二変量テンソル積スプライン
この例では、Curve Fitting Toolbox™ のスプライン コマンド群を使用して、二変量グリッド データへテンソル積スプラインを近似する方法を示します。
はじめに
Curve Fitting Toolbox は "ベクトル" 係数と共にスプラインを処理できるため、テンソル積スプラインによるグリッド データへの内挿または近似の実装は容易です。ツールボックスのほとんどのスプライン作成コマンドでこれを利用しています。
ただし、二変量データに対してテンソル積によるグリッド データの近似の実際の仕組みについて、その詳しい説明が必要な場合があります。これは、ツールボックスのコマンドで提供されないテンソル積の作成が必要な場合にも役立ちます。
例: グリッド データへの最小二乗近似
たとえば、次のデータが与えられた場合、そのデータへの最小二乗近似を考えてみます。
z(i,j) = f(x(i),y(j)) for i = 1:I, j = 1:J.
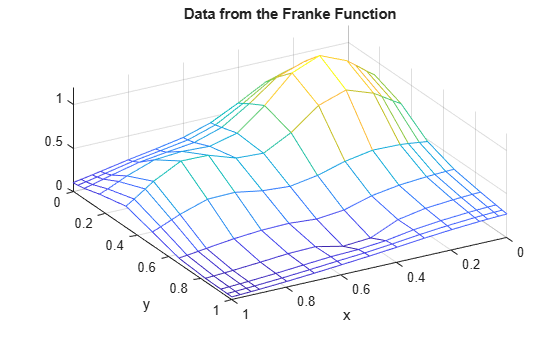
次に、フランケのサンプル関数から得られる、あるグリッド データを示します。近似を求めやすくするため、境界付近ではグリッドが密になっていることに注意してください。
x = sort([(0:10)/10,.03 .07, .93 .97]); y = sort([(0:6)/6,.03 .07, .93 .97]); [xx,yy] = ndgrid(x,y); % note: ndgrid rather than meshgrid z = franke(xx,yy); mesh(x,y,z.'); xlabel('x'); ylabel('y'); view(150,50); title('Data from the Franke Function');
NDGRID と MESHGRID に関する注意
上で使用されている次のステートメント
[xx,yy] = ndgrid(x,y);
z = franke(xx,yy);
により、z(i,j) はグリッド点 (x(i),y(j)) において、必ず近似対象の関数の値となります。
ただし、MATLAB® コマンド mesh(x,y,z) は、グリッド点 (x(i),y(j)) の値として z(j,i) (i と j の順序が逆であることに注意) を必要とします。そのため、上記のプロットは次のステートメントで生成されました。
mesh(x,y,z.');
つまり、行列 z の転置を使用しています。
ndgrid ではなく meshgrid を使用していた場合、このような転置は不要となりましたが、結果の z が近似理論標準に従っていなかったはずです。
Y 方向のスプライン空間の選択
次に、Y 方向のスプライン次数 ky およびノット シーケンス knotsy を選択し、
ky = 3; knotsy = augknt([0,.25,.5,.75,1],ky);
次の式
sp = spap2(knotsy,ky,y,z);
でその i 番目の成分が i=1:I の曲線 (y,z(i,:)) への近似であるスプライン曲線を求めます。
評価
特に、
yy = -.1:.05:1.1; vals = fnval(sp,yy);
は、行列 vals を作成します。この行列の (i,j) 番目の要素は、グリッド点 (x(i),yy(j)) における基礎関数 f の値 f(x(i),yy(j)) への近似と見なすことができます。これは、vals をプロットする場合に明らかです。
