このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
GPU を使用した相関の高速化
この例では、GPU を使用して相互相関を高速化する方法を示します。相関問題の多くは、大規模なデータセットを扱うことから、GPU の使用によりより高速な解決が可能です。この例では、Parallel Computing Toolbox™ のユーザー ライセンスが必要です。どの GPU がサポートされているかについては、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
はじめに
まず、ご使用のマシンの GPU の基本的な情報を学習します。GPU にアクセスするには、Parallel Computing Toolbox を使用します。
fprintf('Benchmarking GPU-accelerated Cross-Correlation.\n'); if ~(parallel.gpu.GPUDevice.isAvailable) fprintf(['\n\t**GPU not available. Stopping.**\n']); return; else dev = gpuDevice; fprintf(... 'GPU detected (%s, %d multiprocessors, Compute Capability %s)',... dev.Name, dev.MultiprocessorCount, dev.ComputeCapability); end
Benchmarking GPU-accelerated Cross-Correlation. GPU detected (TITAN Xp, 30 multiprocessors, Compute Capability 6.1)
ベンチマーク機能
CPU 用に書かれたコードは GPU に移植して実行できるため、1 つの関数を CPU と GPU の両方のベンチマークに利用できます。ただし、GPU 上のコードは CPU とは非同期に実行されるため、性能測定には特別な注意が必要です。ある関数の実行に要した時間を測定する前に、すべての GPU 処理が終了しているか、デバイス上で 'wait' メソッドを実行して確認します。この追加の呼び出しは、CPU の性能には影響を与えません。
この例では、3 つの異なるタイプの相互相関のベンチマークを行います。
単純な相互相関のベンチマーク
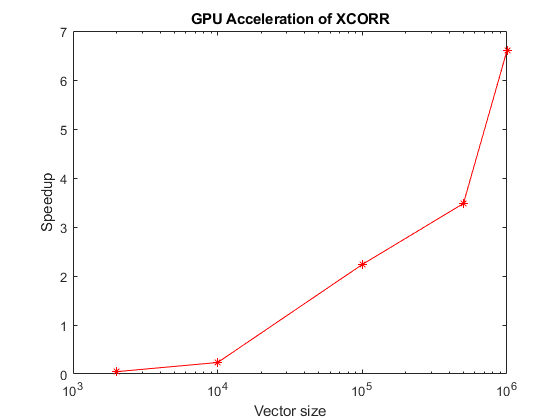
最初の例として、同じサイズの 2 つのベクトルが構文 xcorr(u,v) を使用して相互相関されています。GPU 実行時間に対する CPU 実行時間の比は、ベクトルのサイズに対してプロットされています。
fprintf('\n\n *** Benchmarking vector-vector cross-correlation*** \n\n'); fprintf('Benchmarking function :\n'); type('benchXcorrVec'); fprintf('\n\n'); sizes = [2000 1e4 1e5 5e5 1e6]; tc = zeros(1,numel(sizes)); tg = zeros(1,numel(sizes)); numruns = 10; for s=1:numel(sizes); fprintf('Running xcorr of %d elements...\n', sizes(s)); delchar = repmat('\b', 1,numruns); a = rand(sizes(s),1); b = rand(sizes(s),1); tc(s) = benchXcorrVec(a, b, numruns); fprintf([delchar '\t\tCPU time : %.2f ms\n'], 1000*tc(s)); tg(s) = benchXcorrVec(gpuArray(a), gpuArray(b), numruns); fprintf([delchar '\t\tGPU time : %.2f ms\n'], 1000*tg(s)); end %Plot the results fig = figure; ax = axes('parent', fig); semilogx(ax, sizes, tc./tg, 'r*-'); ylabel(ax, 'Speedup'); xlabel(ax, 'Vector size'); title(ax, 'GPU Acceleration of XCORR'); drawnow;
*** Benchmarking vector-vector cross-correlation***
Benchmarking function :
function t = benchXcorrVec(u,v, numruns)
%Used to benchmark xcorr with vector inputs on the CPU and GPU.
