実際のラボ処理データからシンプル モデルの推定
この例では、実際のラボ処理データからシンプルなモデルを開発し解析する方法を示します。まず最初に、プロセスの概要から説明し、データをツールボックスにインポートし、それを前処理/条件設定した後、体系的に処理を進めて、パラメトリックおよびノンパラメトリック モデルを推定する方法を学びます。モデルを特定したら、推定モデルを比較します。また、モデルを、実験からの実際の結果に対して検証します。
システムの説明
このケース スタディでは、ラボ スケール"ヘアドライヤー" から収集したデータを対象としています (『Feedback's Process Trainer PT326、Ljung、1999』の 525 ページも参照)。手順は次のとおりです。空気は、チューブから送風され、入口で加熱されます。空気の温度は、出口の熱電対で測定されます。入力は、加熱装置 (単なる抵抗線の網) 全体に掛かる電圧です。出力は、出口での空気温度であり、熱電対電圧の測定値で表現されます。
解析用のデータの設定
最初に入出力データを MATLAB® ワークスペースに読み込みます。
load dryer2;
ベクトル y2 (出力) には熱電対電圧の測定値 1000 件が含まれ、この電圧は出口での空流の温度に比例します。ベクトル u2 には、ヒーターに印加された電圧を表す 1000 の入力データ点が含まれています。入力は、バイナリの任意シーケンスとして生成され、確率 0.2 で相互に切り替えられます。サンプル時間は 0.08 秒です。
次のステップでは、iddata オブジェクトとしてデータを設定します。
dry = iddata(y2,u2,0.08);
データに関する情報を得るには、MATLAB コマンド ウィンドウで iddata オブジェクトの名前を入力します。
dry
dry =
Time domain data set with 1000 samples.
Sample time: 0.08 seconds
Outputs Unit (if specified)
y1
Inputs Unit (if specified)
u1
上記の iddata オブジェクトのプロパティを検証するには、get コマンドを使用します。
get(dry)
ans =
struct with fields:
Domain: 'Time'
Name: ''
OutputData: [1000×1 double]
OutputName: {'y1'}
OutputUnit: {''}
InputData: [1000×1 double]
InputName: {'u1'}
InputUnit: {''}
Period: Inf
InterSample: 'zoh'
Ts: 0.0800
Tstart: 0.0800
SamplingInstants: [1000×1 double]
TimeUnit: 'seconds'
ExperimentName: 'Exp1'
Notes: [0×1 string]
UserData: []
データの記録を容易にするため、入力および出力チャネルと時間単位に名前を付けることをお勧めします。これらの名前は、iddata オブジェクトの解析全体で継承して使用されます。
dry.InputName = 'Heater Voltage'; dry.OutputName = 'Thermocouple Voltage'; dry.TimeUnit = 'seconds'; dry.InputUnit = 'V'; dry.OutputUnit = 'V';
データが設定できたら、モデル推定に最初の 300 データ点を選択します。
ze = dry(1:300)
ze =
Time domain data set with 300 samples.
Sample time: 0.08 seconds
Outputs Unit (if specified)
Thermocouple Voltage V
Inputs Unit (if specified)
Heater Voltage V
データの前処理
サンプル 200 ~ 300 の間をプロットします。
plot(ze(200:300));

図 1: 測定したヘアドライヤー データのスナップショット。
上記のプロットでは、データが平均 0 ではありません。このため、一定レベルを除去して、データの平均値を 0 にします。
ze = detrend(ze);
トレンド除去後の同じデータセット:
plot(ze(200:300)) %show samples from 200 to 300 of detrended data
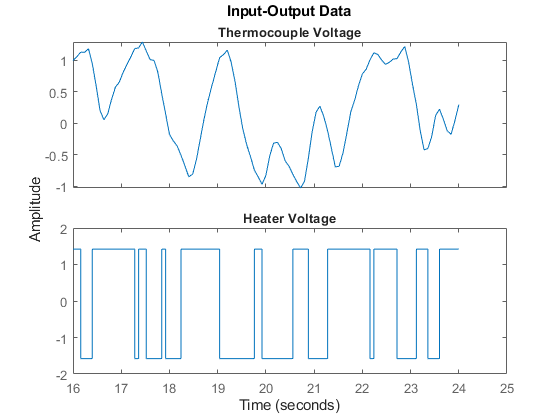
