MATLAB の map 関数および reduce 関数を Hadoop ジョブに組み込むワークフロー
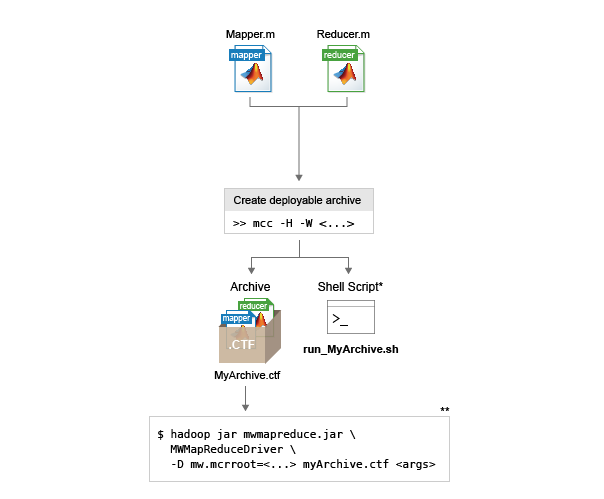

MATLAB® でマッパーおよびリデューサー関数を作成します。
MAT ファイルを作成し、解析するデータの構造と変数の名前を記すデータ ストアを含めます。MAT ファイル内のデータ ストアは、実際のデータセットを表すテスト データセットから作成できます。
マッパーやリデューサーの名前、解析するデータの型などの Hadoop® 設定を含んだテキスト ファイルを作成します。
mccコマンドを使用して、コンポーネントをデプロイ可能なアーカイブにパッケージ化します。これにより、デプロイ可能なアーカイブ (.ctf ファイル) が生成され、これは Hadoop mapreduce ジョブに組み込むことができます。hadoopのコマンドおよび構文を使用して、デプロイ可能なアーカイブを Hadoop mapreduce ジョブに組み込みます。実行シグネチャ

キー
文字 説明 A Hadoop コマンド B JAR オプション C JAR ファイルの標準名。すべてのアプリケーションで同じ JAR、 mwmapreduce.jarを使用します。この JAR へのパスも、MATLAB Runtime の場所と相対的に固定されています。D ドライバーの標準名。すべてのアプリケーションで同じドライバー名 MWMapReduceDriverを使用します。E MATLAB Runtime の場所をキーと値のペアとして指定するジェネリック オプション。 F mccによって生成されたデプロイ可能なアーカイブ (.ctfファイル) が、ペイロード引数としてジョブに渡されます。G 入力ファイルの HDFS™ での場所。 H 出力ファイルを書き込むことができる HDFS 上の場所。
デプロイ可能なアーカイブ (.ctf ファイル) の Hadoop mapreduce ジョブへの組み入れを簡略化するために、mcc コマンドにより、デプロイ可能なアーカイブと共にシェル スクリプトが生成されます。シェル スクリプトには、run_<deployableArchiveName>.sh という命名規則があります。
シェル スクリプトを使用してデプロイ可能なアーカイブを実行するには、次の構文を使用します。