mesh(x,yy,vals.'); xlabel('x'); ylabel('y'); view(150,50); title('Simultaneous Approximation to All Curves in the Y-Direction');
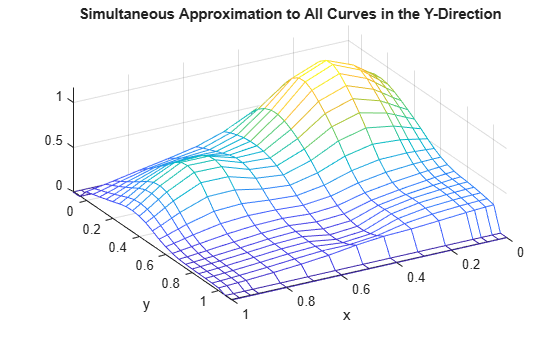
各 x(i) について、最初の 2 つの値と最後の 2 つの値は 0 である点に注意してください。これは、yy の最初の 2 つのサイトと最後の 2 つのサイトがどちらも、sp 型スプラインの基本区間外であるためです。
また、y 方向に走る "リッジ" にも注意してください。これは曲面のピーク付近で最も顕著になります。これで、滑らかな曲線が一方向のみでプロットされていることが確認できます。
曲線から曲面へ: X 方向のスプライン空間の選択
実際の曲面を得るには、さらに 1 ステップを実行する必要があります。次の式で得られる、スプライン sp の係数 coefsy について検討します。
coefsy = fnbrk(sp,'c');抽象的に、スプライン sp はベクトル値の関数として考えることができます。
y |--> sum coefsy(:,r) B_{r,ky}(y)
r
ベクトル係数 coefsy(:,r) の i 番目の要素 coefsy(i,r) は i=1:I の x(i) に対応します。これは、r ごとに同じ次数 kx および同じ適切なノット シーケンス knotsx を使用したスプラインによる各曲線 (x,coefsy(:,r)) の近似を示しています。
kx = 4; knotsx = augknt(0:.2:1,kx); sp2 = spap2(knotsx,kx,x,coefsy.');
おそらく、ここで spap2 コマンドを使用していることには説明が必要でしょう。
spap2(knots,k,x,fx) は fx(:,j) を x(j) における値として扱う、つまり fx の各 "列" をデータ値として受け取ることを思い出してください。すべての i についての x(i) における値 coefsy(i,:) の近似が必要だったため、spap2 に coefsy の "転置" を供給しなければなりません。
ここでは、次のように得られた結果のスプライン "曲線" sp2 の係数行列の "転置" について検討します。
coefs = fnbrk(sp2,'c').';coefs は、次の "二変量" スプライン近似を提供します。
(x,y) |--> sum sum coefs(q,r) B_{q,kx}(x) B_{r,ky}(y)
q r
元のデータは、以下のとおりです。
(x(i),y(j)) |--> f(x(i),y(j)) = z(i,j).
spcol を使用して、グリッド点 (xv(i),yv(j)) におけるこのスプライン曲面の評価に必要な値 B_{q,kx}(xv(i)) と B_{r,ky}(yv(j)) を指定してから、その値をプロットします。
xv = 0:.025:1; yv = 0:.025:1; values = spcol(knotsx,kx,xv)*coefs*spcol(knotsy,ky,yv).'; mesh(xv,yv,values.'); xlabel('x'); ylabel('y'); view(150,50); title('The Spline Approximant');
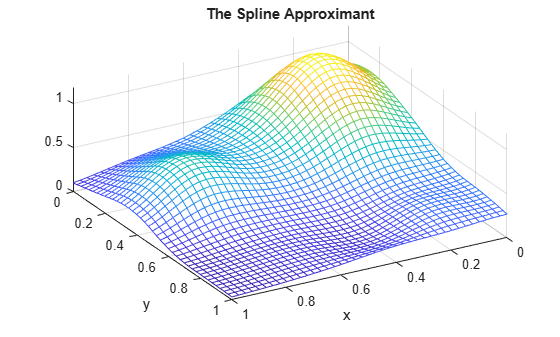
この評価作業が機能する理由
ステートメント
values = spcol(knotsx,kx,xv) * coefs * spcol(knotsy,ky,yv).'
