centrality
ノードの重要度を測定
説明
例
架空の 6 件の Web サイトを含むグラフを作成し、プロットします。
s = [1 1 2 2 3 3 3 4 5];
t = [2 5 3 4 4 5 6 1 1];
names = {'http://www.example.com/alpha', 'http://www.example.com/beta', ...
'http://www.example.com/gamma', 'http://www.example.com/delta', ...
'http://www.example.com/epsilon', 'http://www.example.com/zeta'};
G = digraph(s,t,[],names);
plot(G,'NodeLabel',{'alpha','beta','gamma','delta','epsilon','zeta'})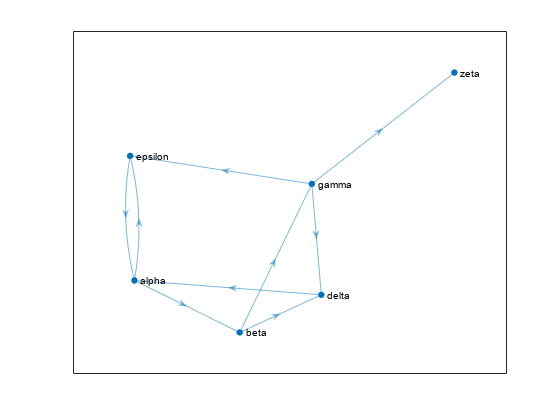
関数 centrality を使用して、各 Web サイトのページ ランクを計算します。この情報を、グラフの Nodes table にグラフ ノードの属性として追加します。
pg_ranks = centrality(G,'pagerank')pg_ranks = 6×1
0.3210
0.1706
0.1066
0.1368
0.2008
0.0643
G.Nodes.PageRank = pg_ranks; G.Nodes
ans=6×2 table
Name PageRank
__________________________________ ________
{'http://www.example.com/alpha' } 0.32098
{'http://www.example.com/beta' } 0.17057
{'http://www.example.com/gamma' } 0.10657
{'http://www.example.com/delta' } 0.13678
{'http://www.example.com/epsilon'} 0.20078
{'http://www.example.com/zeta' } 0.06432
また、centrality を使用してハブとオーソリティのノードを判別し、そのスコアを Nodes table に追加します。
hub_ranks = centrality(G,'hubs'); auth_ranks = centrality(G,'authorities'); G.Nodes.Hubs = hub_ranks; G.Nodes.Authorities = auth_ranks;
G.Nodes
ans=6×4 table
Name PageRank Hubs Authorities
__________________________________ ________ __________ ___________
{'http://www.example.com/alpha' } 0.32098 0.24995 7.3237e-05
{'http://www.example.com/beta' } 0.17057 0.24995 0.099993
{'http://www.example.com/gamma' } 0.10657 0.49991 0.099993
{'http://www.example.com/delta' } 0.13678 9.1536e-05 0.29998
{'http://www.example.com/epsilon'} 0.20078 9.1536e-05 0.29998
{'http://www.example.com/zeta' } 0.06432 0 0.19999
乱数のスパース隣接行列を使用して重み付きグラフを作成し、プロットします。エッジが多数あるため、EdgeAlpha に非常に小さい値を使用して、エッジをほぼ透明にします。
A = sprand(1000,1000,0.15); A = A + A'; G = graph(A,'omitselfloops'); p = plot(G,'Layout','force','EdgeAlpha',0.005,'NodeColor','r');

