MEX を使用した高度な CUDA 機能へのアクセス
この例では、MEX ファイルを使用して GPU の高度な機能にアクセスする方法を示します。GPU でのステンシル演算の例を基にして説明します。この前出の例では Conway の "ライフ ゲーム" を使用して、GPU で実行される MATLAB® コードでステンシル演算を実行する方法を示しました。ここでの例では、GPU の高度な機能を使用してステンシル演算のパフォーマンスをさらに高める方法を示します。その機能とは、共有メモリです。これを実行するには、独自の CUDA® コードを MEX ファイルに作成し、その MEX ファイルを MATLAB から呼び出します。MEX ファイルにおける GPU の使用の紹介は、CUDA コードを含む MEX 関数の実行に記載されています。
前の例で定義されたように、"ステンシル演算" では出力配列の各要素が入力配列の小さな領域によって決まります。例としては、有限差分、畳み込み、メディアン フィルター処理、有限要素法などが挙げられます。ステンシル演算がワークフローの主要部分であれば、この演算を手書きで CUDA カーネルに変換できます。この例では Conway の "ライフ ゲーム" をステンシル演算として使用し、計算を MEX ファイルへと移します。したがって、この場合の "ステンシル" は、各要素を囲む 3 行 3 列の領域となります。
"ライフ ゲーム" ではいくつかの簡単なルールに従います。
セルは 2 次元グリッドに並べられる
各ステップで、それぞれのセルの運命は隣接する 8 つのセルの生命力によって決定される
あるセルが、生命をもつ 3 つのセルと隣接していると次のステップで生命を得る
生命をもつセルが、生命をもつ 2 つのセルと隣接していると、次のステップで生命が維持される
他のセルはすべて (生命をもつ隣接セルが 3 つを超える場合を含め) 次のステップで生命を失うか、空のままとなる
ランダムな初期集団の生成
2 次元グリッド上に、およそ 25% の位置が生命をもつようにセルの初期集団を作成します。
gridSize = 500; numGenerations = 200; initialGrid = (rand(gridSize,gridSize) > .75); hold off imagesc(initialGrid); colormap([1 1 1;0 0.5 0]); title('Initial Grid');

MATLAB でのベースライン GPU バージョンの作成
パフォーマンスのベースラインを得るため、"Experiments with MATLAB" で説明されている初期実装から開始します。gpuArrayを使用して初期集団を必ず GPU に配置することにより、この実装を GPU で実行します。この例の最後に関数 updateGrid を示しています。updateGrid は、生命をもつ隣接セルの数をカウントし、セルが次のステップで生命をもつかどうかを判定します。
currentGrid = gpuArray(initialGrid); % Loop through each generation updating the grid and displaying it for generation = 1:numGenerations currentGrid = updateGrid(currentGrid, gridSize); imagesc(currentGrid); title(num2str(generation)); drawnow end

ゲームを再度実行し、各世代にどのくらい時間を要するかを測定します。gputimeit を使用してゲーム全体の時間を測定するために、各世代を呼び出す関数 callUpdateGrid をこの例の最後に示しています。
gpuInitialGrid = gpuArray(initialGrid); % Retain this result to verify the correctness of each version below expectedResult = callUpdateGrid(gpuInitialGrid, gridSize, numGenerations); gpuBuiltinsTime = gputimeit(@() callUpdateGrid(gpuInitialGrid, ... gridSize, numGenerations)); fprintf('Average time on the GPU: %2.3fms per generation \n', ... 1000*gpuBuiltinsTime/numGenerations);
Average time on the GPU: 0.500ms per generation
共有メモリを使用する MEX バージョンの作成
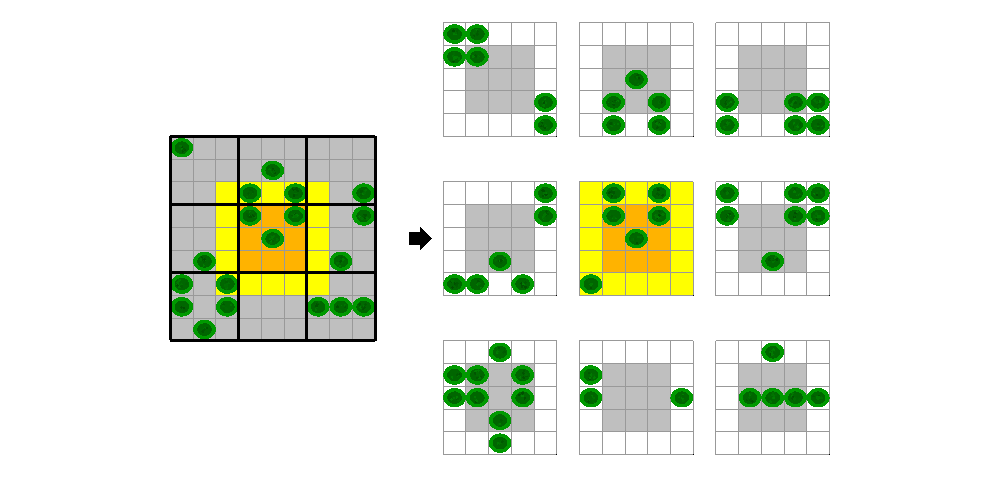
ステンシル演算の CUDA カーネル バージョンを作成する際は、入力データをブロックに分割し、それに対し各スレッド ブロックが演算を行えるようにしなければなりません。ブロックの各スレッドは、ブロックの他のスレッドでも必要とされるデータを読み取ります。読み取り操作の数を最小化する 1 つの方法は、必要な入力データを処理前に共有メモリにコピーすることです。ブロックの境目の計算を正しく行うために、このコピーには一部の隣接する要素も含めなければなりません。ライフ ゲームで、ステンシルが 3 行 3 列からなる要素の正方形であるとすると、1 要素分の境界が必要になります。たとえば、9 行 9 列のグリッドを 3 行 3 列のブロックを使用して処理する場合では、5 番目のブロックはオレンジ色で強調表示された範囲で処理され、黄色の要素が読み取りが必要な "黄色い枠" となります。
