事後分類確率のプロット
この例では、単純ベイズ分類モデルによって予測した事後分類確率を可視化する方法を示します。
フィッシャーのアヤメのデータ セットを読み込みます。
load fisheriris
X = meas(:,1:2);
Y = species;
labels = unique(Y);X は、150 本のアヤメについて 2 つのがく片の測定値が含まれている数値行列です。Y は、対応するアヤメの種類が含まれている文字ベクトルの cell 配列です。
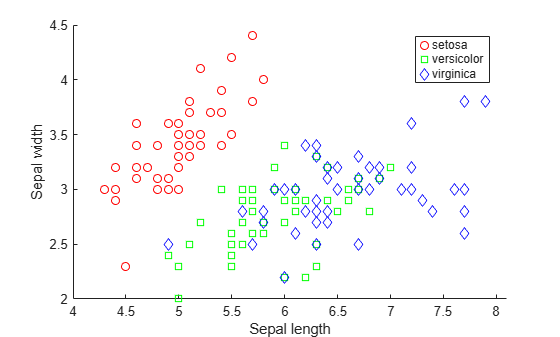
散布図を使用してデータを可視化します。アヤメの種類によって変数をグループ化します。
figure; gscatter(X(:,1), X(:,2), species,'rgb','osd'); xlabel('Sepal length'); ylabel('Sepal width');
単純ベイズ分類器を学習させます。
mdl = fitcnb(X,Y);
mdl は学習させた ClassificationNaiveBayes 分類器です。
データの一定境界内で空間全体に広がる点のグリッドを作成します。X(:,1) のデータは 4.3 ~ 7.9 の範囲にあります。X(:,2) のデータは 2 ~ 4.4 の範囲にあります。
[xx1, xx2] = meshgrid(4:.01:8,2:.01:4.5); XGrid = [xx1(:) xx2(:)];
mdl を使用して、アヤメの種類と XGrid 内の各観測値の事後クラス確率を予測します。
[predictedspecies,Posterior,~] = predict(mdl,XGrid);
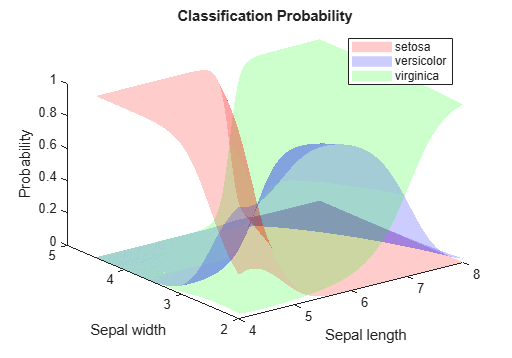
種類ごとに事後確率分布をプロットします。
sz = size(xx1); s = max(Posterior,[],2); figure hold on surf(xx1,xx2,reshape(Posterior(:,1),sz),'EdgeColor','none') surf(xx1,xx2,reshape(Posterior(:,2),sz),'EdgeColor','none') surf(xx1,xx2,reshape(Posterior(:,3),sz),'EdgeColor','none') xlabel('Sepal length'); ylabel('Sepal width'); colorbar view(2) hold off
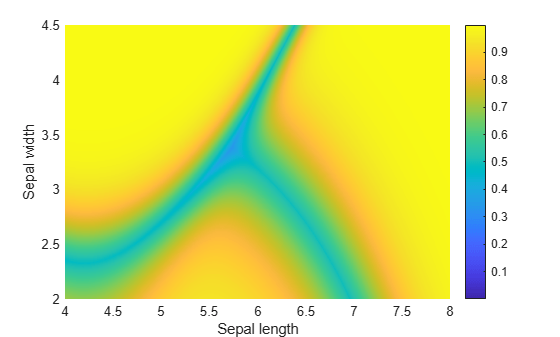
観測値が決定面に近いほど、データが特定の種類に属する可能性が小さくなります。
分類確率分布を個別にプロットします。
figure('Units','Normalized','Position',[0.25,0.55,0.4,0.35]); hold on surf(xx1,xx2,reshape(Posterior(:,1),sz),'FaceColor','red','EdgeColor','none') surf(xx1,xx2,reshape(Posterior(:,2),sz),'FaceColor','blue','EdgeColor','none') surf(xx1,xx2,reshape(Posterior(:,3),sz),'FaceColor','green','EdgeColor','none') xlabel('Sepal length'); ylabel('Sepal width'); zlabel('Probability'); legend(labels) title('Classification Probability') alpha(0.2) view(3) hold off