図 2: トレンド除去済み推定データ
ノンパラメトリックおよびパラメトリック モデルの推定
データセットをトレンド除去し、明らかな外れ値がなくなったら、相関解析により、時定数などの概要を取得して、システムのインパルス応答をまず推定します。
clf mi = impulseest(ze); % non-parametric (FIR) model showConfidence(impulseplot(mi),3); %impulse response with 3 standard %deviations confidence region
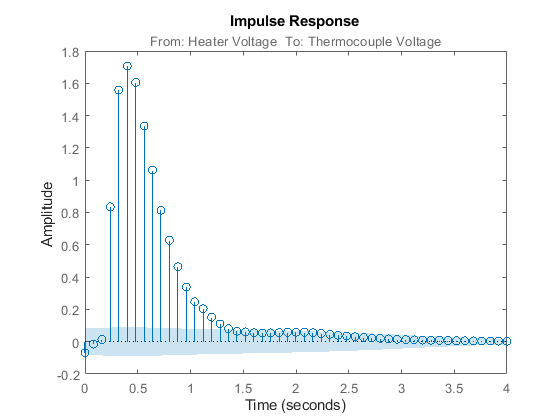
図 3: ze を使用して推定した FIR モデルのインパルス応答。
影の付いた領域は 99.7 % の信頼区間を示しています。出力が入力に応答する前に、3 サンプルの時間遅延 (デッド タイム) が生じます (信頼区間外の有意な出力)。
パラメトリック推定ルーチンを開始する最も簡単な方法は、状態空間モデルを作成することです。ここで、モデル次数は予測誤差法を使用して自動的に決定されます。ssest 推定手法を使って、モデルを推定してみましょう。
m1 = ssest(ze);
m1 は、idss オブジェクトによって表される、連続時間で同定された状態空間モデルです。推定アルゴリズムは、モデルの最適次数として 3 を選択します。推定モデルのプロパティを検証するには、コマンド ウィンドウでモデル名を入力します。
m1
m1 =
Continuous-time identified state-space model:
dx/dt = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3
x1 -0.4839 -2.011 -2.092
x2 3.321 -1.913 -5.998
x3 -1.623 17.01 -15.61
B =
Heater Volta
x1 -0.05753
x2 0.02004
x3 -1.377
C =
x1 x2 x3
Thermocouple -14.07 0.07729 -0.04252
D =
Heater Volta
Thermocouple 0
K =
Thermocouple
x1 -0.9457
x2 -0.02097
x3 -2.102
Parameterization:
FREE form (all coefficients in A, B, C free).
Feedthrough: none
Disturbance component: estimate
Number of free coefficients: 18
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using SSEST on time domain data "ze".
Fit to estimation data: 95.32% (prediction focus)
FPE: 0.001621, MSE: 0.001526
この表示は、モデルが自由なフォーム (A、B、C 行列のすべてのエントリが自由パラメーターとして扱われる) であること、および推定されたモデルはデータがよく適合されていること (90% 以上の適合) を示しています。たとえば、前述のように出力した離散状態空間オブジェクトの A 行列など、このモデルのプロパティを取得するには、ドット演算子を使用できます。
A = m1.a;
モデル オブジェクトの詳細については、「System Identification Toolbox のデータおよびモデル オブジェクト」の例を参照してください。どのモデル オブジェクトのプロパティを取得できるかを確認するには、get コマンドを使用します。
get(m1)
A: [3×3 double]
B: [3×1 double]
C: [-14.0706 0.0773 -0.0425]
D: 0
K: [3×1 double]
StateName: {3×1 cell}
StateUnit: {3×1 cell}
Structure: [1×1 pmodel.ss]
NoiseVariance: 1.2587e-04
InputDelay: 0
OutputDelay: 0
InputName: {'Heater Voltage'}
InputUnit: {'V'}
InputGroup: [1×1 struct]
OutputName: {'Thermocouple Voltage'}
OutputUnit: {'V'}
OutputGroup: [1×1 struct]
Notes: [0×1 string]
