このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
Raspberry Pi での音声コマンド認識コードの生成
この例では、音声コマンド認識のための特徴抽出と畳み込みニューラル ネットワーク (CNN) を Raspberry Pi™ に展開する方法を説明します。特徴抽出とネットワーク コードを生成するために、MATLAB Coder™、MATLAB® Support Package for Raspberry Pi Hardware、ARM® Compute Library を使用します。この例では、生成されたコードは Raspberry Pi の実行可能ファイルであり、予測された音声コマンドと信号および聴覚スペクトログラムを表示する MATLAB スクリプトによって呼び出されます。MATLAB スクリプトと Raspberry Pi の実行可能ファイルの交互作用は、ユーザー データグラム プロトコル (UDP) を使用して処理されます。オーディオの前処理およびネットワーク学習の詳細については、Train Deep Learning Network for Speech Command Recognition (Audio Toolbox)を参照してください。
前提条件
MATLAB Coder Interface for Deep Learning Libraries
NEON 拡張をサポートする ARM プロセッサ
ARM Compute Library version 20.02.1 (ターゲット ARM ハードウェア上)
コンパイラおよびライブラリの環境変数
サポートされるライブラリのバージョン、および環境変数の設定の詳細については、深層学習に MATLAB Coder を使用するための前提条件 (MATLAB Coder)を参照してください。
MATLAB でのストリーミングのデモ
特徴抽出パイプラインおよび分類に関して、Train Deep Learning Network for Speech Command Recognition (Audio Toolbox)で構築したのと同じパラメーターを使用します。
ネットワークに学習させたのと同じサンプル レート (16 kHz) を定義します。分類レートと、フレームごとに入力されるオーディオ サンプルの数を定義します。ネットワークに入力される特徴は、オーディオ データ 1 秒に対応するバーク スペクトログラムです。バーク スペクトログラムは、10 ms のホップをもつ 25 ms のウィンドウについて計算されます。各スペクトログラムにおける個々のスペクトルの数を計算します。
fs = 16000; classificationRate = 20; samplesPerCapture = fs/classificationRate; segmentDuration = 1; segmentSamples = round(segmentDuration*fs); frameDuration = 0.025; frameSamples = round(frameDuration*fs); hopDuration = 0.010; hopSamples = round(hopDuration*fs); numSpectrumPerSpectrogram = floor((segmentSamples-frameSamples)/hopSamples) + 1;
audioFeatureExtractor (Audio Toolbox)オブジェクトを作成し、ウィンドウを正規化せずに帯域数 50 のバーク スペクトログラムを抽出します。各スペクトログラムの要素数を計算します。
afe = audioFeatureExtractor( ... 'SampleRate',fs, ... 'FFTLength',512, ... 'Window',hann(frameSamples,'periodic'), ... 'OverlapLength',frameSamples - hopSamples, ... 'barkSpectrum',true); numBands = 50; setExtractorParameters(afe,'barkSpectrum','NumBands',numBands,'WindowNormalization',false); numElementsPerSpectrogram = numSpectrumPerSpectrogram*numBands;
事前学習済みの CNN およびラベルを読み込みます。
load('commandNet.mat') labels = trainedNet.Layers(end).Classes; NumLabels = numel(labels); BackGroundIdx = find(labels == 'background');
バッファーおよび判定しきい値を定義し、ネットワーク予測を後処理します。
probBuffer = single(zeros([NumLabels,classificationRate/2])); YBuffer = single(NumLabels * ones(1, classificationRate/2)); countThreshold = ceil(classificationRate*0.2); probThreshold = single(0.7);
audioDeviceReader (Audio Toolbox)オブジェクトを作成し、デバイスからオーディオを読み取ります。dsp.AsyncBuffer (DSP System Toolbox)オブジェクトを作成し、オーディオをチャンクにバッファリングします。
adr = audioDeviceReader('SampleRate',fs,'SamplesPerFrame',samplesPerCapture,'OutputDataType','single'); audioBuffer = dsp.AsyncBuffer(fs);
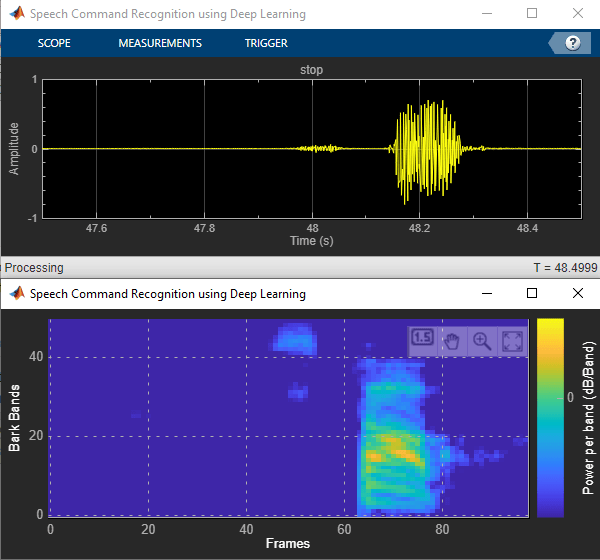
