Fit Bayesian Stochastic Volatility Model to S&P 500 Volatility
This example fits a Bayesian stochastic volatility model to daily S&P 500 closing returns, and then it forecasts the volatility into a two-week horizon.
Load and Preprocess Data
Load the data set Data_GlobalIdx1.mat, which contains daily closing prices of selected global equity indices spanning trading dates 1993-04-27 through 2003-07-14. Extract the S&P 500 closing prices, which is the last column of the matrix Data.
load Data_GlobalIdx1 sp500 = Data(:,end); T = numel(sp500); dts = datetime(dates,ConvertFrom="datenum");
Plot the series.
figure plot(dts,sp500) title("S&P 500 Closing Prices") ylabel("Closing Price (USD)")
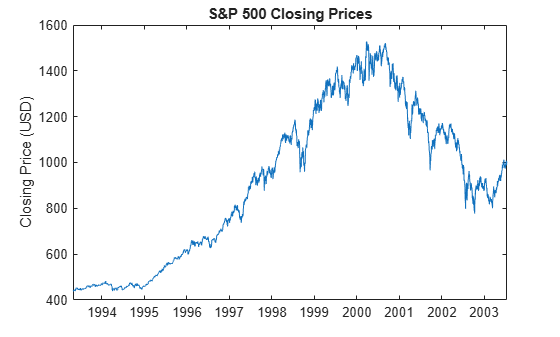
The series appears to be a random walk process; such processes are difficult to predict in levels. However, asset price series can exhibit volatility clustering, where price changes tend to be followed by price changes of similar magnitudes. The squared returns of an asset price series can exhibit predictable patterns, an exploitable characteristic for volatility forecasting.
Convert the price series to returns. Plot the returns.
retsp500 = price2ret(sp500); retdts = dts(2:end); figure plot(retdts,100*retsp500) title("S&P 500 Daily Returns") ylabel("Return (%)")
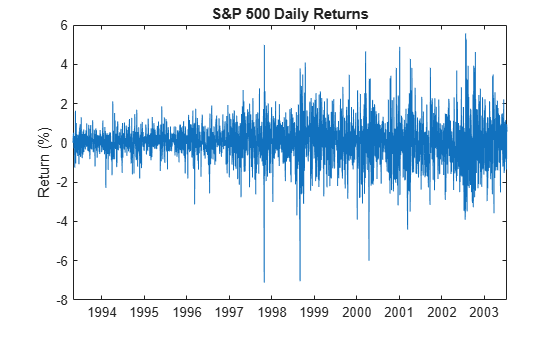
The plot indicates that price changes of similar magnitudes tend to follow each other.
Determine further whether the returns have serial correlation and volatility cluster further by plotting the autocorrelation function (ACF) of the returns series and its square.
figure autocorr(retsp500)
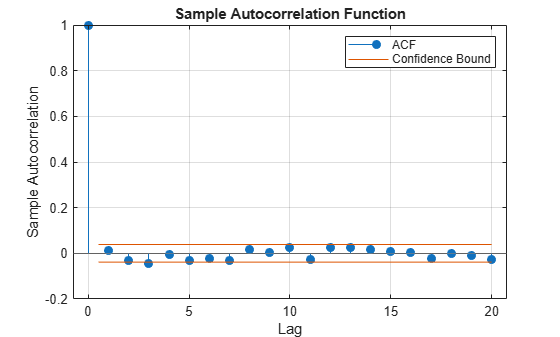
figure autocorr(retsp500.^2)
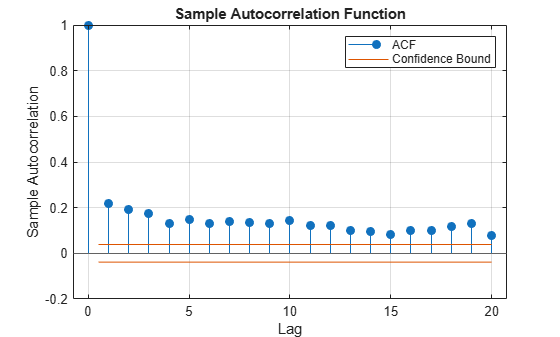
The correlogram of the returns indicates that no significant serial correlation exists in the series. However, the correlogram of the squared returns shows persistent serial correlation, which indicates that volatility clustering exists in the returns.