を上記で使用することが有意義です。なぜなら、たとえば spcol(knotsx,kx,xv) が行列であり、この行列の (i,q) 番目のエントリが、ノット シーケンス knotsx では、次数 kx の q 番目の B スプラインの xv(i) における値 B_{q,kx}(xv(i)) に等しいためです。一方、次の式
sum sum coefs(q,r) B_{q,kx}(x) B_{r,ky}(y)
q r
= sum sum B_{q,kx}(x) coefs(q,r) B_{r,ky}(y)
q r
を (x,y) = (xv(i),yv(j)) において評価する必要があります。
より効率的な代替方法
行列 spcol(knotsx,kx,xv) と spcol(knotsy,ky,yv) は帯状のため、"大きな" xv と yv の場合に (おそらくメモリ消費量が増加しますが) fnval を使用すると効率が向上する場合があります。
value2 = fnval(spmak(knotsx,fnval(spmak(knotsy,coefs),yv).'),xv).';
実際、fnval と spmak は多変量スプラインを直接扱うことができるため、上記のステートメントは次のように置き換えることができます。
value3 = fnval( spmak({knotsx,knotsy},coefs), {xv,yv} );さらに好都合なことに、spap2 を "1 回" 呼び出して近似を作成できるため、次のステートメントにより任意のデータからこれらの値を直接取得できます。
value4 = fnval( spap2({knotsx,knotsy},[kx ky],{x,y},z), {xv,yv} );確認
次に確認を行います。特に、ここまでの異なる 4 通りの方法で計算した値の "相対" 差を確認します。
diffs = abs(values-value2) + abs(values-value3) + abs(values-value4); max(max(diffs)) / max(max(abs(values)))
ans = 1.1206e-15
4 つの方法は同じ値 (丸め誤差を除く) を返します。
近似の誤差
次に、誤差のプロット、つまり指定されたデータ値とそれらのデータ サイトにおけるスプライン近似値との差を示します。
errors = z - spcol(knotsx,kx,x)*coefs*spcol(knotsy,ky,y).'; mesh(x,y,errors.'); xlabel('x'); ylabel('y'); view(150,50); title('Error at the Given Data Sites');
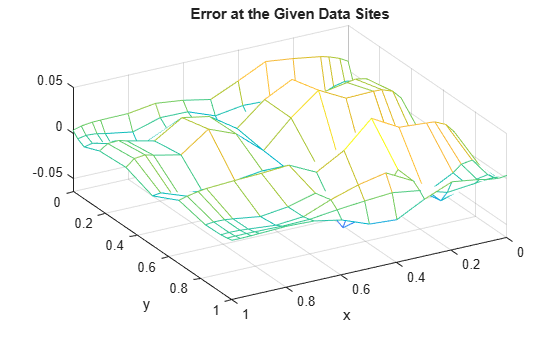
"相対" 誤差は次のとおりです。
max(max(abs(errors))) / max(max(abs(z)))
ans = 0.0539
おそらく、これはそれほど大きいわけではありません。一方で、比率
(degrees of freedom used) / (number of data points)
は次の値ほどでしかありません。
numel(coefs)/numel(z)
ans = 0.2909
このアプローチの明らかなバイアス
ここで使用したアプローチは biased のように見えます。まず、与えられたデータ値 z を y のベクトル値関数を記述しているものと考え、その後、近似曲線のベクトル係数によって形成される行列を x のベクトル値関数を記述しているものとして扱います。
逆の順序で考えた場合、つまり、z を x のベクトル値関数を記述するものと考え、その後、近似曲線のベクトル係数から構成される行列を y のベクトル値関数を記述するものとして扱うと、何が起こるでしょうか。
