fitted
線形混合効果モデルからの近似応答
説明
例
標本データを読み込み、dataset2table関数を使用して table の形式に変換します。
load flu
flu = dataset2table(flu)flu=52×11 table
Date NE MidAtl ENCentral WNCentral SAtl ESCentral WSCentral Mtn Pac WtdILI
______________ _____ ______ _________ _________ _____ _________ _________ _____ _____ ______
{'10/9/2005' } 0.97 1.025 1.232 1.286 1.082 1.457 1.1 0.981 0.971 1.182
{'10/16/2005'} 1.136 1.06 1.228 1.286 1.146 1.644 1.123 0.976 0.917 1.22
{'10/23/2005'} 1.135 1.172 1.278 1.536 1.274 1.556 1.236 1.102 0.895 1.31
{'10/30/2005'} 1.52 1.489 1.576 1.794 1.59 2.252 1.612 1.321 1.082 1.343
{'11/6/2005' } 1.365 1.394 1.53 1.825 1.62 2.059 1.471 1.453 1.118 1.586
{'11/13/2005'} 1.39 1.477 1.506 1.9 1.683 1.813 1.464 1.388 1.204 1.47
{'11/20/2005'} 1.212 1.231 1.295 1.495 1.347 1.794 1.303 1.371 1.137 1.611
{'11/27/2005'} 1.477 1.546 1.557 1.855 1.678 2.159 1.739 1.628 1.443 1.827
{'12/4/2005' } 1.285 1.43 1.482 1.635 1.577 1.903 1.53 1.701 1.516 1.776
{'12/11/2005'} 1.354 1.45 1.46 1.794 1.583 1.894 1.831 2.364 2.094 1.941
{'12/18/2005'} 1.502 1.622 1.638 1.988 1.947 2.22 2.577 3.89 2.66 2.34
{'12/25/2005'} 1.86 1.915 1.955 2.38 2.343 3.027 3.219 4.862 2.595 3.086
{'1/1/2006' } 2.114 2.174 2.065 2.557 2.275 2.498 2.644 3.352 2.181 3.26
{'1/8/2006' } 1.815 1.932 1.822 2.046 1.969 1.805 2.189 2.132 1.717 2.613
{'1/15/2006' } 1.541 1.695 1.581 2.008 1.718 1.662 2.156 1.694 1.351 2.247
{'1/22/2006' } 1.632 1.758 1.711 2.217 1.866 2.194 2.268 1.826 1.384 2.352
⋮
table flu には、変数 Date と、インフルエンザ推定罹患率 (Google® 検索から推定される 9 地域の値と疾病対策センター (CDC) による全国の推定値) が格納されている 10 個の変数が含まれています。
線形混合効果モデルを当てはめるには、データが適切な形式の table になっていなければなりません。インフルエンザ罹患率を応答として、地域を予測子変数として線形混合効果モデルを当てはめるため、地域に対応する 9 個の列を 1 つの配列にまとめます。新しい table flu2 には、応答変数 FluRate、各推定の元になっている地域を示すノミナル変数 Region、およびグループ化変数 Date が含まれなければなりません。
flu2 = stack(flu,2:10,NewDataVariableName="FluRate",IndexVariableName="Region")
flu2=468×4 table
Date WtdILI Region FluRate
______________ ______ _________ _______
{'10/9/2005' } 1.182 NE 0.97
{'10/9/2005' } 1.182 MidAtl 1.025
{'10/9/2005' } 1.182 ENCentral 1.232
{'10/9/2005' } 1.182 WNCentral 1.286
{'10/9/2005' } 1.182 SAtl 1.082
{'10/9/2005' } 1.182 ESCentral 1.457
{'10/9/2005' } 1.182 WSCentral 1.1
{'10/9/2005' } 1.182 Mtn 0.981
{'10/9/2005' } 1.182 Pac 0.971
{'10/16/2005'} 1.22 NE 1.136
{'10/16/2005'} 1.22 MidAtl 1.06
{'10/16/2005'} 1.22 ENCentral 1.228
{'10/16/2005'} 1.22 WNCentral 1.286
{'10/16/2005'} 1.22 SAtl 1.146
{'10/16/2005'} 1.22 ESCentral 1.644
{'10/16/2005'} 1.22 WSCentral 1.123
⋮
flu2.Date = nominal(flu2.Date);
地域に対する固定効果と、Date で変化するランダム切片で、線形混合効果モデルを当てはめます。
地域はカテゴリカル変数です。モデルを当てはめるときに、名前と値のペア引数 DummyVarCoding を使用してカテゴリカル変数の対比を指定できます。対比を指定しない場合、fitlme は 'reference' 対比を既定で使用します。モデルは切片をもつので、fitlme は最初の地域 NE を参照として受け取り、他の 8 つの地域を表す 8 つのダミー変数を作成します。たとえば、 は地域 MidAtl を表すダミー変数です。詳細については、ダミー変数を参照してください。
対応するモデルは以下のとおりです。
ここで、 はグループ化変数 Date の水準 に対応する観測値 、 は固定効果係数 ( = 0、1、...、8)、 は地域 NE の係数です。 はグループ化変数 Date の水準 に対応する変量効果、 は観測値 の観測誤差です。変量効果の事前分布は 、誤差項の分布は です。
lme = fitlme(flu2,'FluRate ~ 1 + Region + (1|Date)')lme =
