report
説明
metricsTbl = report(metricsResults)metricsTbl を生成します。既定では、metricsTbl には、fairnessMetrics オブジェクト metricsResults の BiasMetrics プロパティに格納されたバイアス メトリクスが含まれます。
metricsTbl = report(metricsResults,Name=Value)BiasMetrics と GroupMetrics を使用して、metricsTbl に含めるバイアス メトリクスとグループ メトリクスをそれぞれ指定できます。
例
fairnessMetrics オブジェクトを作成して、予測ラベルのセンシティブ属性についての公平性メトリクスを計算します。その後、関数 report の名前と値の引数 BiasMetrics と GroupMetrics を使用して、指定した公平性メトリクスについてのメトリクスの table を作成します。
学習データ adultdata およびテスト データ adulttest を含む、標本データ census1994 を読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するために使用できる、米国国勢調査局の人口統計情報から構成されています。学習データ セットの最初の数行をプレビューします。
load census1994
head(adultdata) age workClass fnlwgt education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
___ ________________ __________ _________ _____________ _____________________ _________________ _____________ _____ ______ ____________ ____________ ______________ ______________ ______
39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
38 Private 2.1565e+05 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
53 Private 2.3472e+05 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
28 Private 3.3841e+05 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
37 Private 2.8458e+05 Masters 14 Married-civ-spouse Exec-managerial Wife White Female 0 0 40 United-States <=50K
49 Private 1.6019e+05 9th 5 Married-spouse-absent Other-service Not-in-family Black Female 0 0 16 Jamaica <=50K
52 Self-emp-not-inc 2.0964e+05 HS-grad 9 Married-civ-spouse Exec-managerial Husband White Male 0 0 45 United-States >50K
各行には、成人 1 人の人口統計情報が格納されています。age、marital_status、relationship、race、sex などのセンシティブ属性の情報が含まれます。3 列目の flnwgt に観測値の重みが格納されており、最後の列 salary は個人の年収が $50,000 以下 (<=50K) か $50,000 を超える (>50K) かを示します。
学習データ セット adultdata を使用して分類木に学習させます。table adultdata 内の変数名を使用して、応答変数、予測子変数、および観測値の重みを指定します。
predictorNames = ["capital_gain","capital_loss","education", ... "education_num","hours_per_week","occupation","workClass"]; Mdl = fitctree(adultdata,"salary", ... PredictorNames=predictorNames,Weights="fnlwgt");
学習させた木 Mdl を使用して、テスト標本のラベルを予測します。
adulttest.predictions = predict(Mdl,adulttest);
この例では、予測ラベルの年齢および婚姻区分についての公平性を評価します。変数 age を 4 つのビンにグループ化します。
ageGroups = ["Age<30","30<=Age<45","45<=Age<60","Age>=60"]; adulttest.age_group = discretize(adulttest.age, ... [min(adulttest.age) 30 45 60 max(adulttest.age)], ... categorical=ageGroups);
fairnessMetrics を使用して、予測の変数 age_group および marital_status についての公平性メトリクスを計算します。
metricsResults = fairnessMetrics(adulttest,"salary", ... SensitiveAttributeNames=["age_group","marital_status"], ... Predictions="predictions",ModelNames="Tree",Weights="fnlwgt");
fairnessMetrics でサポートされているすべてのバイアス メトリクスとグループ メトリクスのメトリクスが計算されます。BiasMetrics プロパティと GroupMetrics プロパティに格納されているメトリクスの名前を表示します。
metricsResults.BiasMetrics.Properties.VariableNames(4:end)'
ans = 4×1 cell
{'StatisticalParityDifference' }
{'DisparateImpact' }
{'EqualOpportunityDifference' }
{'AverageAbsoluteOddsDifference'}
metricsResults.GroupMetrics.Properties.VariableNames(4:end)'
ans = 17×1 cell
{'GroupCount' }
{'GroupSizeRatio' }
{'TruePositives' }
{'TrueNegatives' }
