文法的依存関係の解析を使用した文構造の解析
この例では、文法的依存関係の解析を使用して文から情報を抽出する方法を示します。
文法的依存関係の解析は、文の単語どうしの依存関係を強調して、文の構造を識別するプロセスです。たとえば、どの形容詞がどの名詞を修飾するかを示すことができます。
文法的依存関係の分析を使用して、文から情報を抽出することができます。たとえば、"If you see a blue light, then press the red button." (青い光が見えたら、赤いボタンを押してください) という文に対し、文の文法的な詳細を解析し、ボタンが赤であり、押す必要があることをプログラムで取得することができます。
次のプロットは、ある文の文法構造を示したものです。
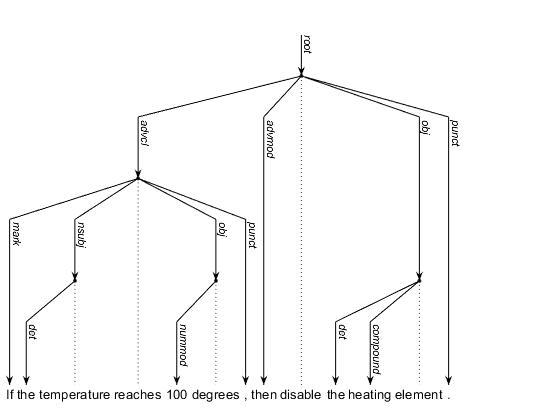
文法的依存関係の詳細の追加
分析する文を格納する string スカラーを作成します。
str = "If the temperature reaches 100 degrees, then disable the heating element.";テキストをトークン化し、文書に文法的依存関係を追加します。関数 addDependencyDetails には、Text Analytics Toolbox™ Model for UDify Data サポート パッケージが必要です。サポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。
document = tokenizedDocument(str); document = addDependencyDetails(document);
関数 tokenDetails を使用してトークンの詳細を表示します。関数 addDependencyDetails によって、変数 Head と変数 Dependency が table に追加されます。
tdetails = tokenDetails(document)
tdetails=13×8 table
"If" 1 1 1 letters en 4 mark
"the" 1 1 1 letters en 3 det
"temperature" 1 1 1 letters en 4 nsubj
"reaches" 1 1 1 letters en 9 advcl
"100" 1 1 1 digits en 6 nummod
"degrees" 1 1 1 letters en 4 obj
"," 1 1 1 punctuation en 4 punct
"then" 1 1 1 letters en 9 advmod
"disable" 1 1 1 letters en 0 root
"the" 1 1 1 letters en 12 det
"heating" 1 1 1 letters en 12 compound
"element" 1 1 1 letters en 9 obj
"." 1 1 1 punctuation en 9 punct
文法的依存関係の可視化
文法的依存関係をセンテンス チャートで可視化します。
figure sentenceChart(document)

文法的依存関係ツリーからの情報の抽出
ツリー構造を使用して、文から情報を抽出できます。
この文の形式は "If <条件>, then <アクション>." です。
文の根を見つけます。この場合、根はアクションの動詞 "disable" です。
idxRoot = find(tdetails.Dependency == "root");
tokenRoot = tdetails.Token(idxRoot)tokenRoot = "disable"
文の条件を解析するには、文の副詞節を見つけます。この場合、副詞節の根は動詞 "reaches" です。
idxRoot = find(tdetails.Dependency == "root"); idxAdvcl = (tdetails.Head == idxRoot) & (tdetails.Dependency == "advcl"); tokenAdvcl = tdetails.Token(idxAdvcl)
tokenAdvcl = "reaches"
形式 "<主語> reaches <目的語>" の従属節を解析するには、単語 "reaches" の主語と目的語を見つけます。
単語 "reaches" の主語を見つけます。この場合、主語は単語 "temperature" です。
idxToken = find(tdetails.Token == "reaches"); idxNsubj = (tdetails.Head == idxToken) & (tdetails.Dependency == "nsubj"); tokenNsubj = tdetails.Token(idxNsubj)
tokenNsubj = "temperature"
動詞 "reaches" の目的語を見つけます。この場合、目的語は単語 "degrees" です。
idxToken = find(tdetails.Token == "reaches"); idxConditionObject = (tdetails.Head == idxToken) & (tdetails.Dependency == "obj"); tokenConditionObject = tdetails.Token(idxConditionObject)
tokenConditionObject = "degrees"
形式 "<数値> degrees" の従属節を解析するには、単語 "degrees" の数値修飾語を見つけます。この場合、数値修飾語は "100" です。
idxToken = find(tdetails.Token == "degrees"); idxNummod = (tdetails.Head == idxToken) & (tdetails.Dependency == "nummod"); tokenNummod = tdetails.Token(idxNummod)
tokenNummod = "100"
文のアクションを解析するには、動詞 "disable" の目的語を見つけます。この場合、目的語は単語 "element" です。
idxToken = find(tdetails.Token == "disable"); idxActionObject = (tdetails.Head == idxToken) & (tdetails.Dependency == "obj"); tokenActionObject = tdetails.Token(idxActionObject)
tokenActionObject = "element"
"<タイプ> element" という形式の従属節を解析するには、複合関係でトークンを見つけます。この場合、修飾語は単語 "heating" です。
idxToken = find(tdetails.Token == "element"); idxObject = (tdetails.Head == idxToken) & (tdetails.Dependency == "compound"); tokenCompound = tdetails.Token(idxObject)
tokenCompound = "heating"
参考
sentenceChart | wordcloud | textscatter | addDependencyDetails | tokenDetails | addSentenceDetails | tokenizedDocument