Credit Scorecard Modeling with Missing Values
This example shows how to handle missing values when you work with creditscorecard objects. First, the example shows how to use the creditscorecard functionality to create an explicit bin for missing data with corresponding points. Then, this example describes four different ways to "treat" the missing data to get a final credit scorecard with no explicit bins for missing values.
Develop a Credit Scorecard with Explicit Bins for Missing Values
When you create a creditscorecard object, the data can contain missing values. When using creditscorecard to create a creditscorecard object, you can set the name-value pair argument for 'BinMissingData' set to true. In this case, the missing data for numeric predictors (NaN values) and for categorical predictors (<undefined> values) is binned in a separate bin labeled <missing> that appears at the end of the bins. Predictors with no missing values in the training data have no <missing> bin. If you do not specify the 'BinMissingData' argument or if you set 'BinMissingData' to false, the creditscorecard function discards missing observations when computing frequencies of Good and Bad, and neither the bininfo nor plotbins functions reports such observations.
The <missing> bin remains in place throughout the scorecard modeling process. The final scorecard explicitly indicates the points to be assigned to missing values for predictors that have a <missing> bin. These points are determined from the weight-of-evidence (WOE) value of the <missing> bin and the predictor's coefficient in the logistic model. For predictors without an explicit <missing> bin, you can assign points to missing values using the name-value pair argument 'Missing' in formatpoints, as described in this example, or by using one of the four different ways to "treat" the missing data.
The dataMissing table in the CreditCardData.mat file has two predictors with missing values — CustAge and ResStatus.
load CreditCardData.mat
head(dataMissing,5) CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ ___________ _________ __________ _______ _______ _________ ________ ______
1 53 62 <undefined> Unknown 50000 55 Yes 1055.9 0.22 0
2 61 22 Home Owner Employed 52000 25 Yes 1161.6 0.24 0
3 47 30 Tenant Employed 37000 61 No 877.23 0.29 0
4 NaN 75 Home Owner Employed 53000 20 Yes 157.37 0.08 0
5 68 56 Home Owner Employed 53000 14 Yes 561.84 0.11 0
Create a creditscorecard object using the CreditCardData.mat file to load the dataMissing table with missing values. Set the 'BinMissingData' argument to true. Apply automatic binning.
sc = creditscorecard(dataMissing,'IDVar','CustID','BinMissingData',true); sc = autobinning(sc);
The bin information and bin plots for the predictors that have missing data both show a <missing> bin at the end.
bi = bininfo(sc,'CustAge');
disp(bi) Bin Good Bad Odds WOE InfoValue
_____________ ____ ___ ______ ________ __________
{'[-Inf,33)'} 69 52 1.3269 -0.42156 0.018993
{'[33,37)' } 63 45 1.4 -0.36795 0.012839
{'[37,40)' } 72 47 1.5319 -0.2779 0.0079824
{'[40,46)' } 172 89 1.9326 -0.04556 0.0004549
{'[46,48)' } 59 25 2.36 0.15424 0.0016199
{'[48,51)' } 99 41 2.4146 0.17713 0.0035449
{'[51,58)' } 157 62 2.5323 0.22469 0.0088407
{'[58,Inf]' } 93 25 3.72 0.60931 0.032198
{'<missing>'} 19 11 1.7273 -0.15787 0.00063885
{'Totals' } 803 397 2.0227 NaN 0.087112
plotbins(sc,'CustAge')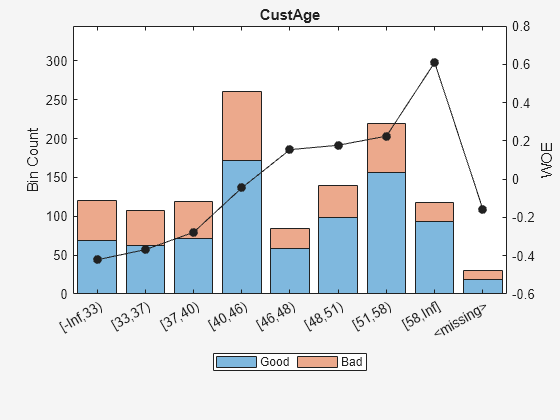
bi = bininfo(sc,'ResStatus');
disp(bi) Bin Good Bad Odds WOE InfoValue
______________ ____ ___ ______ _________ __________
{'Tenant' } 296 161 1.8385 -0.095463 0.0035249
{'Home Owner'} 352 171 2.0585 0.017549 0.00013382
{'Other' } 128 52 2.4615 0.19637 0.0055808
{'<missing>' } 27 13 2.0769 0.026469 2.3248e-05
{'Totals' } 803 397 2.0227 NaN 0.0092627
plotbins(sc,'ResStatus')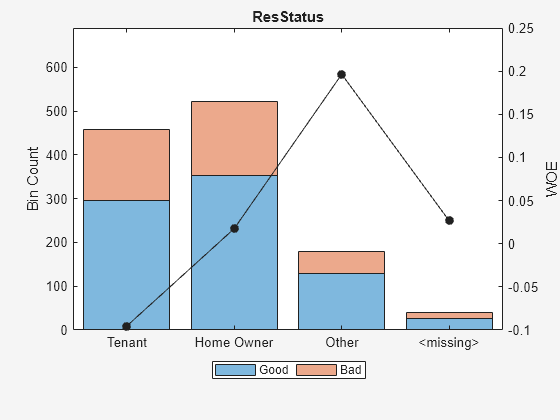
The training data for the 'CustAge' and 'ResStatus' predictors has missing data (NaNs and <undefined>). The binning process estimates WOE values of -0.15787 and 0.026469, respectively, for the missing data in these predictors.