各ノードの次数中心性を計算します。エッジの重みを使用して、各エッジの重要度を指定します。
deg_ranks = centrality(G,'degree','Importance',G.Edges.Weight);
discretize を使用して、中心性スコアを基にノードを 7 つの等間隔のビンに入れます。
edges = linspace(min(deg_ranks),max(deg_ranks),7); bins = discretize(deg_ranks,edges);
プロット内の各ノードのサイズを、その中心性スコアに比例するように指定します。各ノードのマーカー サイズは、ビン番号 (1 ~ 7) に等しくなります。
p.MarkerSize = bins;

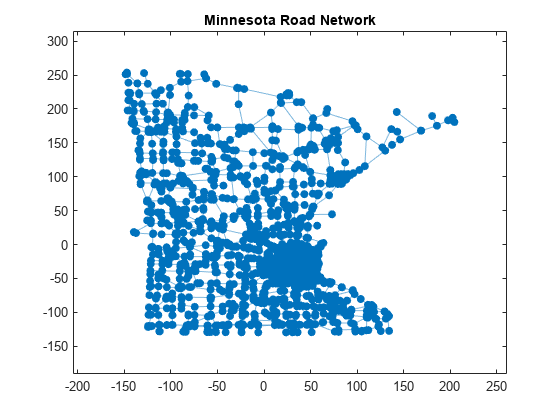
ミネソタ州の道路網を表すグラフ オブジェクト G が含まれている、minnesota.mat のデータを読み込みます。グラフ ノードは xy 座標をもち、G.Nodes table の変数 XCoord と変数 YCoord に格納されています。
load minnesota.mat
xy = [G.Nodes.XCoord G.Nodes.YCoord];道路の長さにほぼ対応するエッジの重みをグラフに追加します。これは、各エッジの終了ノードの xy 座標間におけるユークリッド距離を使用して算出します。
[s,t] = findedge(G); G.Edges.Weight = hypot(xy(s,1)-xy(t,1), xy(s,2)-xy(t,2));
ノードの xy 座標を使用してグラフをプロットします。
p = plot(G,'XData',xy(:,1),'YData',xy(:,2),'MarkerSize',5); title('Minnesota Road Network')
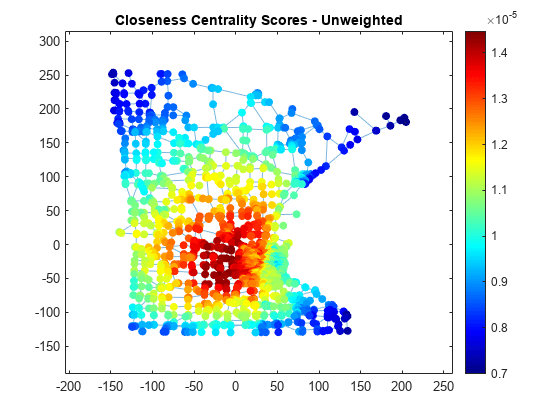
各ノードの近接中心性を計算します。ノードの色 NodeCData を、中心性スコアに比例するようにスケーリングします。
ucc = centrality(G,'closeness'); p.NodeCData = ucc; colormap jet colorbar title('Closeness Centrality Scores - Unweighted')
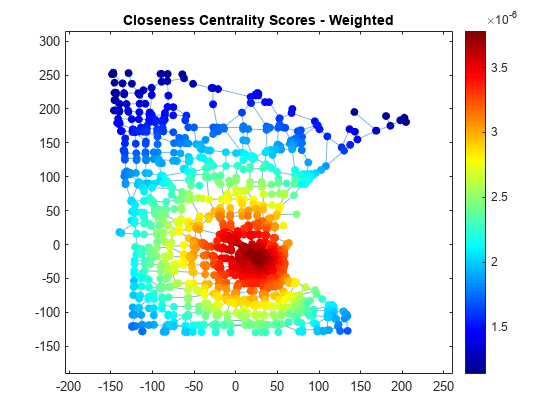
また、各エッジを通過するコストとしてエッジの重みを使用し、重み付きの近接中心性スコアを計算します。道路の長さをエッジの重みとして使用することにより、スコアの質が向上します。これは、移動したエッジ数ではなく、移動したすべてのエッジの合計長さとして距離が測定されるからです。
wcc = centrality(G,'closeness','Cost',G.Edges.Weight); p.NodeCData = wcc; title('Closeness Centrality Scores - Weighted')
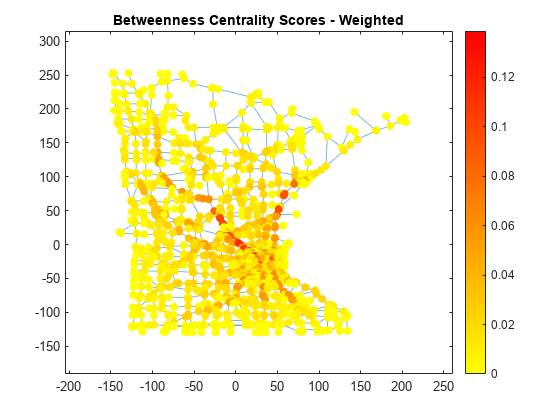
グラフで重み付き媒介中心性スコアを計算して、2 つのノード間の最短経路で最も頻繁に検出される道路を判定します。2 つのランダムなノード間の最短経路を通る旅行者が特定のノードを経由する確率をスコアが表すように、係数 を使用して中心性スコアを正規化します。このプロットは、都市に出入りする非常に重要な道路がいくつかあることを示します。
wbc = centrality(G,'betweenness','Cost',G.Edges.Weight); n = numnodes(G); p.NodeCData = 2*wbc./((n-2)*(n-1)); colormap(flip(autumn,1)); title('Betweenness Centrality Scores - Weighted')
入力引数
名前と値の引数
出力引数
拡張機能
バージョン履歴
R2016a で導入