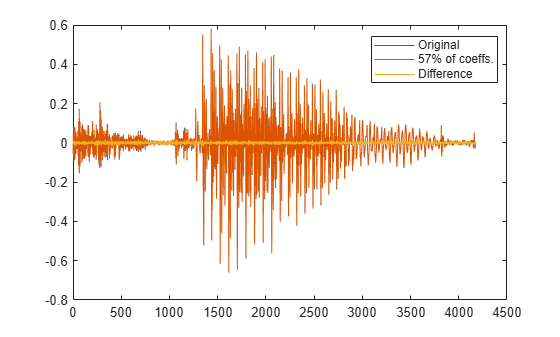
% To hear, type soundsc(y,fs), pause(1), soundsc(yy,fs)どちらの場合も、音声信号を適度に再構成するには約半数の DCT 係数で十分です。求められるエネルギーの割合が 99% である場合、必要な係数の数は全体の約 20% に減少します。再構成の結果は劣りますが、聞き取りは可能です。
上記のサンプルとその他のサンプルの解析から、男性の音声の方が女性よりも特徴付けに多くの係数を必要とすることがわかります。