数値特徴量を使用したネットワークの学習
この例では、深層学習による特徴データ分類用のシンプルなニューラル ネットワークを作成し、学習を行う方法を説明します。
数値特徴量のデータ セット (空間次元や時間次元のない数値データの集合など) がある場合、特徴入力層を使用して深層学習ネットワークに学習させることができます。イメージ分類用のネットワークに学習させる方法を示す例については、分類用のシンプルな深層学習ニューラル ネットワークの作成を参照してください。
この例では、数値センサーの読み取り値、統計量、カテゴリカル ラベルの混合を所与として、トランスミッション システムの歯車の状態を分類するよう、ネットワークに学習させる方法について説明します。
データの読み込み
学習用のトランスミッション ケーシング データセットを読み込みます。このデータ セットには、以下のような 18 種類の読み取り値と 3 種類のカテゴリカル ラベルで構成される、トランスミッション システムの 208 個の合成読み取り値が含まれています。
SigMean— 振動信号の平均SigMedian— 振動信号の中央値SigRMS— 振動信号の RMSSigVar— 振動信号の分散SigPeak— 振動信号のピークSigPeak2Peak— 振動信号のピーク ツー ピークSigSkewness— 振動信号の歪度SigKurtosis— 振動信号の尖度SigCrestFactor— 振動信号のクレスト ファクターSigMAD— 振動信号の MADSigRangeCumSum— 振動信号の範囲累積和SigCorrDimension— 振動信号の相関次元SigApproxEntropy— 振動信号の近似エントロピーSigLyapExponent— 振動信号のリアプノフ指数PeakFreq— ピーク周波数。HighFreqPower— 高周波のべき乗EnvPower— 環境のべき乗PeakSpecKurtosis— スペクトル尖度のピーク周波数SensorCondition— センサーの状態。"Sensor Drift" または "No Sensor Drift" として指定します。ShaftCondition— シャフトの状態。"Shaft Wear" または "No Shaft Wear" として指定します。GearToothCondition— 歯車の状態。"Tooth Fault" または "No Tooth Fault" として指定します。
CSV ファイル "transmissionCasingData.csv" からトランスミッション ケーシング データを読み取ります。
filename = "transmissionCasingData.csv"; tbl = readtable(filename,TextType="String");
関数 convertvars を使用して、予測のラベルを categorical に変換します。
labelName = "GearToothCondition"; tbl = convertvars(tbl,labelName,"categorical");
table の最初の数行を表示します。
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ _______________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 "Sensor Drift" "No Shaft Wear" No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 "Sensor Drift" "No Shaft Wear" No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 "Sensor Drift" "Shaft Wear" No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 "Sensor Drift" "Shaft Wear" No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 "Sensor Drift" "Shaft Wear" No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 "Sensor Drift" "Shaft Wear" No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 "Sensor Drift" "Shaft Wear" No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 "Sensor Drift" "Shaft Wear" No Tooth Fault
カテゴリカル特徴量を使用してネットワークに学習させるには、最初にカテゴリカル特徴量を数値に変換しなければなりません。まず、関数 convertvars を使用して、すべてのカテゴリカル入力変数の名前を格納した string 配列を指定することにより、カテゴリカル予測子を categorical に変換します。このデータ セットには、"SensorCondition" と "ShaftCondition" という名前の 2 つのカテゴリカル特徴量があります。
categoricalInputNames = ["SensorCondition" "ShaftCondition"]; tbl = convertvars(tbl,categoricalInputNames,"categorical");
カテゴリカル入力変数をループ処理します。各変数について次を行います。
関数
onehotencodeを使用して、categorical 値を one-hot 符号化ベクトルに変換する。関数
addvarsを使用して、one-hot ベクトルを table に追加する。対応する categorical データが含まれる列の後にベクトルを挿入するように指定する。categorical データが含まれる対応する列を削除する。
for i = 1:numel(categoricalInputNames) name = categoricalInputNames(i); oh = onehotencode(tbl(:,name)); tbl = addvars(tbl,oh,After=name); tbl(:,name) = []; end
関数 splitvars を使用して、ベクトルを別々の列に分割します。
tbl = splitvars(tbl);
table の最初の数行を表示します。カテゴリカル予測子が、categorical 値を変数名として複数の列に分割されていることに注意してください。
