TransposedConvolution2DLayer
2 次元転置畳み込み層
説明
2 次元転置畳み込み層では 2 次元の特徴マップがアップサンプリングされます。
この層は、間違って "逆畳み込み" 層または "deconv" 層と呼ばれることがあります。この層は畳み込みの転置であり、逆畳み込みは実行しません。
作成
transposedConv2dLayer を使用して 2 次元転置畳み込み層を作成します。
プロパティ
例
アルゴリズム
2 次元転置畳み込み層では 2 次元の特徴マップがアップサンプリングされます。
"標準の" 畳み込み演算は、入力にスライディング畳み込みフィルターを適用して入力を "ダウンサンプリング" します。入力と出力をフラット化することで、層の重みとバイアスから派生させることができる畳み込み行列 C とバイアス ベクトル B に関する畳み込み演算を として表すことができます。
同様に、"転置" 畳み込み演算は、入力にスライディング畳み込みフィルターを適用して入力を "アップサンプリング" します。スライディング フィルターを使用して入力をダウンサンプリングする代わりにアップサンプリングするには、対応するフィルターのエッジのサイズから 1 を減じたサイズのパディングを使用して、層の入力の各エッジを 0 でパディングします。
入力と出力をフラット化することで、転置畳み込み演算は と等価になります。ここで、C および B は、それぞれ、層の重みとバイアスから派生させ、標準の畳み込みで使用する畳み込み行列とバイアス ベクトルを表します。この処理は、標準の畳み込み層における backward 関数と等価です。
次のイメージは、2 行 2 列の入力をアップサンプリングする 3 行 3 列のフィルターを示しています。下側のマップは入力を表し、上側のマップは出力を表します。 1
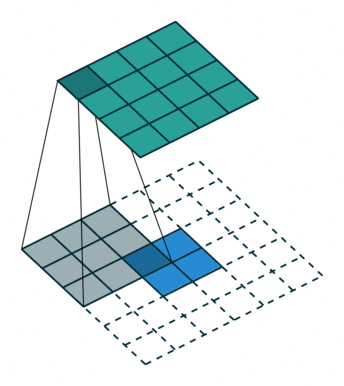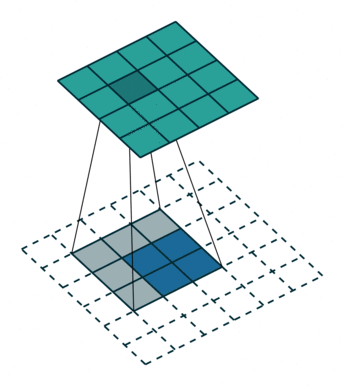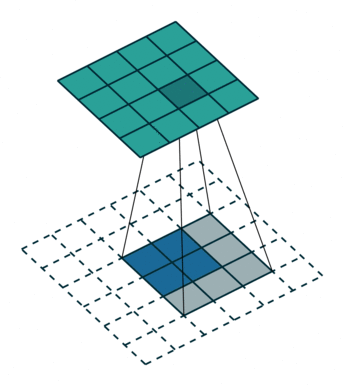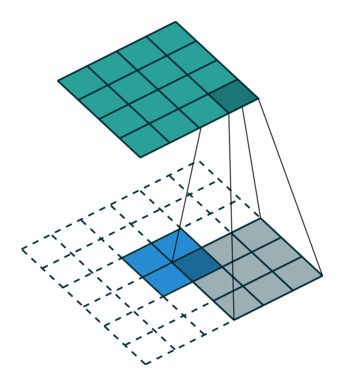
参照
[1] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
バージョン履歴
R2017b で導入1 Image credit: Convolution arithmetic (License)