Acoustic Echo Cancellation (AEC)
This example shows how to apply adaptive filters to acoustic echo cancellation (AEC).
Introduction
Acoustic echo cancellation is important for audio teleconferencing when simultaneous communication (or full-duplex transmission) of speech is necessary. In acoustic echo cancellation, a measured microphone signal contains two signals:
The near-end speech signal
The far-end echoed speech signal
The goal is to remove the far-end echoed speech signal from the microphone signal so that only the near-end speech signal is transmitted. This example has some sound clips, so you might want to adjust your computer's volume now.
The Room Impulse Response
You first need to model the acoustics of the loudspeaker-to-microphone signal path where the speakerphone is located. Use acousticRoomResponse to create a synthesized impulse response that models a conference room. Assume a 5-by-7-by-3 meter room, a speaker positioned in that room at the 2-by-2-by-2 meter position, and the microphone at the 3-by-5-by-2 position, and a system sample rate of 16000 Hz.
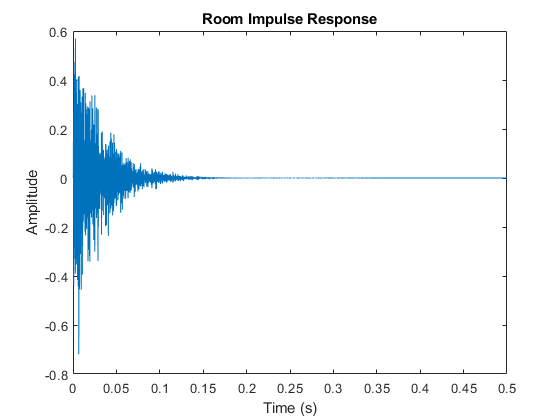
fs = 16000; M = fs/2 + 1; frameSize = 4096; roomImpulseResponse = acousticRoomResponse([5 7 3],[2 2 2],[3 5 2], ... SampleRate=fs,ImageSourceOrder=12,MaxNumRayReflections=24); room = dsp.FIRFilter(Numerator=roomImpulseResponse); fig = figure; t = (0:length(roomImpulseResponse)-1)/fs; plot(t,roomImpulseResponse); grid("on") xlabel("Time (s)"); ylabel("Amplitude"); title("Room Impulse Response");
fig.Color = [1 1 1];
The Near-End Speech Signal
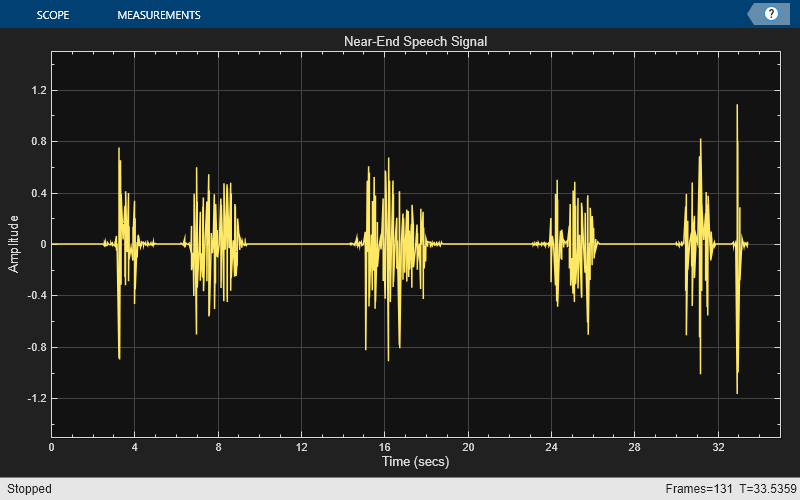
The teleconferencing system's user is typically located near the system's microphone. Here is what a male voice sounds like at the microphone.
load nearspeech player = audiostreamer(SampleRate=fs); nearSpeechSrc = dsp.SignalSource(Signal=v,SamplesPerFrame=frameSize); nearSpeechScope = timescope(... SampleRate=fs,TimeSpanSource="Property", ... TimeSpan=35,TimeSpanOverrunAction="Scroll", ... YLimits=[-1.5 1.5],BufferLength=length(v), ... Title="Near-End Speech Signal"); % Stream processing loop while(~isDone(nearSpeechSrc)) % Extract the speech samples from the input signal nearSpeech = nearSpeechSrc(); % Plot the signal nearSpeechScope(nearSpeech); % Send the speech samples to the output audio device play(player,nearSpeech); end release(nearSpeechScope);
The Far-End Speech Signal
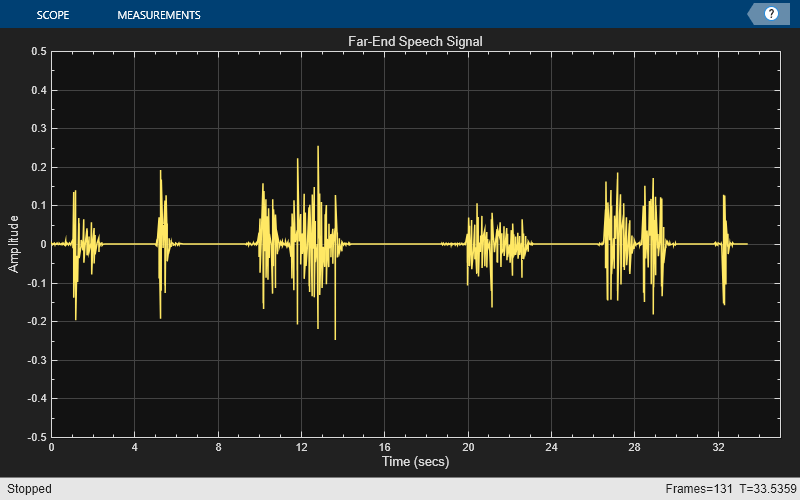
In a teleconferencing system, a voice travels out from the loudspeaker, bounces around in the room, and then is picked up by the system's microphone. Listen to what the speech sounds like if it is picked up at the microphone without the near-end speech present.