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis No Sensor Drift Sensor Drift No Shaft Wear Shaft Wear GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ____________ _____________ __________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0 No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 0 1 1 0 No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 0 1 0 1 No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 0 1 0 1 No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 0 1 0 1 No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1 No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 0 1 0 1 No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
データ セットのクラス名を表示します。
classNames = categories(tbl{:,labelName})classNames = 2×1 cell
{'No Tooth Fault'}
{'Tooth Fault' }
学習セットと検証セットへのデータ セットの分割
データ セットを学習用、検証用、およびテスト用の区画に分割します。データの 15% を検証用に、15% をテスト用に残しておきます。
データセットに含まれている観測値の数を表示します。
numObservations = size(tbl,1)
numObservations = 208
各区画の観測数を求めます。
numObservationsTrain = floor(0.7*numObservations)
numObservationsTrain = 145
numObservationsValidation = floor(0.15*numObservations)
numObservationsValidation = 31
numObservationsTest = numObservations - numObservationsTrain - numObservationsValidation
numObservationsTest = 32
観測値に対応するランダムなインデックスの配列を作成し、区画サイズを使用して分割します。
idx = randperm(numObservations); idxTrain = idx(1:numObservationsTrain); idxValidation = idx(numObservationsTrain+1:numObservationsTrain+numObservationsValidation); idxTest = idx(numObservationsTrain+numObservationsValidation+1:end);
インデックスを使用して、データの table を学習用、検証用、およびテスト用の区画に分割します。
tblTrain = tbl(idxTrain,:); tblValidation = tbl(idxValidation,:); tblTest = tbl(idxTest,:);
ネットワーク アーキテクチャの定義
分類のためにネットワークを定義します。
特徴入力層を使用してネットワークを定義し、特徴の数を指定します。また、z スコア正規化を使用してデータを正規化するように入力層を構成します。次に、出力サイズが 50 の全結合層を含め、その後にバッチ正規化層と ReLU 層を配置します。分類に向けて、出力サイズがクラスの数に対応する別の全結合層を指定し、その後にソフトマックス層を配置します。
numFeatures = size(tbl,2) - 1;
numClasses = numel(classNames);
layers = [
featureInputLayer(numFeatures,Normalization="zscore")
fullyConnectedLayer(50)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];学習オプションの指定
学習オプションを指定します。
Adam を使用してネットワークに学習させます。
サイズ 16 のミニバッチを使用して学習を行います。
すべてのエポックでデータをシャッフルします。
検証データを指定して、学習中にネットワークの精度を監視します。
プロットに学習の進行状況を表示し、詳細なコマンド ウィンドウ出力を表示しないようにします。
学習データでネットワークに学習させ、学習中に一定の間隔で検証データに対してその精度を計算します。検証データは、ネットワークの重みの更新には使用されません。
miniBatchSize = 16; options = trainingOptions("adam", ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... ValidationData=tblValidation, ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
ネットワークの学習
layers、学習データ、および学習オプションによって定義されたアーキテクチャを使用して、ネットワークに学習させます。既定では、trainnet は利用可能な GPU があればそれを使用し、そうでない場合は CPU を使用します。GPU で学習を行うには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。trainingOptions の名前と値の引数 ExecutionEnvironment を使用して、実行環境を指定することもできます。
学習の進行状況プロットには、ミニバッチの損失と精度、および検証の損失と精度が表示されます。学習の進行状況プロットの詳細は、深層学習における学習の進行状況の監視を参照してください。
net = trainnet(tblTrain,layers,"crossentropy",options);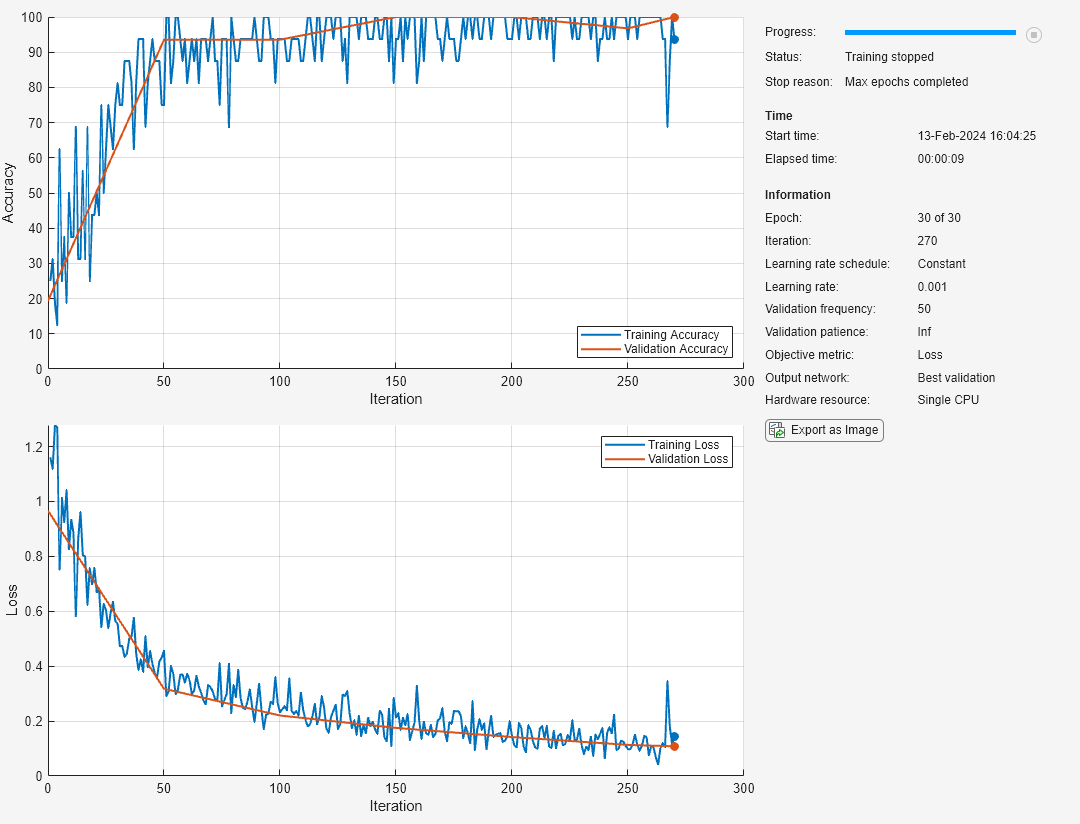
ネットワークのテスト
学習済みネットワークを使用してテスト データのラベルを予測し、精度を計算します。学習に使用されるサイズと同じミニバッチ サイズを指定します。
scores = minibatchpredict(net,tblTest(:,1:end-1),MiniBatchSize=miniBatchSize); YPred = scores2label(scores,classNames);
分類精度を計算します。精度は、ネットワークが正しく予測するラベルの比率です。
YTest = tblTest{:,labelName};
accuracy = sum(YPred == YTest)/numel(YTest)accuracy = 0.9375
結果を混同行列で表示します。
figure confusionchart(YTest,YPred)

参考
trainnet | trainingOptions | dlnetwork | fullyConnectedLayer | ディープ ネットワーク デザイナー | featureInputLayer