Create Bayesian State-Space Model
Econometric Toolbox™ has a suite of Conditional Variance Models objects (for example, garch object represents a GARCH model) that model volatility clustering when the observation innovations process is an iid Gaussian or Student's random series. However, a limitation of the GARCH model and its extensions is, given returns up to time , the conditional variance of the return at time is not stochastic.
The stochastic volatility model, which also models volatility clustering is asset returns series, can capture richer characteristics in the series because the conditional variance at time is random, even given all past asset prices. Unlike the GARCH model, the likelihood of a stochastic volatility model is analytically intractable, which makes estimation difficult.
The stochastic volatility model for observed asset returns has the following nonlinear state-space form
where:
for daily returns.
is a latent AR(1) process representing the conditional volatility series.
are are mutually independent and individually iid random standard Gaussian noise series.
Econometrics Toolbox state-space model functionalities support linear state-space models. To linearize the model, square and then apply the log transform to both sides of the observation equation.
The random variable has a distribution, which is well approximated by a properly configured 7-regime Gaussian mixture model. Although the resulting model is linear with respect to the parameters, the loglikelihood is intractable. The bssm framework supports a Bayesian view of the model, which accommodates intractable loglikelihoods by implementing Markov chain Monte Carlo (MCMC) methods, such as Metropolis-within-Gibbs sampling.
bssm requires the following inputs:
A function specifying the state-space model structure. The function accepts an input vector
thetaand returns coefficient matrices, initial state moments, and a flag indicating whether the state is stationary.A function specifying the log prior distribution of the state-space model parameters
theta, from which to compose the posterior distribution. The function acceptsthetaand returns the scalar log prior evaluated attheta.
The state-space model has two states , a stationary state and a state that always takes the value 1 to identify , and three parameters, , , and . The coefficient matrices are:
The local function paramMap specifies this model structure.
Assume a flat prior, that is, the log prior is 0 over the support of the parameters and -Inf everywhere else. The local function flatPriorBSSM specifies the prior.
Create a Bayesian state-space model that specifies the model structure and prior distribution. Approximate the distributed observation innovations by specifying that their distribution is a 7-regime finite Gaussian mixture with the following parameter settings:
Regime weight vector is
[0.0089 0.0541 0.1338 0.2761 0.2923 0.1494 0.0854]Regime mean vector is
[-9.3202 -5.3145 -3.4147 -1.7097 -0.4531 0.3975 1.1925]Regime variance vector is
[3.2793 2.4574 1.8874 1.3121 0.8843 0.5898 0.4995].^2
weight = [0.0089 0.0541 0.1338 0.2761 0.2923 0.1494 0.0854]; mu = [-9.3202 -5.3145 -3.4147 -1.7097 -0.4531 0.3975 1.1925]; sigma2 = [3.2793 2.4574 1.8874 1.3121 0.8843 0.5898 0.4995].^2; ObsInnovDist = struct("Name","mixture","Weight",weight, ... "Mean",mu,"Variance",sigma2); PriorMdl = bssm(@paramMap,@flatPriorBSSM,ObservationDistribution=ObsInnovDist);
Estimate Posterior Distribution
Several consecutive days resulted in no change in price, which correspond to -Inf changes on the log-returns scale. Such observations cause computational problems during MCMC sampling.
To avoid -Inf log returns, center the returns before applying the squared log transformation.
y = 2*log(abs(retsp500-mean(retsp500)));
Estimate the posterior distribution of the parameters. estimate uses the Metropolis-within-Gibbs sampler to generate a sample from the posterior. To generate a good quality sample, you must tune the sampler carefully. Specify the following settings:
Specify the univariate treatment of multivariate states.
Use the outer product of gradients to approximate the Hessian.
Specify a burn-in period of 10000 draws.