% Copyright 2012 The MathWorks, Inc.
timevec = zeros(1,numruns);
gdev = gpuDevice;
for ii=1:numruns
ts = tic;
o = xcorr(u,v); %#ok<NASGU>
wait(gdev)
timevec(ii) = toc(ts);
fprintf('.');
end
t = min(timevec);
end
Running xcorr of 2000 elements...
CPU time : 0.21 ms
GPU time : 4.26 ms
Running xcorr of 10000 elements...
CPU time : 1.03 ms
GPU time : 4.37 ms
Running xcorr of 100000 elements...
CPU time : 14.04 ms
GPU time : 6.28 ms
Running xcorr of 500000 elements...
CPU time : 55.98 ms
GPU time : 16.09 ms
Running xcorr of 1000000 elements...
CPU time : 169.00 ms
GPU time : 25.60 ms
行列の列の相互相関のベンチマーク
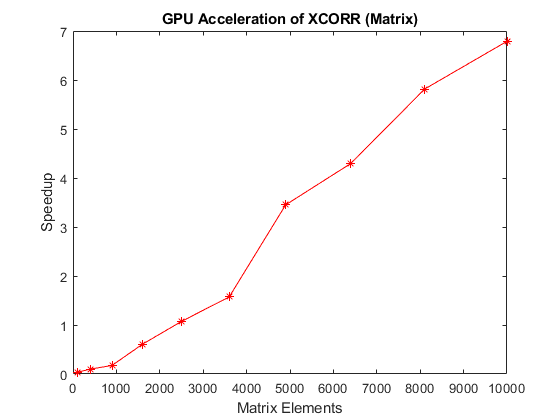
2 番目の例として、行列 A の列が、構文 xcorr(A) を使用して対相互相関され、すべての相関からなる大きな行列出力が生成されています。CPU の実行時間と GPU の実行時間の比率は、行列 A のサイズに対してプロットされています。
fprintf('\n\n *** Benchmarking matrix column cross-correlation*** \n\n'); fprintf('Benchmarking function :\n'); type('benchXcorrMatrix'); fprintf('\n\n'); sizes = floor(linspace(0,100, 11)); sizes(1) = []; tc = zeros(1,numel(sizes)); tg = zeros(1,numel(sizes)); numruns = 10; for s=1:numel(sizes); fprintf('Running xcorr (matrix) of a %d x %d matrix...\n', sizes(s), sizes(s)); delchar = repmat('\b', 1,numruns); a = rand(sizes(s)); tc(s) = benchXcorrMatrix(a, numruns); fprintf([delchar '\t\tCPU time : %.2f ms\n'], 1000*tc(s)); tg(s) = benchXcorrMatrix(gpuArray(a), numruns); fprintf([delchar '\t\tGPU time : %.2f ms\n'], 1000*tg(s)); end %Plot the results fig = figure; ax = axes('parent', fig); plot(ax, sizes.^2, tc./tg, 'r*-'); ylabel(ax, 'Speedup'); xlabel(ax, 'Matrix Elements'); title(ax, 'GPU Acceleration of XCORR (Matrix)'); drawnow;
*** Benchmarking matrix column cross-correlation***
Benchmarking function :
function t = benchXcorrMatrix(A, numruns)
%Used to benchmark xcorr with Matrix input on CPU and GPU.
% Copyright 2012 The MathWorks, Inc.
timevec = zeros(1,numruns);
gdev = gpuDevice;
for ii=1:numruns,
ts = tic;
o = xcorr(A); %#ok<NASGU>
wait(gdev)
timevec(ii) = toc(ts);
fprintf('.');
end
t = min(timevec);
end
Running xcorr (matrix) of a 10 x 10 matrix...
CPU time : 0.18 ms
GPU time : 5.00 ms
Running xcorr (matrix) of a 20 x 20 matrix...
CPU time : 0.48 ms
GPU time : 4.83 ms
Running xcorr (matrix) of a 30 x 30 matrix...
CPU time : 0.85 ms
GPU time : 4.84 ms
Running xcorr (matrix) of a 40 x 40 matrix...
CPU time : 3.38 ms
GPU time : 5.57 ms
Running xcorr (matrix) of a 50 x 50 matrix...
CPU time : 5.60 ms
GPU time : 5.22 ms
Running xcorr (matrix) of a 60 x 60 matrix...