{'FalsePositives' }
{'FalseNegatives' }
{'TruePositiveRate' }
{'TrueNegativeRate' }
{'FalsePositiveRate' }
{'FalseNegativeRate' }
{'FalseDiscoveryRate' }
{'FalseOmissionRate' }
{'PositivePredictiveValue' }
{'NegativePredictiveValue' }
{'RateOfPositivePredictions'}
{'RateOfNegativePredictions'}
{'Accuracy' }
関数 report を使用して公平性メトリクスを格納する table を作成します。BiasMetrics を ["eod","aaod"] と指定して、機会均等差 (EOD) と平均絶対オッズ差 (AAOD) のメトリクスをレポートの table に含めます。fairnessMetrics では、これらの 2 つのメトリクスの計算に真陽性率 (TPR) と偽陽性率 (FPR) を使用します。GroupMetrics を ["tpr","fpr"] と指定して、TPR と FPR の値を table に含めます。
metricsTbl = report(metricsResults, ... BiasMetrics=["eod","aaod"],GroupMetrics=["tpr","fpr"]);
センシティブ属性 age_group のみについての公平性メトリクスを表示します。
metricsTbl(metricsTbl.SensitiveAttributeNames=="age_group",3:end)ans=4×5 table
Groups EqualOpportunityDifference AverageAbsoluteOddsDifference TruePositiveRate FalsePositiveRate
__________ __________________________ _____________________________ ________________ _________________
Age<30 -0.041319 0.044114 0.41333 0.041709
30<=Age<45 0 0 0.45465 0.088618
45<=Age<60 0.061495 0.031809 0.51614 0.086495
Age>=60 0.0060387 0.011955 0.46069 0.070746
fairnessMetrics オブジェクトを作成して、真のラベルのセンシティブ属性についての公平性メトリクスを計算します。その後、関数 report を使用して、サポートされるすべての公平性メトリクスを含む table を作成します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。
creditrating = readtable("CreditRating_Historical.dat");変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
応答変数 Rating について、AAA、AA、A、および BBB の格付けを "good" の格付けのカテゴリに結合し、BB、B、および CCC の格付けを "poor" の格付けのカテゴリに結合します。
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
変数 Rating のラベルのセンシティブ属性 Industry についての公平性メトリクスを計算します。
metricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry");
関数 report を使用してバイアス メトリクスを表示します。既定では、関数 report はすべてのバイアス メトリクスを含む table を作成します。
report(metricsResults)
ans=12×4 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact
_______________________ ______ ___________________________ _______________
Industry 1 0.077242 1.2632
Industry 2 0.078577 1.2678
Industry 3 0 1
Industry 4 0.088718 1.3023
Industry 5 0.055526 1.1892
Industry 6 -0.015004 0.94887
Industry 7 0.014489 1.0494
Industry 8 0.063476 1.2163
Industry 9 0.13948 1.4753
Industry 10 0.13865 1.4725
Industry 11 0.009886 1.0337
Industry 12 0.029338 1.1
サポートされているすべてのバイアス メトリクスとグループ メトリクスを含む table を作成します。GroupMetrics を "all" と指定して、すべてのグループ メトリクスを含めます。
report(metricsResults,GroupMetrics="all")ans=12×6 table
SensitiveAttributeNames Groups StatisticalParityDifference DisparateImpact GroupCount GroupSizeRatio
_______________________ ______ ___________________________ _______________ __________ ______________
Industry 1 0.077242 1.2632 348 0.088505
Industry 2 0.078577 1.2678 336 0.085453
Industry 3 0 1 351 0.089268
Industry 4 0.088718 1.3023 314 0.079858
Industry 5 0.055526 1.1892 341 0.086724
Industry 6 -0.015004 0.94887 334 0.084944
Industry 7 0.014489 1.0494 315 0.080112
Industry 8 0.063476 1.2163 325 0.082655
Industry 9 0.13948 1.4753 328 0.083418
Industry 10 0.13865 1.4725 324 0.082401
Industry 11 0.009886 1.0337 300 0.076297
Industry 12 0.029338 1.1 316 0.080366