Specify a sample thinning factor of 25.
Return the posterior distribution, the Bayesian parameter estimates and their estimated covariance matrix, and draws of all parameters and the final states. The sampler, with these settings, takes some time to complete.
theta0 = [0.2 0 0.5]; burnin = 10000; thin = 25; rng(1) [PosteriorMdl,estParams,EstParamCov,PostSumry] = estimate(PriorMdl,y, ... theta0,Univariate=true,Hessian="opg",BurnIn=burnin,Thin=thin);
Local minimum possible.
fminunc stopped because the size of the current step is less than
the value of the step size tolerance.
<stopping criteria details>
Optimization and Tuning
| Params0 Optimized ProposalStd
----------------------------------------
c(1) | 0.2000 0.9962 0.0019
c(2) | 0 -0.0189 0.0097
c(3) | 0.5000 0.0856 0.0140
Posterior Distributions
| Mean Std Quantile05 Quantile95
------------------------------------------------
c(1) | 0.9891 0.0038 0.9831 0.9950
c(2) | -0.0391 0.0139 -0.0619 -0.0179
c(3) | 0.1358 0.0189 0.1073 0.1674
x(1) | -3.4553 0.4089 -4.1031 -2.7180
x(2) | 1 0 1 1
Proposal acceptance rate = 44.28%
Assess Quality of Posterior Sample
Determine the quality of the posterior sample by plotting trace plots of the parameter draws.
figure
plot(PosteriorMdl.ParamDistribution(1,:))
title("Trace Plot: \beta")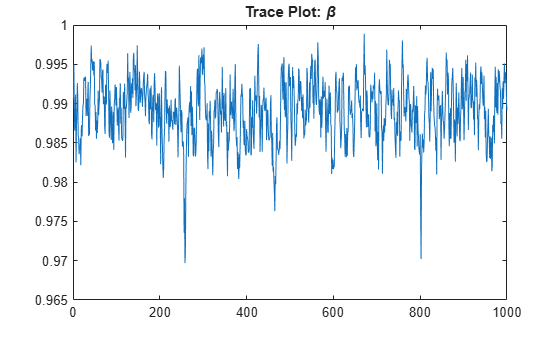
figure
plot(PosteriorMdl.ParamDistribution(2,:))
title("Trace Plot: \alpha")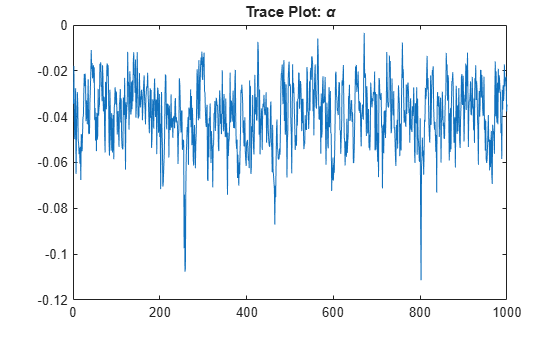
figure
plot(PosteriorMdl.ParamDistribution(3,:))
title("Trace Plot: \sigma")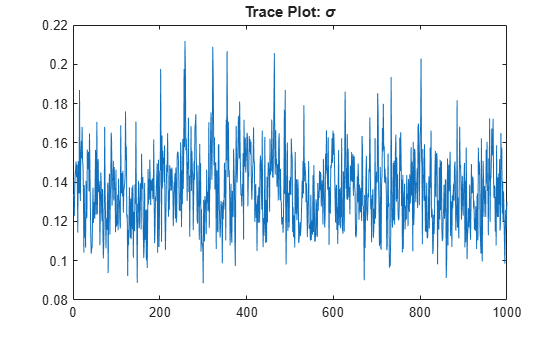
The posterior samples show good mixing with some minor serial correlation.