dsp.MatrixViewer (DSP System Toolbox)オブジェクトおよびtimescope (DSP System Toolbox)オブジェクトを作成し、結果を表示します。
matrixViewer = dsp.MatrixViewer("ColorBarLabel","Power per band (dB/Band)",... "XLabel","Frames",... "YLabel","Bark Bands", ... "Position",[400 100 600 250], ... "ColorLimits",[-4 2.6445], ... "AxisOrigin","Lower left corner", ... "Name","Speech Command Recognition using Deep Learning"); timeScope = timescope("SampleRate",fs, ... "YLimits",[-1 1], ... "Position",[400 380 600 250], ... "Name","Speech Command Recognition Using Deep Learning", ... "TimeSpanSource","Property", ... "TimeSpan",1, ... "BufferLength",fs, ... "YLabel","Amplitude", ... "ShowGrid",true);
時間スコープおよび行列ビューアーを表示します。時間スコープおよび行列ビューアーの両方が開いているか、制限時間に達するまで、コマンドを検出します。制限時間に達する前にライブ検出を停止するには、時間スコープ ウィンドウまたは行列ビューアー ウィンドウを閉じます。
show(timeScope) show(matrixViewer) timeLimit = 10; tic while isVisible(timeScope) && isVisible(matrixViewer) && toc < timeLimit % Capture audio x = adr(); write(audioBuffer,x); y = read(audioBuffer,fs,fs-samplesPerCapture); % Compute auditory features features = extract(afe,y); auditoryFeatures = log10(features + 1e-6); % Perform prediction probs = predict(trainedNet, auditoryFeatures); [~, YPredicted] = max(probs); % Perform statistical post processing YBuffer = [YBuffer(2:end),YPredicted]; probBuffer = [probBuffer(:,2:end),probs(:)]; [YModeIdx, count] = mode(YBuffer); maxProb = max(probBuffer(YModeIdx,:)); if YModeIdx == single(BackGroundIdx) || single(count) < countThreshold || maxProb < probThreshold speechCommandIdx = BackGroundIdx; else speechCommandIdx = YModeIdx; end % Update plots matrixViewer(auditoryFeatures'); timeScope(x); if (speechCommandIdx == BackGroundIdx) timeScope.Title = ' '; else timeScope.Title = char(labels(speechCommandIdx)); end drawnow limitrate end
スコープを非表示にします。
hide(matrixViewer) hide(timeScope)
MATLAB コードの展開準備
コード生成と互換性がある特徴抽出を実行する関数を作成するには、audioFeatureExtractor オブジェクトでgenerateMATLABFunction (Audio Toolbox)を呼び出します。オブジェクト関数 generateMATLABFunction は、コード生成と互換性があり、同等の特徴抽出を実行するスタンドアロン関数を作成します。
generateMATLABFunction(afe,'extractSpeechFeatures')サポート関数 HelperSpeechCommandRecognitionRasPi は、以前に説明した特徴抽出およびネットワーク予測プロセスをカプセル化します。特徴抽出はコード生成と互換性があるため、特徴抽出は生成された関数 extractSpeechFeatures によって処理されます。ネットワークはコード生成と互換性があるため、サポート関数は関数coder.loadDeepLearningNetwork (MATLAB Coder)を使用してネットワークを読み込みます。サポート関数は、dsp.UDPReceiver (DSP System Toolbox)System object を使用し、聴覚スペクトログラムと、予測された音声コマンドに対応するインデックスを、Raspberry Pi から MATLAB に送信します。サポート関数は、dsp.UDPReceiver (DSP System Toolbox)System object を使用し、マイクによって取得されたオーディオを MATLAB で受け取ります。
Raspberry Pi での実行可能ファイルの生成
hostIPAddress をマシンのアドレスに置き換えます。Raspberry Pi は、聴覚スペクトログラムと予測された音声コマンドを、この IP アドレスに送信します。