The training data for EmpStatus and CustIncome has no explicit bin for <missing> values because there are no missing values for these predictors.
bi = bininfo(sc,'EmpStatus');
disp(bi) Bin Good Bad Odds WOE InfoValue
____________ ____ ___ ______ ________ _________
{'Unknown' } 396 239 1.6569 -0.19947 0.021715
{'Employed'} 407 158 2.5759 0.2418 0.026323
{'Totals' } 803 397 2.0227 NaN 0.048038
bi = bininfo(sc,'CustIncome');
disp(bi) Bin Good Bad Odds WOE InfoValue
_________________ ____ ___ _______ _________ __________
{'[-Inf,29000)' } 53 58 0.91379 -0.79457 0.06364
{'[29000,33000)'} 74 49 1.5102 -0.29217 0.0091366
{'[33000,35000)'} 68 36 1.8889 -0.06843 0.00041042
{'[35000,40000)'} 193 98 1.9694 -0.026696 0.00017359
{'[40000,42000)'} 68 34 2 -0.011271 1.0819e-05
{'[42000,47000)'} 164 66 2.4848 0.20579 0.0078175
{'[47000,Inf]' } 183 56 3.2679 0.47972 0.041657
{'Totals' } 803 397 2.0227 NaN 0.12285
Use fitmodel to fit a logistic regression model using WOE values. fitmodel internally transforms all the predictor variables into WOE values, using the bins found during the automatic binning process. By default, fitmodel then fits a logistic regression model using a stepwise method. For predictors that have missing data, there is an explicit <missing> bin with a corresponding WOE value computed from the data. When you use fitmodel, the corresponding WOE value for the <missing> bin is applied when the function performs the WOE transformation.
[sc,mdl] = fitmodel(sc,'display','off');
Scale the scorecard points by the points-to-double-the-odds (PDO) method using the 'PointsOddsAndPDO' argument of formatpoints. Suppose that you want a score of 500 points to have odds of 2 (twice as likely to be good than to be bad) and that the odds double every 50 points (so that 550 points would have odds of 4).
Display the scorecard showing the scaled points for predictors retained in the fitting model.
sc = formatpoints(sc,'PointsOddsAndPDO',[500 2 50]);
PointsInfo = displaypoints(sc)PointsInfo=38×3 table
Predictors Bin Points
_____________ ______________ ______
{'CustAge' } {'[-Inf,33)' } 54.062
{'CustAge' } {'[33,37)' } 56.282
{'CustAge' } {'[37,40)' } 60.012
{'CustAge' } {'[40,46)' } 69.636
{'CustAge' } {'[46,48)' } 77.912
{'CustAge' } {'[48,51)' } 78.86
{'CustAge' } {'[51,58)' } 80.83
{'CustAge' } {'[58,Inf]' } 96.76
{'CustAge' } {'<missing>' } 64.984
{'ResStatus'} {'Tenant' } 62.138
{'ResStatus'} {'Home Owner'} 73.248
{'ResStatus'} {'Other' } 90.828
{'ResStatus'} {'<missing>' } 74.125
{'EmpStatus'} {'Unknown' } 58.807
{'EmpStatus'} {'Employed' } 86.937
{'EmpStatus'} {'<missing>' } NaN
⋮
Notice that points for the <missing> bins for CustAge and ResStatus are explicitly shown (as 64.9836 and 74.1250, respectively). These points are computed from the WOE value for the <missing> bin and the logistic model coefficients.