load farspeech farSpeechSrc = dsp.SignalSource(Signal=x,SamplesPerFrame=frameSize); farSpeechSink = dsp.SignalSink; farSpeechScope = timescope(... SampleRate=fs,TimeSpanSource="Property", ... TimeSpan=35,TimeSpanOverrunAction="Scroll", ... YLimits=[-0.5 0.5],BufferLength=length(x), ... Title="Far-End Speech Signal"); % Stream processing loop while(~isDone(farSpeechSrc)) % Extract the speech samples from the input signal farSpeech = farSpeechSrc(); % Add the room effect to the far-end speech signal farSpeechEcho = room(farSpeech); % Plot the signal farSpeechScope(farSpeech); % Log the signal for further processing farSpeechSink(farSpeechEcho); % Send the speech samples to the output audio device play(player,farSpeechEcho); end release(farSpeechScope);
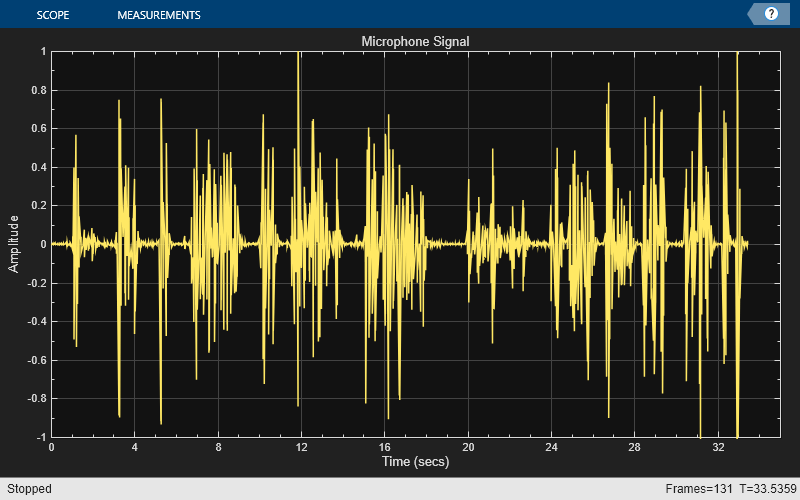
The Microphone Signal
The signal at the microphone contains both the near-end speech and the far-end speech that has been echoed throughout the room. The goal of the acoustic echo canceler is to cancel out the far-end speech, such that only the near-end speech is transmitted back to the far-end listener.
reset(nearSpeechSrc); farSpeechEchoSrc = dsp.SignalSource(... Signal=farSpeechSink.Buffer, ... SamplesPerFrame=frameSize); micSink = dsp.SignalSink; micScope = timescope(... SampleRate=fs,TimeSpanSource="Property", ... TimeSpan=35,TimeSpanOverrunAction="Scroll", ... YLimits=[-1 1],BufferLength=length(v), ... Title="Microphone Signal"); % Stream processing loop while(~isDone(farSpeechEchoSrc)) % Microphone signal = echoed far-end + near-end + noise micSignal = farSpeechEchoSrc() + nearSpeechSrc() + ... 0.001*randn(frameSize,1); % Plot the signal micScope(micSignal); % Log the signal micSink(micSignal); % Send the speech samples to the output audio device play(player,micSignal); end release(micScope);
The Frequency-Domain Adaptive Filter (FDAF)
The algorithm in this example is the Frequency-Domain Adaptive Filter (FDAF). This algorithm is very useful when the impulse response of the system to be identified is long. The FDAF uses a fast convolution technique to compute the output signal and filter updates. This computation executes quickly in MATLAB®. It also has fast convergence performance through frequency-bin step size normalization. Choose some initial parameters for the filter and see how well the far-end speech is canceled in the error signal.