hostIPAddress = coder.Constant('172.18.230.30');コード生成構成オブジェクトを作成し、実行可能プログラムを生成します。ターゲット言語を C++ に指定します。
cfg = coder.config('exe'); cfg.TargetLang = 'C++';
Raspberry Pi の ARM Compute Library を使用し、深層学習コード生成用の構成オブジェクトを作成します。Raspberry Pi のアーキテクチャを指定し、深層学習構成オブジェクトをコード生成構成オブジェクトに追加します。
dlcfg = coder.DeepLearningConfig('arm-compute'); dlcfg.ArmArchitecture = 'armv7'; dlcfg.ArmComputeVersion = '20.02.1'; cfg.DeepLearningConfig = dlcfg;
Raspberry Pi のサポート パッケージ関数 raspi を使用し、Raspberry Pi への接続を作成します。以下のコードで、次を置き換えます。
raspiname: 自分の Raspberry Pi の名前pi: 自分のユーザー名
password: 自分のパスワード
r = raspi('raspiname','pi','password');
Raspberry Pi 用のcoder.hardware (MATLAB Coder)オブジェクトを作成してコード生成構成オブジェクトに追加します。
hw = coder.hardware('Raspberry Pi');
cfg.Hardware = hw;Raspberry Pi 上のビルド フォルダーを指定します。
buildDir = '~/remoteBuildDir';
cfg.Hardware.BuildDir = buildDir;自動生成された C++ main ファイルをスタンドアロン実行可能ファイルの生成に使用します。
cfg.GenerateExampleMain = 'GenerateCodeAndCompile';codegen (MATLAB Coder)を呼び出し、C++ コードと Raspberry Pi の実行可能ファイルを生成します。既定では、Raspberry Pi のアプリケーション名は MATLAB 関数と同じです。
codegen -config cfg HelperSpeechCommandRecognitionRasPi -args {hostIPAddress} -report -v
Deploying code. This may take a few minutes. ### Compiling function(s) HelperSpeechCommandRecognitionRasPi ... ------------------------------------------------------------------------ Location of the generated elf : /home/pi/remoteBuildDir/MATLAB_ws/R2022a/W/Ex/ExampleManager/sporwal.Bdoc22a.j1844576/deeplearning_shared-ex00376115 ### Using toolchain: GNU GCC Embedded Linux ### 'W:\Ex\ExampleManager\sporwal.Bdoc22a.j1844576\deeplearning_shared-ex00376115\codegen\exe\HelperSpeechCommandRecognitionRasPi\HelperSpeechCommandRecognitionRasPi_rtw.mk' is up to date ### Building 'HelperSpeechCommandRecognitionRasPi': make -j$(($(nproc)+1)) -Otarget -f HelperSpeechCommandRecognitionRasPi_rtw.mk all ------------------------------------------------------------------------ ### Generating compilation report ... Warning: Function 'HelperSpeechCommandRecognitionRasPi' does not terminate due to an infinite loop. Warning in ==> HelperSpeechCommandRecognitionRasPi Line: 86 Column: 1 Code generation successful (with warnings): View report
Raspberry Pi でのアプリケーションの初期化
HelperSpeechCommandRasPi application on Raspberry Pi を開くためのコマンドを作成します。systemを使用し、コマンドを Raspberry Pi に送信します。
applicationName = 'HelperSpeechCommandRecognitionRasPi'; applicationDirPaths = raspi.utils.getRemoteBuildDirectory('applicationName',applicationName); targetDirPath = applicationDirPaths{1}.directory; exeName = strcat(applicationName,'.elf'); command = ['cd ' targetDirPath '; ./' exeName ' &> 1 &']; system(r,command);