UserData: []
Name: ''
Ts: 0
TimeUnit: 'seconds'
SamplingGrid: [1×1 struct]
Report: [1×1 idresults.ssest]
状態空間行列とその標準偏差 1 の不確かさの値を取得するには、idssdata コマンドを使用します。
[A,B,C,D,K,~,dA,dB,dC,dD,dK] = idssdata(m1)
A =
-0.4839 -2.0112 -2.0917
3.3205 -1.9135 -5.9981
-1.6235 17.0096 -15.6070
B =
-0.0575
0.0200
-1.3770
C =
-14.0706 0.0773 -0.0425
D =
0
K =
-0.9457
-0.0210
-2.1019
dA =
1.0e+15 *
0.1414 0.1053 0.0817
0.2948 0.2484 0.2281
1.0851 0.6232 0.2095
dB =
1.0e+13 *
0.2923
1.5163
5.3516
dC =
1.0e+14 *
2.3776 1.8020 0.3162
dD =
0
dK =
1.0e+13 *
1.4700
4.6898
8.2659
モデルは推定データをよく適合していますが、不確かさはかなり大きくなっています。これはモデルがパラメーター化され過ぎているからです。すなわち、一意に同定できるもの以上に多くの自由パラメーターがあるためです。このような場合のパラメーターの分散は明確に定義されていません。ただし、このことはモデルが信頼できないということを意味しているわけではありません。このプロットの時間応答および周波数応答をプロットしたり、次の検討するように信頼領域として分散を表示したりできます。
推定モデルの分析
出力したモデルのボード線図は、以下のように関数 bode を使用して取得できます。
h = bodeplot(m1);
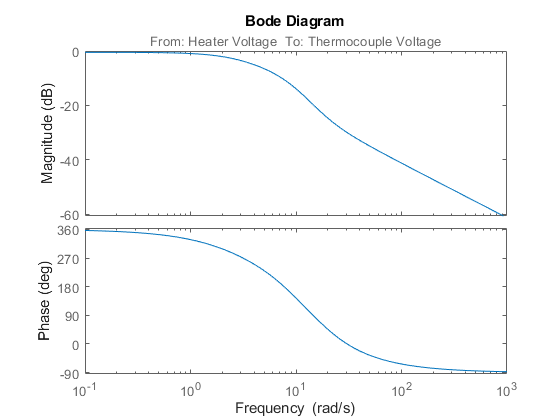
図 4: 推定モデルのボード線図。
プロットを右クリックし、[特性]、[信頼領域] を選択します。または、showConfidence コマンドを使用して、応答の分散を表示します。
showConfidence(h,3) % 3 standard deviation (99.7%) confidence region
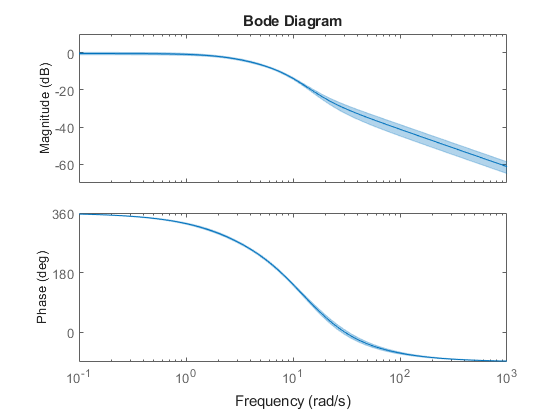
図 5: 標準偏差 3 の信頼領域をもつボード線図
同様に、ステップ プロットとそれに関連する標準偏差 3 の信頼領域を生成できます。次のように、パラメトリック モデル m1 とノンパラメトリック モデル mi で応答と関連する分散を比較できます。
showConfidence(stepplot(m1,'b',mi,'r',3),3)

図 6: 信頼領域をもつモデル m1 と mi のステップ プロット。
ナイキスト線図を用いて、標準偏差 3 に対応する、特定周波数の不確実領域に楕円形でマークすることもできます。
Opt = nyquistoptions;
Opt.ShowFullContour = 'off';
showConfidence(nyquistplot(m1,Opt),3)

図 7: 特定周波数の不確実領域を示す推定モデルのナイキスト線図。
応答プロットは、推定されたモデル m1 がかなり信頼できることを示しています。
規定の構造によるモデルの推定
System Identification Toolbox™ は、規定の構造のモデルを取得するときにも使用できます。たとえば、以下のように、関数 arx を使用して、2 極、1 零点および 3 サンプル遅延の差分方程式モデルを取得できます。
m2 = arx(ze,[2 2 3]);
モデルを表示するには、コマンド ウィンドウでモデル名を入力します。
m2
m2 =
Discrete-time ARX model: A(z)y(t) = B(z)u(t) + e(t)
A(z) = 1 - 1.274 z^-1 + 0.3942 z^-2
B(z) = 0.06679 z^-3 + 0.04429 z^-4
Sample time: 0.08 seconds
Parameterization:
Polynomial orders: na=2 nb=2 nk=3
Number of free coefficients: 4
Use "polydata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using ARX on time domain data "ze".