このアプローチを表す CUDA コードは、サポート ファイル pctdemo_life_cuda_shmem.cu に示されています。このサポート ファイルにアクセスするには、この例をライブ スクリプトとして開きます。このファイルの CUDA デバイス関数は次のように動作します。
すべてのスレッドは入力グリッドの関連部分を、黄色い枠の部分も含めて共有メモリにコピーする。
スレッドが互いに同期して、共有メモリの準備が完了していることを確認する。
出力グリッドに適合するスレッドは、ライフ ゲームの計算を実行する。
このファイルのホスト コードは、CUDA ランタイム API を使用して、CUDA デバイス関数を世代ごとに 1 回呼び出します。このコードでは、入力用と出力用に 2 つの異なる書き込み可能なバッファーが使用されます。すべての反復に際して MEX ファイルは入力と出力のポインターを入れ替えるため、コピーは必要ありません。
この関数を MATLAB から呼び出すには MEX ゲートウェイが必要です。このゲートウェイは、入力配列を MATLAB からアンラップし、GPU にワークスペースを作成し、出力を返します。MEX ゲートウェイ関数は、サポート ファイル pctdemo_life_mex_shmem.cpp にあります。
独自の MEX ファイルを呼び出すには、最初にmexcudaを使用してコンパイルしなければなりません。pctdemo_life_cuda_shmem.cu と pctdemo_life_mex_shmem.cpp を pctdemo_life_mex_shmem という MEX 関数にコンパイルします。
mexcuda -output pctdemo_life_mex_shmem pctdemo_life_cuda_shmem.cu pctdemo_life_mex_shmem.cpp
Building with 'NVIDIA CUDA Compiler'. MEX completed successfully.
% Calculate the output value using the MEX file with shared memory. The % initial input value is copied to the GPU inside the MEX file grid = pctdemo_life_mex_shmem(initialGrid, numGenerations); gpuMexTime = gputimeit(@()pctdemo_life_mex_shmem(initialGrid, ... numGenerations)); % Print out the average computation time and check the result is unchanged fprintf('Average time of %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuMexTime/numGenerations, gpuBuiltinsTime/gpuMexTime);
Average time of 0.048ms per generation (10.4x faster).
assert(isequal(grid, expectedResult));
まとめ
この例では、処理前にブロックを共有メモリに明示的にコピーすることで読み取り操作の数を減らす方法について説明しました。この方法を使用して得られるパフォーマンスの改善は、ステンシルのサイズ、オーバーラップする領域のサイズ、GPU の性能によって異なります。このアプローチを MATLAB コードと共に使用して、アプリケーションを最適化できます。
fprintf('Using gpuArrays: %2.3fms per generation.\n', ... 1000*gpuBuiltinsTime/numGenerations);
Using gpuArrays: 0.500ms per generation.
fprintf(['Using MEX with shared memory: %2.3fms per generation ',... '(%1.1fx faster).\n'], 1000*gpuMexTime/numGenerations, ... gpuBuiltinsTime/gpuMexTime);
Using MEX with shared memory: 0.048ms per generation (10.4x faster).
サポート関数
次の関数 updateGrid は、生命をもつ隣接セルの数に応じて 2 次元グリッドを更新します。
function X = updateGrid(X, N) p = [1 1:N-1]; q = [2:N N]; % Count how many of the eight neighbors are alive neighbors = X(:,p) + X(:,q) + X(p,:) + X(q,:) + ... X(p,p) + X(q,q) + X(p,q) + X(q,p); % A live cell with two live neighbors, or any cell with % three live neighbors, is alive at the next step X = (X & (neighbors == 2)) | (neighbors == 3); end
関数 callUpdateGrid は、複数の世代について updateGrid を呼び出します。
function grid=callUpdateGrid(grid, gridSize, N) for gen = 1:N grid = updateGrid(grid, gridSize); end end
参考
gpuArray | mexcuda | gputimeit