dsp.UDPReceiver (DSP System Toolbox)System object を作成し、MATLAB で取得したオーディオを Raspberry Pi に送信します。Raspberry Pi の targetIPAddress を更新します。Raspberry Pi は、dsp.UDPReceiver (DSP System Toolbox)System object を使用し、取得したオーディオを同じポートから受信します。
targetIPAddress = '172.18.231.92'; UDPSend = dsp.UDPSender('RemoteIPPort',26000,'RemoteIPAddress',targetIPAddress);
dsp.UDPReceiver (DSP System Toolbox)System object を作成し、聴覚的な特徴と、予測された音声コマンドのインデックスを Raspberry Pi から受信します。Raspberry Pi から受け取った各 UDP パケットは、列優先で並べられた聴覚的な特徴と、それに続く予測された音声コマンドのインデックスで構成されます。dsp.UDPReceiver オブジェクトの最大メッセージ長は 65507 バイトです。UDP パケットの最大数に対応できるバッファー サイズを計算します。
sizeOfFloatInBytes = 4; maxUDPMessageLength = floor(65507/sizeOfFloatInBytes); samplesPerPacket = 1 + numElementsPerSpectrogram; numPackets = floor(maxUDPMessageLength/samplesPerPacket); bufferSize = numPackets*samplesPerPacket*sizeOfFloatInBytes; UDPReceive = dsp.UDPReceiver("LocalIPPort",21000, ... "MessageDataType","single", ... "MaximumMessageLength",samplesPerPacket, ... "ReceiveBufferSize",bufferSize);
Raspberry Pi で実行している実行可能ファイルにゼロのフレームを送信し、初期化オーバーヘッドを減らします。
UDPSend(zeros(samplesPerCapture,1,"single"));展開されたコードを使用した音声コマンド認識の実行
時間スコープおよび行列ビューアーの両方が開いているか、制限時間に達するまで、コマンドを検出します。制限時間に達する前にライブ検出を停止するには、時間スコープ ウィンドウまたは行列ビューアー ウィンドウを閉じます。
show(timeScope) show(matrixViewer) timeLimit = 20; tic while isVisible(timeScope) && isVisible(matrixViewer) && toc < timeLimit % Capture audio and send that to RasPi x = adr(); UDPSend(x); % Receive data packet from RasPi udpRec = UDPReceive(); if ~isempty(udpRec) % Extract predicted index, the last sample of received UDP packet speechCommandIdx = udpRec(end); % Extract auditory spectrogram spec = reshape(udpRec(1:numElementsPerSpectrogram), [numBands, numSpectrumPerSpectrogram]); % Display time domain signal and auditory spectrogram timeScope(x) matrixViewer(spec) if speechCommandIdx == BackGroundIdx timeScope.Title = ' '; else timeScope.Title = char(labels(speechCommandIdx)); end drawnow limitrate end end hide(matrixViewer) hide(timeScope)
Raspberry Pi の実行可能ファイルを停止するには、stopExecutable を使用します。UDP オブジェクトを解放します。
stopExecutable(codertarget.raspi.raspberrypi,exeName) release(UDPSend) release(UDPReceive)
PIL ワークフローを使用したプロファイリング
Embedded Coder® のプロセッサインザループ (PIL) ワークフローを使用すれば、Raspberry Pi で実行にかかった時間を測定できます。サポート関数 ProfileSpeechCommandRecognitionRaspi は関数 HelperSpeechCommandRecognitionRaspi と等価ですが、前者は音声コマンドのインデックスと聴覚スペクトログラムを返し、後者は UDP を使用して同じパラメーターを送信します。UDP 呼び出しにかかる時間は 1 ms 未満であり、実行時間全体と比較すると比較的短いものです。
PIL 構成オブジェクトを作成します。
cfg = coder.config('lib','ecoder',true); cfg.VerificationMode = 'PIL';
ARM Compute Library と ARM アーキテクチャを設定します。
dlcfg = coder.DeepLearningConfig('arm-compute'); cfg.DeepLearningConfig = dlcfg ; cfg.DeepLearningConfig.ArmArchitecture = 'armv7'; cfg.DeepLearningConfig.ArmComputeVersion = '19.05';