驚くかもしれませんが、最終近似は同じ (丸めを除く) になります。次のセクションでは、それを確認する数値実験について説明します。
反対の方法: X のスプライン空間からの開始
最初にスプライン曲線をデータに近似しますが、今回は、x を独立変数として使用するため、データ値になるのは z の "行" です。それに応じて、(z ではなく) z.' を spap2 に提供し、
spb = spap2(knotsx,kx,x,z.');
j=1:J についてのすべての曲線 (x,z(:,j)) へのスプライン近似を得なければなりません。特に、
valsb = fnval(spb,xv).';
は、行列を作成します。この行列の (i,j) 番目の要素は、グリッド点 (xv(i),y(j)) における基礎関数 f の値 f(xv(i),y(j)) への近似と見なすことができます。これは、valsb をプロットする場合に明らかです。
mesh(xv,y,valsb.'); xlabel('x'); ylabel('y'); view(150,50); title('Simultaneous Approximation to All Curves in the X-Direction');
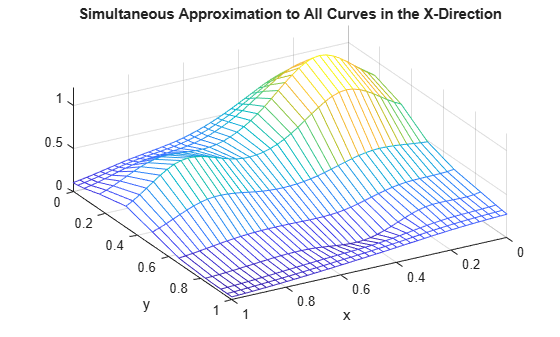
改めて、リッジに注意してください。今回は x 方向に発生しています。これで、滑らかな曲線が一方向のみでプロットされていることが再度確認できます。
曲線から曲面へ: Y 方向のスプライン空間の使用
ここで 2 番目のステップで、実際の曲面を取得します。
coefsx を spb の係数とします。つまり、次のようになります。
coefsx = fnbrk(spb,'c');抽象的に、スプライン spb はベクトル値の関数として考えることができます。
x |--> sum coefsx(r,:) B_{r,kx}(x)
r
ベクトル係数 coefsx(r,:) の j 番目のエントリ coefsx(r,j) は、すべての j について y(j) に対応します。したがって、r ごとに同じ次数 ky および同じ適切なノット シーケンス knotsy を使用したスプラインによる各曲線 (y,coefsx(r,:)) の近似が得られます。
spb2 = spap2(knotsy,ky,y,coefsx.');
spb2 の作成では、spb からの係数行列を転置する必要があります。これは、spap2 が最終入力引数の列をデータ値として使用するためです。
そのため、得られた "曲線" の係数行列 coefsb を転置する必要がなくなります。
coefsb = fnbrk(spb2,'c');主張: coefsb は前出の係数配列 coefs と等しい (丸めを除く)。これを証明するため、Curve Fitting Toolbox のドキュメンテーションでテンソル積作成の説明を確認します。ここでは、次のチェックを行うだけに留めます。
max(max(abs(coefs - coefsb)))
ans = 8.8818e-16
したがって、以下の "二変量" スプライン近似が提供されます。
(x,y) |--> sum sum coefsb(q,r) B_{q,kx}(x) B_{r,ky}(y)
q r
元のデータは、以下のとおりです。
(x(i),y(j)) |--> f(x(i),y(j)) = z(i,j)
これは coefsb ではなく coefs を生成した前のものと一致します。
先に確認したとおり、1 つが最小二乗近似の作成、もう 1 つが四角形メッシュにおけるその評価という 2 つのステートメントのみを使用して、(2 通りの方法で) 実施した作成手順全体を実行できます。
tsp = spap2({knotsx,knotsy},[kx,ky],{x,y},z);
