生成コードにおけるブロック演算順序の最適化
コードの実行速度を改善するために、ブロック演算を並べ替えるように指定する
モデル コンフィギュレーション ペイン: [コード生成] / [最適化]
説明
[生成コードにおけるブロック演算順序の最適化] パラメーターは、コードの実行速度を改善するために、生成コードでブロック演算を並べ替えるように指定します。
設定
改善されたコードの実行速度 (既定値) | オフオフEmbedded Coder® は、バッファーの再利用の追加インスタンスを作成するために生成コードにおけるブロック演算順序の並べ替えを行うことはありません。
改善されたコードの実行速度Embedded Coder は、バッファーの再利用のインスタンスがより多く発生できるように、生成コードにおけるブロック演算順序を変更します。バッファーを再利用すると、RAM と ROM の消費が抑えられ、コードの実行速度が改善します。
例
この例では、[Optimize block order in the generated code] パラメーターを [オフ] から [Improved Execution Speed] に変更してデータ コピーを削除する方法を示します。この設定を変更することで、可能な場合はブロック演算を並べ替えてデータ コピーを削除するようにコード ジェネレーターに指示します。この最適化により、RAM と ROM の消費量が節約されます。
モデル ex_optimizeblockorder では、Sum ブロックを出た信号は Subtract ブロックと Concatenate ブロックに入ります。Subtract ブロックを出た信号は Product ブロックと Sum of Elements ブロックに入ります。
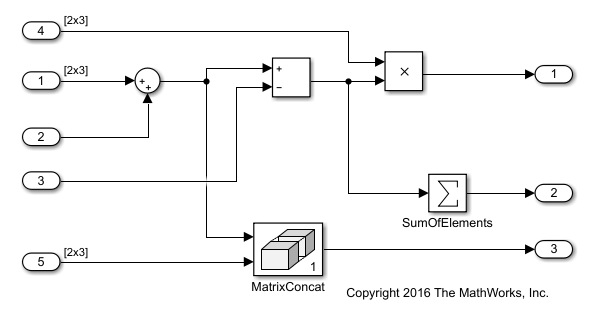
イメージは、モデルのビルド後のモデル ex_optimizeblockorder を示しています。赤い数字は、生成されたコード内の既定のブロック順序を示しています。Subtract ブロックは Concatenate ブロックの前に実行されます。Product ブロックは Sum of Elements ブロックの前に実行されます。
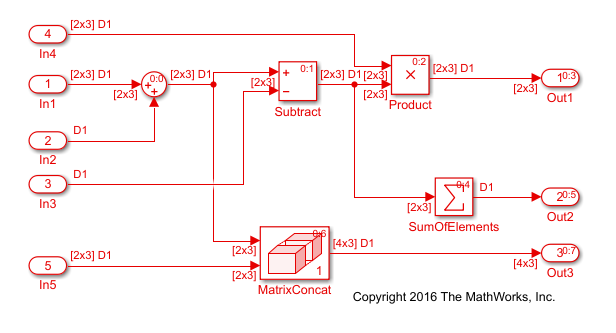
最適化を行わない生成コードを表示します。ex_optimizeblockorder_step 関数を以下に示します。
/* Model step function */
void ex_optimizeblockorder_step(void)
{
real_T rtb_Sum2x3[6];
int32_T i;
real_T rtb_Sum2x3_d;
real_T rtb_Subtract;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 = -0.0;
for (i = 0; i < 6; i++) {
/* Sum: '<Root>/Sum2x3' incorporates:
* Inport: '<Root>/In1'
* Inport: '<Root>/In2'
*/
rtb_Sum2x3_d = rtU.In1[i] + rtU.In2;
/* Sum: '<Root>/Subtract' incorporates:
* Inport: '<Root>/In3'
*/
rtb_Subtract = rtb_Sum2x3_d - rtU.In3;
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/In4'
* Product: '<Root>/Product'
*/
rtY.Out1[i] = rtU.In4[i] * rtb_Subtract;
/* Sum: '<Root>/Sum2x3' */
rtb_Sum2x3[i] = rtb_Sum2x3_d;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 += rtb_Subtract;
}
/* Concatenate: '<Root>/MatrixConcat ' */
for (i = 0; i < 3; i++) {
/* Outport: '<Root>/Out3' incorporates:
* Inport: '<Root>/In5'
*/
rtY.Out3[i << 2] = rtb_Sum2x3[i << 1];
rtY.Out3[2 + (i << 2)] = rtU.In5[i << 1];
rtY.Out3[1 + (i << 2)] = rtb_Sum2x3[(i << 1) + 1];