ターゲット ハードウェアとの接続を設定します。
if (~exist('r','var')) r = raspi('raspiname','pi','password'); end hw = coder.hardware('Raspberry Pi'); cfg.Hardware = hw;
ビルド ディレクトリとターゲット言語を設定します。
buildDir = '~/remoteBuildDir'; cfg.Hardware.BuildDir = buildDir; cfg.TargetLang = 'C++';
プロファイリングを有効にしてから、PIL コードを生成します。ProfileSpeechCommandRecognition_pil という名前の MEX ファイルが現在のフォルダー内に生成されます。
cfg.CodeExecutionProfiling = true; codegen -config cfg ProfileSpeechCommandRecognitionRaspi -args {rand(samplesPerCapture, 1, 'single')} -report -v
Deploying code. This may take a few minutes. ### Compiling function(s) ProfileSpeechCommandRecognitionRaspi ... ### Connectivity configuration for function 'ProfileSpeechCommandRecognitionRaspi': 'Raspberry Pi' ### Using toolchain: GNU GCC Embedded Linux ### Creating 'W:\Ex\ExampleManager\sporwal.Bdoc22a.j1844576\deeplearning_shared-ex00376115\codegen\lib\ProfileSpeechCommandRecognitionRaspi\coderassumptions\lib\ProfileSpeechCommandRecognitionRaspi_ca.mk' ... ### Building 'ProfileSpeechCommandRecognitionRaspi_ca': make -j$(($(nproc)+1)) -Otarget -f ProfileSpeechCommandRecognitionRaspi_ca.mk all ### Using toolchain: GNU GCC Embedded Linux ### Creating 'W:\Ex\ExampleManager\sporwal.Bdoc22a.j1844576\deeplearning_shared-ex00376115\codegen\lib\ProfileSpeechCommandRecognitionRaspi\pil\ProfileSpeechCommandRecognitionRaspi_rtw.mk' ... ### Building 'ProfileSpeechCommandRecognitionRaspi': make -j$(($(nproc)+1)) -Otarget -f ProfileSpeechCommandRecognitionRaspi_rtw.mk all Location of the generated elf : /home/pi/remoteBuildDir/MATLAB_ws/R2022a/W/Ex/ExampleManager/sporwal.Bdoc22a.j1844576/deeplearning_shared-ex00376115/codegen/lib/ProfileSpeechCommandRecognitionRaspi/pil ------------------------------------------------------------------------ ### Using toolchain: GNU GCC Embedded Linux ### 'W:\Ex\ExampleManager\sporwal.Bdoc22a.j1844576\deeplearning_shared-ex00376115\codegen\lib\ProfileSpeechCommandRecognitionRaspi\ProfileSpeechCommandRecognitionRaspi_rtw.mk' is up to date ### Building 'ProfileSpeechCommandRecognitionRaspi': make -j$(($(nproc)+1)) -Otarget -f ProfileSpeechCommandRecognitionRaspi_rtw.mk all ------------------------------------------------------------------------ ### Generating compilation report ... Code generation successful: View report
Raspberry Pi の実行時間の評価
生成された PIL 関数を複数回呼び出し、平均実行時間を求めます。
testDur = 50e-3; numCalls = 100; for k = 1:numCalls x = pinknoise(fs*testDur,'single'); [speechCommandIdx, auditoryFeatures] = ProfileSpeechCommandRecognitionRaspi_pil(x); end
### Starting application: 'codegen\lib\ProfileSpeechCommandRecognitionRaspi\pil\ProfileSpeechCommandRecognitionRaspi.elf'