Points for predictors that have no missing data in the training set, by default, are set to NaN and they lead to a score of NaN when you run score. This can be changed by updating the name-value pair argument 'Missing' in formatpoints to indicate how to treat missing data for scoring purposes.
The scorecard is ready for scoring new data sets. You can also use the scorecard to compute probabilities of default or perform model validation. For details, see score, probdefault, and validatemodel. To further explore the handling of missing data, take a few rows from the original data as test data and introduce some missing data.
tdata = dataMissing(11:14,mdl.PredictorNames); % Keep only the predictors retained in the model % Set some missing values tdata.CustAge(1) = NaN; tdata.ResStatus(2) = missing; tdata.EmpStatus(3) = missing; tdata.CustIncome(4) = NaN; disp(tdata)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ ___________ ___________ __________ _______ _______ _________
NaN Tenant Unknown 34000 44 Yes 119.8
48 <undefined> Unknown 44000 14 Yes 403.62
65 Home Owner <undefined> 48000 6 No 111.88
44 Other Unknown NaN 35 No 436.41
Score the new data and see how points for missing data are differently assigned for CustAge and ResStatus and for EmpStatus and CustIncome. CustAge and ResStatus have an explicit <missing> bin for missing data. However, for EmpStatus and CustIncome, the score function sets the points to NaN.
[Scores,Points] = score(sc,tdata); disp(Scores)
481.2231
520.8353
NaN
NaN
disp(Points)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
64.984 62.138 58.807 67.893 61.858 75.622 89.922
78.86 74.125 58.807 82.439 61.061 75.622 89.922
96.76 73.248 NaN 96.969 51.132 50.914 89.922
69.636 90.828 58.807 NaN 61.858 50.914 89.922
Use the name-value pair argument 'Missing' in formatpoints to choose how to assign points to missing values for predictors that do not have an explicit <missing> bin. For this example, use the 'MinPoints' option for the 'Missing' argument. For EmpStatus and CustIncome, the minimum numbers of points in the scorecard are 58.8072 and 29.3753, respectively. You can also treat missing values using one of the four different ways to "treat" the missing data.
sc = formatpoints(sc,'Missing','MinPoints'); [Scores,Points] = score(sc,tdata); disp(Scores)
481.2231 520.8353 517.7532 451.3405
disp(Points)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
64.984 62.138 58.807 67.893 61.858 75.622 89.922
78.86 74.125 58.807 82.439 61.061 75.622 89.922
96.76 73.248 58.807 96.969 51.132 50.914 89.922
69.636 90.828 58.807 29.375 61.858 50.914 89.922
Four Approaches for Treating Missing Data and Developing a New Credit Scorecard
There are four different approaches for treating missing data.
Approach 1: Fill missing data using the fillmissing function of the creditscorecard object
The creditscorecard object supports a fillmissing function. When you call the function on a predictor or group of predictors, the fillmissing function fills the missing data with the user-specified statistic. fillmissing supports the fill values 'mean', 'median', 'mode', and 'constant', as well as the option to switch back to the original data.
The advantage of using fillmissing is that the creditscorecard object keeps track of the fill value and also applies it to the validation data. The limitation of this approach is that only basic statistics are used to fill missing data.
For more information on Approach 1, see fillmissing.
Approach 2: Fill missing data using the MATLAB® fillmissing function
MATLAB® supports a fillmissing function that you can use before creating a creditscorecard object to treat missing values in numeric and categorical data. The advantage of this method is that you can use all the options available in fillmissing to fill missing data, as well as other MATLAB functionality, such as standardizeMissing and features for the treatment of outliers. However, the downside is that you are responsible for the same transformations to the validation data before scoring as the fillmissing function is outside of the creditscorecard object.
For more information on Approach 2, see Treat Missing Data in a Credit Scorecard Workflow Using MATLAB fillmissing.
Approach 3: Impute missing data using the k-nearest neighbors (KNN) algorithm
This KNN approach considers multiple predictors as compared to Approach 1 and Approach 2. Like Approach 2, the KNN approach is done outside the creditscoreacrd workflow, and consequently, you need to perform imputation for both the training and validation data.
For more information on Approach 3, see Impute Missing Data in the Credit Scorecard Workflow Using the k-Nearest Neighbors Algorithm.
Approach 4: Impute missing data using the random forest algorithm
This random forest approach is similar to Approach 3 and uses multiple predictors to impute missing values. Because the approach is outside the creditscorecard workflow, you need to perform imputation for both the training and validation data.
For more information on Approach 4, see Impute Missing Data in the Credit Scorecard Workflow Using the Random Forest Algorithm.
See Also
creditscorecard | bininfo | plotbins | fillmissing