rtY.Out3[3 + (i << 2)] = rtU.In5[(i << 1) + 1];
}
/* End of Concatenate: '<Root>/MatrixConcat ' */
}既定の順序では、生成されたコードには rtb_Sum2x3[6]、 rtb_Sum2x3_d、および rtb_Subtract という 3 つのバッファーが含まれます。Matrix Concatenate ブロックは Sum ブロックからの出力を使用する必要があり、Sum of Elements ブロックは Subtract ブロックからの出力を使用する必要があるため、生成されたコードにはこれらの一時変数および関連するデータ コピーが含まれます。
イメージは、[生成コードにおけるブロック演算順序の最適化] パラメーターを [Improved Execution Speed] に設定してモデルをビルドした後の ex_optimizeblockorder モデルを示しています。Subtract ブロックは Concatenate ブロックの後に実行されます。Product ブロックは Sum of Elements ブロックの後に実行されます。
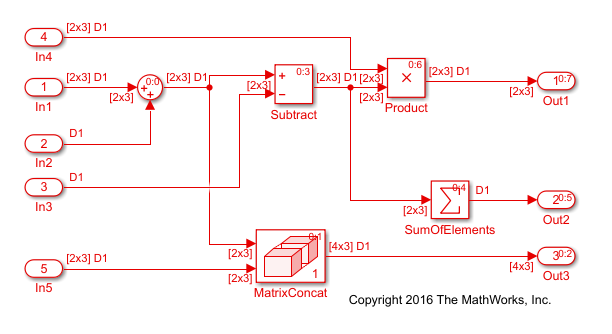
最適化されたコードでは、3 つのバッファー rtb_Sum2x3[6]、rtb_Sum2x3_d、および rtb_Subtract と、それらに関連するデータ コピーは削除されています。生成されたコードでは、Subtract ブロックが Concatenate ブロックの後に実行され、Product ブロックが Sum of Elements ブロックの後に実行されるため、Sum ブロックと Subtract ブロックの出力を保持するためにこれらの一時変数が必要なくなります。
/* Model step function */
void ex_optimizeblockorder_step(void)
{
int32_T i;
/* Sum: '<Root>/Sum2x3' incorporates:
* Inport: '<Root>/In1'
* Inport: '<Root>/In2'
*/
for (i = 0; i < 6; i++) {
rtY.Out1[i] = rtU.In1[i] + rtU.In2;
}
/* End of Sum: '<Root>/Sum2x3' */
/* Concatenate: '<Root>/MatrixConcat ' */
for (i = 0; i < 3; i++) {
/* Outport: '<Root>/Out3' incorporates:
* Inport: '<Root>/In5'
*/
rtY.Out3[i << 2] = rtY.Out1[i << 1];
rtY.Out3[2 + (i << 2)] = rtU.In5[i << 1];
rtY.Out3[1 + (i << 2)] = rtY.Out1[(i << 1) + 1];
rtY.Out3[3 + (i << 2)] = rtU.In5[(i << 1) + 1];
}
/* End of Concatenate: '<Root>/MatrixConcat ' */
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 = -0.0;
for (i = 0; i < 6; i++) {
/* Sum: '<Root>/Subtract' incorporates:
* Inport: '<Root>/In3'
*/
rtY.Out1[i] -= rtU.In3;
/* Sum: '<Root>/SumOfElements' */
rtY.Out2 += rtY.Out1[i];
/* Outport: '<Root>/Out1' incorporates:
* Inport: '<Root>/In4'
* Product: '<Root>/Product'
*/
rtY.Out1[i] *= rtU.In4[i];
}
}バッファーの再利用を実装するために、コード ジェネレーターはユーザー指定のブロックの優先順位に違反しません。
推奨設定
| アプリケーション | 設定 |
|---|---|
| デバッグ | 影響なし |
| トレーサビリティ | 影響なし |
| 効率性 | 改善されたコードの実行速度 |
| 安全対策 | 推奨なし |
プログラムでの使用
パラメーター: OptimizeBlockOrder |
| 型: 文字ベクトル |
値: 'speed' | 'off'
|
既定: 'speed' |
バージョン履歴
R2017a で導入