To terminate execution: clear ProfileSpeechCommandRecognitionRaspi_pil
### Launching application ProfileSpeechCommandRecognitionRaspi.elf...
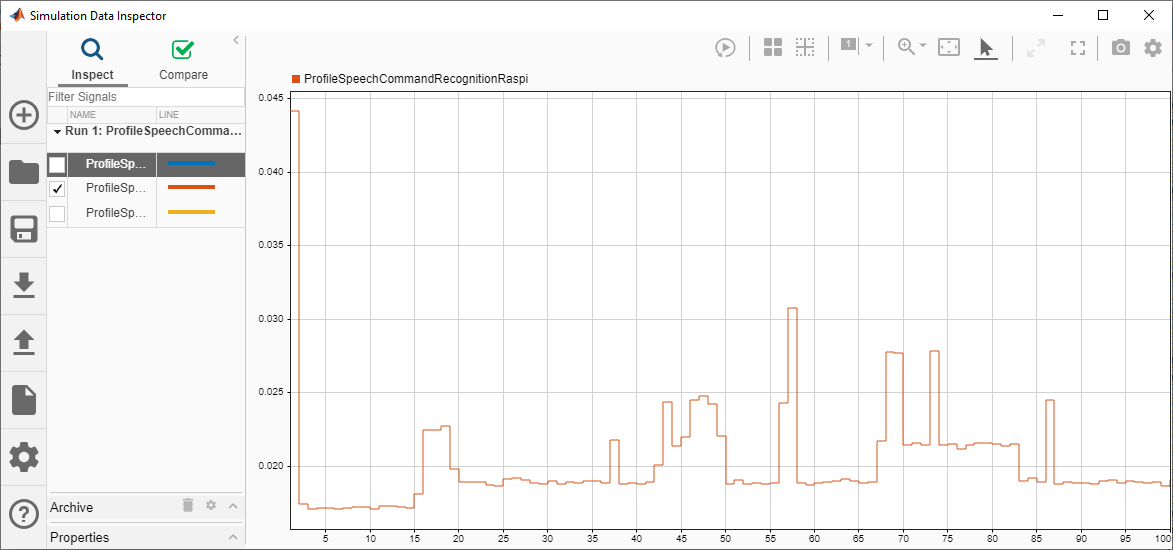
Execution profiling data is available for viewing. Open Simulation Data Inspector.
Execution profiling report available after termination.
PIL の実行を終了します。
clear ProfileSpeechCommandRecognitionRaspi_pil ### Host application produced the following standard output (stdout) and standard error (stderr) messages:
Execution profiling report: report(getCoderExecutionProfile('ProfileSpeechCommandRecognitionRaspi'))
実行プロファイル レポートを生成し、実行時間を評価します。
executionProfile = getCoderExecutionProfile('ProfileSpeechCommandRecognitionRaspi'); report(executionProfile, ... 'Units','Seconds', ... 'ScaleFactor','1e-03', ... 'NumericFormat','%0.4f')
ans = 'W:\Ex\ExampleManager\sporwal.Bdoc22a.j1844576\deeplearning_shared-ex00376115\codegen\lib\ProfileSpeechCommandRecognitionRaspi\html\orphaned\ExecutionProfiling_d82c7024f87064b9.html'
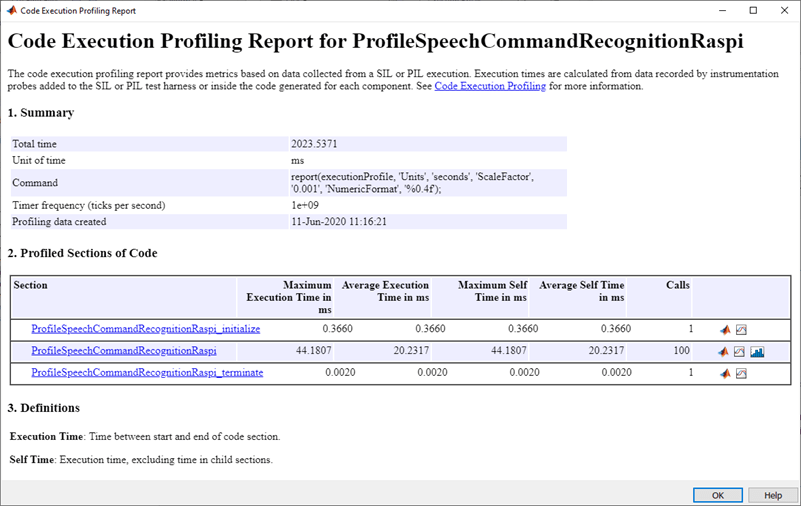
関数 ProfileSpeechCommandRecognitionRaspi でかかる最大実行時間は、平均実行時間のほぼ 2 倍です。実行時間は PIL 関数の最初の呼び出しで最大となりますが、これは最初の呼び出しで初期化が行われるためです。平均実行時間は約 20 ms であり、50 ms の割り当て (オーディオ取得時間) を下回っています。パフォーマンスは Raspberry Pi 4 Model B Rev 1.1 で測定されます。