% Construct the Frequency-Domain Adaptive Filter echoCanceller = dsp.FrequencyDomainAdaptiveFilter(... Length=frameSize,StepSize=0.025,InitialPower=0.01, ... AveragingFactor=0.985,Method="Unconstrained FDAF"); AECScope = timescope(4,fs, ... LayoutDimensions=[4,1],TimeSpanSource="Property", ... TimeSpan=35,TimeSpanOverrunAction="Scroll", ... BufferLength=length(x)); AECScope.ActiveDisplay = 1; AECScope.YLimits = [-1.5 1.5]; AECScope.Title = "Near-End Speech Signal"; AECScope.ActiveDisplay = 2; AECScope.YLimits = [-1.5 1.5]; AECScope.Title = "Microphone Signal"; AECScope.ActiveDisplay = 3; AECScope.YLimits = [-1.5 1.5]; AECScope.Title = "Output of Acoustic Echo Canceller mu=0.025"; AECScope.ActiveDisplay = 4; AECScope.YLimits = [0 50]; AECScope.YLabel = "ERLE (dB)"; AECScope.Title = "Echo Return Loss Enhancement mu=0.025"; % Near-end speech signal release(nearSpeechSrc); nearSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal release(farSpeechSrc); farSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal echoed by the room release(farSpeechEchoSrc); farSpeechEchoSrc.SamplesPerFrame = frameSize;
Echo Return Loss Enhancement (ERLE)
Since you have access to both the near-end and far-end speech signals, you can compute the echo return loss enhancement (ERLE), which is a smoothed measure of the amount (in dB) that the echo has been attenuated. From the plot, observe that you achieved about a 35 dB ERLE at the end of the convergence period.
diffAverager = dsp.FIRFilter(Numerator=ones(1,1024)); farEchoAverager = clone(diffAverager); filterAnalyzer(diffAverager)
micSrc = dsp.SignalSource(... Signal=micSink.Buffer, ... SamplesPerFrame=frameSize); % Stream processing loop - adaptive filter step size = 0.025 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope(nearSpeech, micSignal, e, erledB); % Send the speech samples to the output audio device play(player,e); end release(AECScope);

Effects of Different Step Size Values
To get faster convergence, you can try using a larger step size value. However, this increase causes another effect: the adaptive filter is "maladjusted" while the near-end speaker is talking. Listen to what happens when you increase the step size by 60%.
% Change the step size value in FDAF reset(echoCanceller); echoCanceller.StepSize = 0.04; AECScope.ActiveDisplay = 3; AECScope.Title = "Output of Acoustic Echo Canceller mu=0.04"; AECScope.ActiveDisplay = 4; AECScope.Title = "Echo Return Loss Enhancement mu=0.04"; reset(nearSpeechSrc); reset(farSpeechSrc); reset(farSpeechEchoSrc); reset(micSrc); reset(diffAverager); reset(farEchoAverager); % Stream processing loop - adaptive filter step size = 0.04 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope(nearSpeech, micSignal, e, erledB); % Send the speech samples to the output audio device play(player,e); end release(nearSpeechSrc); release(farSpeechSrc); release(farSpeechEchoSrc); release(micSrc); release(diffAverager); release(farEchoAverager); release(echoCanceller); release(AECScope);
Echo Return Loss Enhancement Comparison
With a larger step size, the ERLE performance is not as good due to the maladjustment introduced by the near-end speech. To deal with this performance difficulty, acoustic echo cancelers include a detection scheme to tell when near-end speech is present and lowers the step size value over these periods. Without such detection schemes, the performance of the system with the larger step size is not as good as the former, as can be seen from the ERLE plots.
Latency Reduction Using Partitioning
Traditional FDAF is numerically more efficient than time-domain adaptive filtering for long impulse responses, but it imposes high latency, because the input frame size must be a multiple of the specified filter length. This can be unacceptable for many real-world applications. Latency may be reduced by using partitioned FDAF, which partitions the filter impulse response into shorter segments, applies FDAF to each segment, and then combines the intermediate results. The frame size in that case must be a multiple of the partition (block) length, thereby greatly reducing the latency for long impulse responses.
% Reduce the frame size from 2048 to 256 frameSize = 256; nearSpeechSrc.SamplesPerFrame = frameSize; farSpeechSrc.SamplesPerFrame = frameSize; farSpeechEchoSrc.SamplesPerFrame = frameSize; micSrc.SamplesPerFrame = frameSize; % Switch the echo canceller to Partitioned constrained FDAF echoCanceller.Method = "Partitioned constrained FDAF"; % Set the block length to frameSize echoCanceller.BlockLength = frameSize; % Stream processing loop while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope(nearSpeech, micSignal, e, erledB); % Send the speech samples to the output audio device play(player,e); end release(nearSpeechSrc); release(farSpeechSrc); release(farSpeechEchoSrc); release(micSrc); release(diffAverager); release(farEchoAverager); release(echoCanceller); release(AECScope);

release(player);