valuet = fnval(tsp,{xv,yv});別のチェックとして、先に計算した値と今計算した値の相対差を次に示します。
max(max(abs(values-valuet))) / max(max(abs(values)))
ans = 3.7353e-16
別の例: 内挿
データは平滑化関数から来ているため、これを内挿します。つまり、spap2 ではなく spapi を使用して、言い換えると、適切なノット シーケンスで spap2 を使用します。説明のため、spapi を使用した同じ処理を次に示します。
注意するのは、(一変量) データ サイトは次のようになっていることです。
x
x = 1×15
0 0.0300 0.0700 0.1000 0.2000 0.3000 0.4000 0.5000 0.6000 0.7000 0.8000 0.9000 0.9300 0.9700 1.0000
y
y = 1×11
0 0.0300 0.0700 0.1667 0.3333 0.5000 0.6667 0.8333 0.9300 0.9700 1.0000
y で 2 次スプラインを再度使用するため、データ サイトの中間のノットを使用します。
knotsy = augknt( [0 1 (y(2:(end-2))+y(3:(end-1)))/2 ], ky);
spi = spapi(knotsy,y,z);
coefsy = fnbrk(spi,'c');得られる係数の内挿
x で 3 次スプラインを再度使用し、ノットなし条件を使用します。そのため、2 番目および最後から 2 番目のデータ点以外のすべてをノットとして使用します。
knotsx = augknt(x([1,3:(end-2),end]), kx);
spi2 = spapi(knotsx,x,coefsy.');
icoefs = fnbrk(spi2,'c').';評価
内挿を評価します。
ivalues = spcol(knotsx,kx,xv)*icoefs*spcol(knotsy,ky,yv).';
さらに、細かいメッシュで内挿をプロットします。
mesh(xv,yv,ivalues.'); xlabel('x'); ylabel('y'); view(150,50); title('The Spline Interpolant');
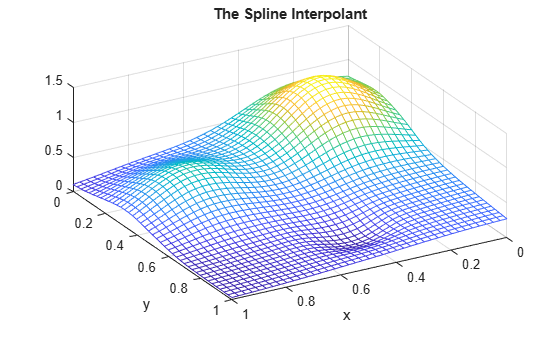
ここでも、1 つが内挿の作成、もう 1 つが四角形メッシュにおけるその評価という 2 つのステートメントのみを使用して、上記の手順を実行できます。
tsp = spapi({knotsx,knotsy},{x,y},z);
valuet = fnval(tsp,{xv,yv});チェックのため、先に計算した値と今計算した値の相対差も計算します。
max(max(abs(ivalues-valuet))) / max(max(abs(ivalues)))
ans = 5.5068e-16
近似の誤差
次に、フランケ関数の近似として内挿の誤差を計算します。
fvalues = franke(repmat(xv.',1,length(yv)),repmat(yv,length(xv),1)); error = fvalues - ivalues; mesh(xv,yv,error.'); xlabel('x'); ylabel('y'); view(150,50); title('Interpolation error');
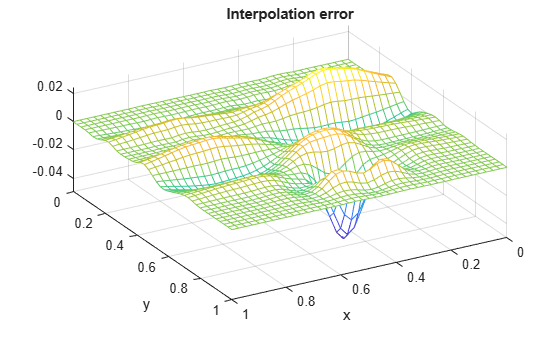
"相対" 近似誤差は次のとおりです。
max(max(abs(error))) / max(max(abs(fvalues)))
ans = 0.0409