2 つの分類モデルに学習させ、公平性メトリクスを使用してモデル予測を比較します。
標本ファイル CreditRating_Historical.dat を table に読み取ります。予測子データは、法人顧客リストの財務比率と業種の情報で構成されます。応答変数は、格付機関が割り当てた格付けから構成されます。
creditrating = readtable("CreditRating_Historical.dat");変数 ID の各値は一意の顧客 ID であるため (つまり、length(unique(creditrating.ID)) は creditrating に含まれる観測値の数に等しい)、変数 ID は予測子としては適切ではありません。変数 ID を table から削除し、変数 Industry を categorical 変数に変換します。
creditrating.ID = []; creditrating.Industry = categorical(creditrating.Industry);
応答変数 Rating について、AAA、AA、A、および BBB の格付けを "good" の格付けのカテゴリに結合し、BB、B、および CCC の格付けを "poor" の格付けのカテゴリに結合します。
Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,["AAA","AA","A","BBB"],"good"); Rating = mergecats(Rating,["BB","B","CCC"],"poor"); creditrating.Rating = Rating;
サポート ベクター マシン (SVM) モデルに creditrating データで学習させます。より良い結果を得るために、モデルを当てはめる前に予測子を標準化します。学習させたモデルを使用してラベルを予測し、学習データ セットの誤分類率を計算します。
predictorNames = ["WC_TA","RE_TA","EBIT_TA","MVE_BVTD","S_TA"]; SVMMdl = fitcsvm(creditrating,"Rating", ... PredictorNames=predictorNames,Standardize=true); SVMPredictions = resubPredict(SVMMdl); resubLoss(SVMMdl)
ans = 0.0872
一般化加法モデル (GAM) に学習させます。
GAMMdl = fitcgam(creditrating,"Rating", ... PredictorNames=predictorNames); GAMPredictions = resubPredict(GAMMdl); resubLoss(GAMMdl)
ans = 0.0542
学習データ セットに対する精度は GAMMdl の方が高くなっています。
両方のモデルのモデル予測を使用して、センシティブ属性 Industry についての公平性メトリクスを計算します。
predictions = [SVMPredictions,GAMPredictions]; metricsResults = fairnessMetrics(creditrating,"Rating", ... SensitiveAttributeNames="Industry",Predictions=predictions, ... ModelNames=["SVM","GAM"]);
関数 report を使用してバイアス メトリクスを表示します。
report(metricsResults)
ans=48×5 table
Metrics SensitiveAttributeNames Groups SVM GAM
___________________________ _______________________ ______ _________ __________
StatisticalParityDifference Industry 1 -0.028441 0.0058208
StatisticalParityDifference Industry 2 -0.04014 0.0063339
StatisticalParityDifference Industry 3 0 0
StatisticalParityDifference Industry 4 -0.04905 -0.0043007
StatisticalParityDifference Industry 5 -0.015615 0.0041607
StatisticalParityDifference Industry 6 -0.03818 -0.024515
StatisticalParityDifference Industry 7 -0.01514 0.007326
StatisticalParityDifference Industry 8 0.0078632 0.036581
StatisticalParityDifference Industry 9 -0.013863 0.042266
StatisticalParityDifference Industry 10 0.0090218 0.050095
StatisticalParityDifference Industry 11 -0.004188 0.001453
StatisticalParityDifference Industry 12 -0.041572 -0.028589
DisparateImpact Industry 1 0.92261 1.017
DisparateImpact Industry 2 0.89078 1.0185
DisparateImpact Industry 3 1 1
DisparateImpact Industry 4 0.86654 0.98742
⋮
バイアス メトリクスのうち、機会均等差 (EOD) の値を比較します。関数 plot を使用して、EOD の値の棒グラフを作成します。
b = plot(metricsResults,"eod"); b(1).FaceAlpha = 0.2; b(2).FaceAlpha = 0.2; legend(Location="southwest")
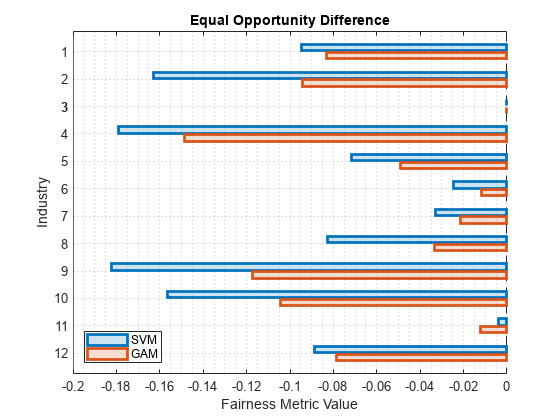
EOD の値の分布が理解しやすくなるように、箱ひげ図を使用して値をプロットします。
boxchart(metricsResults.BiasMetrics.EqualOpportunityDifference, ... GroupByColor=metricsResults.BiasMetrics.ModelNames) ax = gca; ax.XTick = []; ylabel("Equal Opportunity Difference") legend
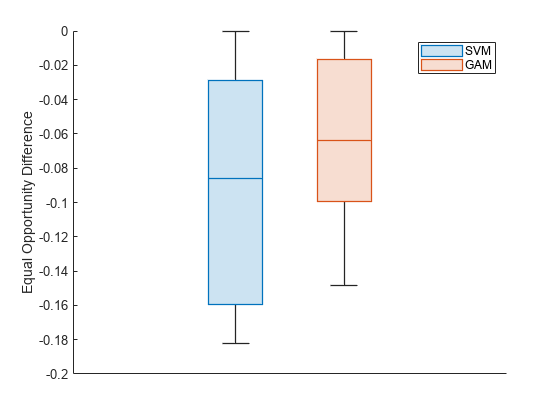
EOD の値は、SVM の値に比べて GAM の方が 0 に近くなっています。