Forecast Volatility
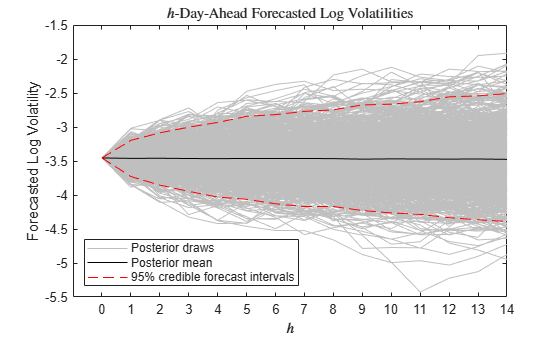
Draw a large sample from the posterior distribution of forecasted log volatility into a 14 day horizon by using the equation
,
where:
, , and are individual draws from the posterior distribution of the corresponding parameter.
.
fh = 14; bigN = 1000; XF = zeros(fh + 1,bigN); XF(1,:) = PostSumry.Mean(4)*ones(1,bigN); betatilde = PosteriorMdl.ParamDistribution(1,(end-(bigN-1)):end); alphatilde = PosteriorMdl.ParamDistribution(2,(end-(bigN-1)):end); sigmatilde = PosteriorMdl.ParamDistribution(3,(end-(bigN-1)):end); for j = 2:(fh+1) XF(j,:) = alphatilde + betatilde.*XF(j-1,:) + sigmatilde.*randn(1,bigN); end
Summarize the posterior distribution of the forecasts by computing the mean of each step into the horizon and the 95% percentile-based credible forecast intervals.
xfmean = mean(XF,2); XFCI = quantile(XF,[0.025 0.975],2); array2table([xfmean XFCI],VariableNames=["PostMean" "CILower" "CIUpper"])
ans=15×3 table
PostMean CILower CIUpper
________ _______ _______
-3.4553 -3.4553 -3.4553
-3.4612 -3.7286 -3.1957
-3.4598 -3.8544 -3.0864
-3.4634 -3.9467 -3.0026
-3.4655 -4.0304 -2.9331
-3.4626 -4.0633 -2.8429
-3.4625 -4.1295 -2.8182
-3.4628 -4.1697 -2.7701
-3.4652 -4.1688 -2.7476
-3.4727 -4.2286 -2.6752
-3.4689 -4.2632 -2.6645
-3.4704 -4.285 -2.6283
-3.472 -4.333 -2.5564
-3.4705 -4.3645 -2.5424
-3.4756 -4.3909 -2.5087
figure h1 = plot(XF,Color=[0.75 0.75 0.75]); hold on h2 = plot(xfmean,"k"); h3 = plot(XFCI,"r--"); title("$h$-Day-Ahead Forecasted Log Volatilities",Interpreter="latex") xticks(1:(fh+1)) xticklabels(0:fh) xlabel("$h$",Interpreter="latex") ylabel("Forecasted Log Volatility") legend([h1(1) h2 h3(1)], ... ["Posterior draws" "Posterior mean" "95% credible forecast intervals"], ... Location="southwest")
Local Functions
This example uses the following functions. paramMap is the parameter-to-matrix mapping function and priorDistribution is the log prior distribution of the parameters.
function [A,B,C,D,Mean0,Cov0,StateType] = paramMap(theta) A = [theta(1) theta(2); 0 1]; B = [theta(3); 0]; C = [1 -log(365)]; D = 1; Mean0 = []; % MATLAB uses default initial state mean Cov0 = []; % MATLAB uses initial state covariances StateType = [0; 1]; % x is stationary and the constant 1 state for alpha end function logprior = flatPriorBSSM(theta) % flatPriorBSSM computes the log of the flat prior density for the three % variables in theta. Log probabilities for parameters outside the % parameter space are -Inf. paramcon = zeros(numel(theta),1); % theta(1) is the lag 1 term in a stationary AR(1) model. The % value needs to be within the unit circle. paramcon(1) = abs(theta(1)) >= 1 - eps; % alpha must be finite paramcon(2) = ~isfinite(theta(2)); % Standard deviation of the state disturbance theta(3) must be positive. paramcon(3) = theta(3) <= eps; if sum(paramcon) > 0 logprior = -Inf; else logprior = 0; % Prior density is proportional to 1 for all values % in the parameter space. end end