Fit to estimation data: 95.08% (prediction focus)
FPE: 0.001756, MSE: 0.001687
tfest コマンドを使用して、2 つの極、1 つの零点、0.2 秒の伝達遅延をもつ連続時間の伝達関数を推定できます。
m3 = tfest(ze, 2, 1, 0.2)
m3 =
From input "Heater Voltage" to output "Thermocouple Voltage":
1.183 s + 26.55
exp(-0.2*s) * ---------------------
s^2 + 11.61 s + 28.63
Continuous-time identified transfer function.
Parameterization:
Number of poles: 2 Number of zeros: 1
Number of free coefficients: 4
Use "tfdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using TFEST on time domain data "ze".
Fit to estimation data: 88.79%
FPE: 0.009126, MSE: 0.008768
実験結果に対する推定モデルの検証
推定モデルの適合度1 つの方法としては、推定モデルの適合度をシミュレートし、モデル出力を測定出力と比較します。モデルの作成に使用しなかったオリジナル データの一部、たとえば、サンプル 800 から 900 までを選択します。検証データを前処理したら、以下のように関数 compare を使用して、予測の精度を表示します。
zv = dry(800:900); % select an independent data set for validation zv = detrend(zv); % preprocess the validation data set(gcf,'DefaultLegendLocation','best') compare(zv,m1); % perform comparison of simulated output
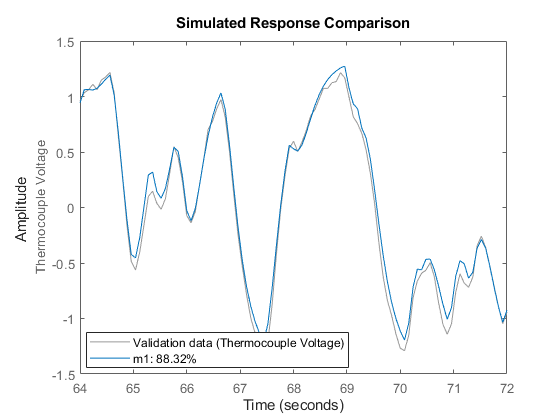
図 8: モデルのシミュレーション応答と検証データ出力。
非常に良好な適合を確認できます。"適合" 値は、次のように計算されます。
Fit = 100*(1 - norm(yh - y)/norm(y-mean(y)))
ここで、y は測定出力 (=|zv.y|)、yh はモデル m1 の出力です。
推定モデルの比較