CPU time : 8.49 ms
GPU time : 5.39 ms
Running xcorr (matrix) of a 70 x 70 matrix...
CPU time : 20.43 ms
GPU time : 5.92 ms
Running xcorr (matrix) of a 80 x 80 matrix...
CPU time : 26.79 ms
GPU time : 6.24 ms
Running xcorr (matrix) of a 90 x 90 matrix...
CPU time : 40.04 ms
GPU time : 6.89 ms
Running xcorr (matrix) of a 100 x 100 matrix...
CPU time : 49.69 ms
GPU time : 7.32 ms
2 次元の相互相関のベンチマーク
最後の例として、X と Y の 2 つの行列が xcorr2(X,Y) を使用して相互相関されています。X のサイズは固定されており、Y のサイズは可変です。2 番目の行列のサイズに対する speedup の値がプロットされています。
fprintf('\n\n *** Benchmarking 2-D cross-correlation*** \n\n'); fprintf('Benchmarking function :\n'); type('benchXcorr2'); fprintf('\n\n'); sizes = [100, 200, 500, 1000, 1500, 2000]; tc = zeros(1,numel(sizes)); tg = zeros(1,numel(sizes)); numruns = 4; a = rand(100); for s=1:numel(sizes); fprintf('Running xcorr2 of a 100x100 matrix and %d x %d matrix...\n', sizes(s), sizes(s)); delchar = repmat('\b', 1,numruns); b = rand(sizes(s)); tc(s) = benchXcorr2(a, b, numruns); fprintf([delchar '\t\tCPU time : %.2f ms\n'], 1000*tc(s)); tg(s) = benchXcorr2(gpuArray(a), gpuArray(b), numruns); fprintf([delchar '\t\tGPU time : %.2f ms\n'], 1000*tg(s)); end %Plot the results fig = figure; ax =axes('parent', fig); semilogx(ax, sizes.^2, tc./tg, 'r*-'); ylabel(ax, 'Speedup'); xlabel(ax, 'Matrix Elements'); title(ax, 'GPU Acceleration of XCORR2'); drawnow; fprintf('\n\nBenchmarking completed.\n\n');
*** Benchmarking 2-D cross-correlation***
Benchmarking function :
function t = benchXcorr2(X, Y, numruns)
%Used to benchmark xcorr2 on the CPU and GPU.
% Copyright 2012 The MathWorks, Inc.
timevec = zeros(1,numruns);
gdev = gpuDevice;
for ii=1:numruns,
ts = tic;
o = xcorr2(X,Y); %#ok<NASGU>
wait(gdev)
timevec(ii) = toc(ts);
fprintf('.');
end
t = min(timevec);
end
Running xcorr2 of a 100x100 matrix and 100 x 100 matrix...
CPU time : 20.35 ms
GPU time : 6.96 ms
Running xcorr2 of a 100x100 matrix and 200 x 200 matrix...
CPU time : 42.87 ms
GPU time : 11.72 ms
Running xcorr2 of a 100x100 matrix and 500 x 500 matrix...
CPU time : 125.23 ms
GPU time : 39.67 ms
Running xcorr2 of a 100x100 matrix and 1000 x 1000 matrix...
CPU time : 386.59 ms
GPU time : 88.46 ms
Running xcorr2 of a 100x100 matrix and 1500 x 1500 matrix...
CPU time : 788.38 ms
GPU time : 165.04 ms
Running xcorr2 of a 100x100 matrix and 2000 x 2000 matrix...
CPU time : 1523.05 ms
GPU time : 279.55 ms
Benchmarking completed.

GPU により高速化されたその他の信号処理関数
GPU 上で実行できるその他の信号処理関数がいくつかあります。これらの関数には、fft、ifft、conv、filter、fftfilt などが含まれます。場合によっては、CPU に対しかなりの高速化が達成できます。GPU によって高速化された信号処理関数すべての一覧については、Signal Processing Toolbox™ ドキュメンテーションのGPU アルゴリズムの高速化の節を参照してください。
参考
gather (Parallel Computing Toolbox) | gpuArray (Parallel Computing Toolbox) | xcorr
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)