Linear mixed-effects model fit by ML
Model information:
Number of observations 468
Fixed effects coefficients 9
Random effects coefficients 52
Covariance parameters 2
Formula:
FluRate ~ 1 + Region + (1 | Date)
Model fit statistics:
AIC BIC LogLikelihood Deviance
318.71 364.35 -148.36 296.71
Fixed effects coefficients (95% CIs):
Name Estimate SE tStat DF pValue Lower Upper
{'(Intercept)' } 1.2233 0.096678 12.654 459 1.085e-31 1.0334 1.4133
{'Region_MidAtl' } 0.010192 0.052221 0.19518 459 0.84534 -0.092429 0.11281
{'Region_ENCentral'} 0.051923 0.052221 0.9943 459 0.3206 -0.050698 0.15454
{'Region_WNCentral'} 0.23687 0.052221 4.5359 459 7.3324e-06 0.13424 0.33949
{'Region_SAtl' } 0.075481 0.052221 1.4454 459 0.14902 -0.02714 0.1781
{'Region_ESCentral'} 0.33917 0.052221 6.495 459 2.1623e-10 0.23655 0.44179
{'Region_WSCentral'} 0.069 0.052221 1.3213 459 0.18705 -0.033621 0.17162
{'Region_Mtn' } 0.046673 0.052221 0.89377 459 0.37191 -0.055948 0.14929
{'Region_Pac' } -0.16013 0.052221 -3.0665 459 0.0022936 -0.26276 -0.057514
Random effects covariance parameters (95% CIs):
Group: Date (52 Levels)
Name1 Name2 Type Estimate Lower Upper
{'(Intercept)'} {'(Intercept)'} {'std'} 0.6443 0.5297 0.78368
Group: Error
Name Estimate Lower Upper
{'Res Std'} 0.26627 0.24878 0.285
値 7.3324e-06 および 2.1623e-10 は、地域 WNCentral および ESCentral のインフルエンザ罹患率の固定効果が地域 NE のインフルエンザ罹患率に対して有意に異なることをそれぞれ示しています。
変量効果項の標準偏差 の信頼限界 (0.5297, 0.78368) には、変量効果項が有意であることを示す 0 が含まれていません。compare メソッドを使用して、変量効果の項の有意性をテストすることもできます。
任意の観測におけるモデルからの近似条件付き応答には、固定効果および変量効果からの寄与が含まれます。たとえば、2005 年 10 月 9 日の週における地域 WNCentral の罹患率に対する最良線形不偏予測量 (BLUP) の推定値は次のようになります。
固定効果と変量効果の両方による推定に対する寄与が含まれているので、これは近似された条件付き応答です。この値を以下のように計算することもできます。
beta = fixedEffects(lme); [~,~,STATS] = randomEffects(lme); % Compute the random-effects statistics (STATS) STATS.Level = nominal(STATS.Level); y_hat = beta(1) + beta(4) + STATS.Estimate(STATS.Level=='10/9/2005')
y_hat = 1.2884
上記の計算で、beta(1) は の推定値に、beta(4) は の推定値に対応します。fitted メソッドを使用して、近似値を簡単に表示できます。
F = fitted(lme); F(flu2.Date == '10/9/2005' & flu2.Region == 'WNCentral')
ans = 1.2884
2005 年 10 月 9 日の週における地域 WNCentral の推定限界応答は次のようになります。
近似限界応答を計算します。
F = fitted(lme,Conditional=false); F(flu2.Date == '10/9/2005' & flu2.Region == 'WNCentral')
ans = 1.4602
標本データを読み込みます。
load('weight.mat');weight には長期間の調査によるデータが含まれています。そこには 20 人の被験者が 4 つの運動プログラムにランダムに割り当てられ、体重の減少が 6 回の 2 週間の期間にわたって記録されています。このデータは、シミュレーションされたものです。
データを table に保存します。Subject および Program をカテゴリカル変数として定義します。
tbl = table(InitialWeight,Program,Subject,Week,y); tbl.Subject = nominal(tbl.Subject); tbl.Program = nominal(tbl.Program);
線形混合効果モデルを当てはめます。初期体重、プログラムの種類、週、週とプログラムの種類の間の交互作用は固定効果です。切片と週は被験者ごとに異なります。
lme = fitlme(tbl,'y ~ InitialWeight + Program*Week + (Week|Subject)');近似値および生の残差を計算します。
F = fitted(lme); R = residuals(lme);
残差と近似値の対比をプロットします。
plot(F,R,'bx') xlabel('Fitted Values') ylabel('Residuals')
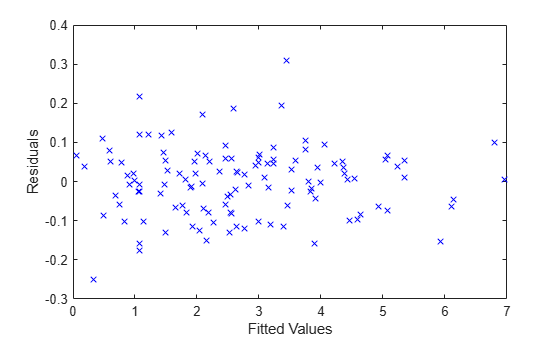
次に、プログラム別にグループ化された、残差と近似値の対比をプロットします。
figure() gscatter(F,R,Program)
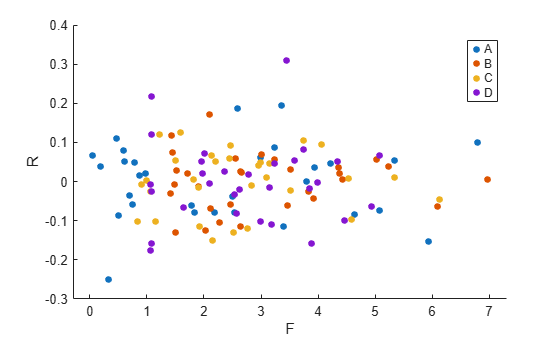
入力引数
出力引数
詳細
バージョン履歴
R2013b で導入