推定したモデルのパフォーマンスを比較する場合にも (たとえば、m1、m2 および m3 の検証データ zv)、compare コマンドを使用できます。
compare(zv,m1,'b',m2,'r',m3,'c');
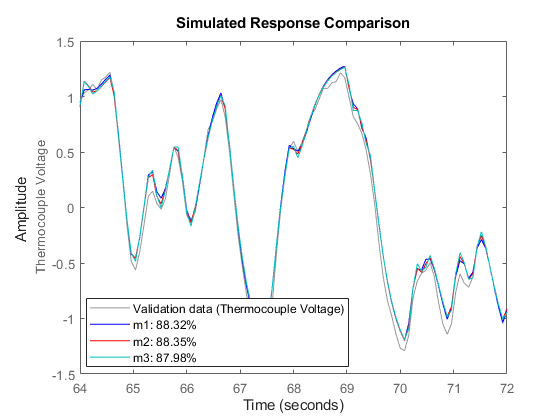
図 9: 検証データセット ze におけるモデル m1、m2 および m3 の応答の比較。
m3 は連続時間システムなので、pade 関数を使用して伝達遅延を近似します。その後、iopzplot を使用してモデルの極-零点プロットを取得できます。
m3x = pade(m3,2); h = iopzplot(m1,'b',m2,'r',m3x,'c');
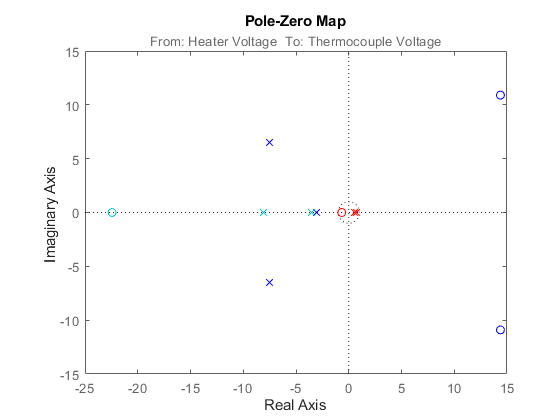
図 10: モデル m1、m2 および m3 の極と零点。
また、極と零点の不確かさも取得できます。以下のステートメントで、'3' は標準偏差数を示します。
showConfidence(h,3);
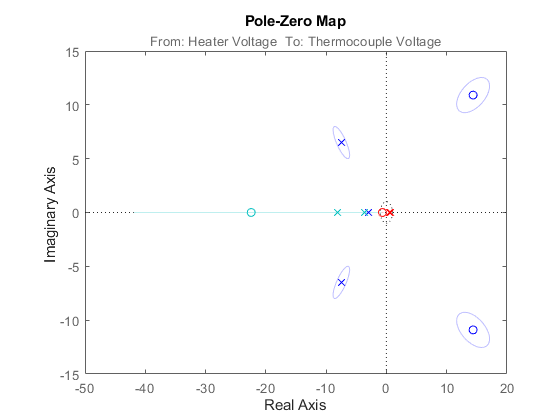
図 11: 不確実領域の極-零点図
モデルから取得した上記の周波数関数は、ノンパラメトリック スペクトル解析メソッドを使用して取得した出力と比較できます (spa)。
gs = spa(ze);
spa コマンドでは、IDFRD モデルが出力されます。ここでも、関数 bode を使用して、取得したモデルの伝達関数と比較できます。
w = linspace(0.4,pi/m2.Ts,200); opt = bodeoptions; opt.PhaseMatching = 'on'; bodeplot(m1,'b',m2,'r',m3,'c',gs,'g',w,opt); legend('m1','m2','m3','gs')
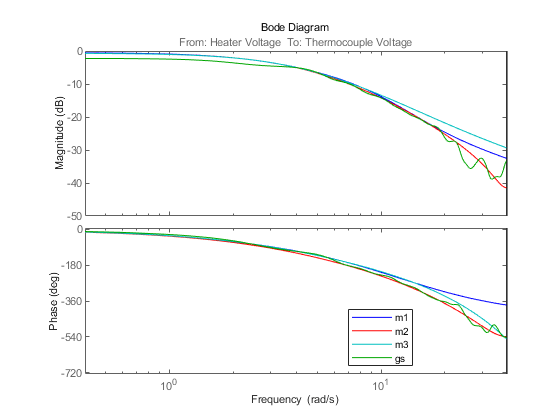
図 12: ノンパラメトリック スペクトル推定モデル gs と比較した m1、m2 および m3 のボード応答。
3 つのモデル/メソッドの周波数応答は、非常に近くなっています。これは、応答の信頼性が高いことを示します。
また、特定周波数でマークした不確実領域に基づいて、ナイキスト線図を分析することもできます。
showConfidence(nyquistplot(m1,'b',m2,'r',m3,'c',gs,'g'),3)
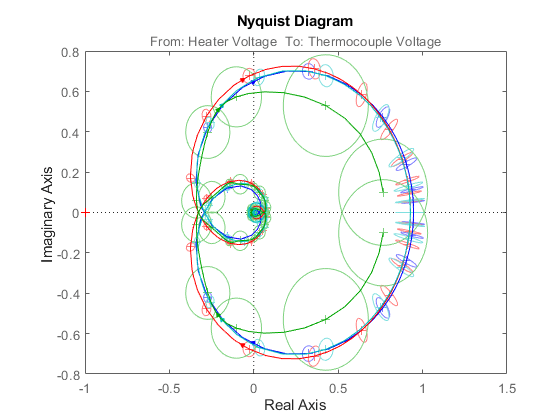
図 13: モデル m1、m2、m3 および gs のナイキスト線図。
ノンパラメトリック モデル gs は、応答が最も不確実であることを示しています。