このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
tsne の設定
この例では、さまざまな tsne の設定の影響を示します。
データの読み込みと確認
この例を実行すると提供される humanactivity データを読み込みます。
load humanactivityデータの説明を表示します。
Description
Description = 29×1 string
" === Human Activity Data === "
" "
" The humanactivity data set contains 24,075 observations of five different "
" physical human activities: Sitting, Standing, Walking, Running, and "
" Dancing. Each observation has 60 features extracted from acceleration "
" data measured by smartphone accelerometer sensors. The data set contains "
" the following variables: "
" "
" * actid - Response vector containing the activity IDs in integers: 1, 2, "
" 3, 4, and 5 representing Sitting, Standing, Walking, Running, and "
" Dancing, respectively "
" * actnames - Activity names corresponding to the integer activity IDs "
" * feat - Feature matrix of 60 features for 24,075 observations "
" * featlabels - Labels of the 60 features "
" "
" The Sensor HAR (human activity recognition) App [1] was used to create "
" the humanactivity data set. When measuring the raw acceleration data with "
" this app, a person placed a smartphone in a pocket so that the smartphone "
" was upside down and the screen faced toward the person. The software then "
" calibrated the measured raw data accordingly and extracted the 60 "
" features from the calibrated data. For details about the calibration and "
" feature extraction, see [2] and [3], respectively. "
" "
" [1] El Helou, A. Sensor HAR recognition App. MathWorks File Exchange "
" http://www.mathworks.com/matlabcentral/fileexchange/54138-sensor-har-recognition-app "
" [2] STMicroelectronics, AN4508 Application note. “Parameters and "
" calibration of a low-g 3-axis accelerometer.” 2014. "
" [3] El Helou, A. Sensor Data Analytics. MathWorks File Exchange "
" https://www.mathworks.com/matlabcentral/fileexchange/54139-sensor-data-analytics--french-webinar-code- "
データ セットは動作タイプごとに整理されています。データの無作為なセットをより適切に表現するために、行をシャッフルします。
n = numel(actid); % Number of data points rng default % For reproducibility idx = randsample(n,n); % Shuffle X = feat(idx,:); % Shuffled data actid = actid(idx); % Shuffled labels
動作を actid 内のラベルに関連付けます。
activities = ["Sitting";"Standing";"Walking";"Running";"Dancing"]; activity = activities(actid);
t-SNE の使用によるデータの処理
t-SNE を使用して、データ クラスターの 2 次元類似物を取得します。
rng default % For reproducibility Y = tsne(X); figure numGroups = length(unique(actid)); clr = hsv(numGroups); gscatter(Y(:,1),Y(:,2),activity,clr) title('Default Figure')
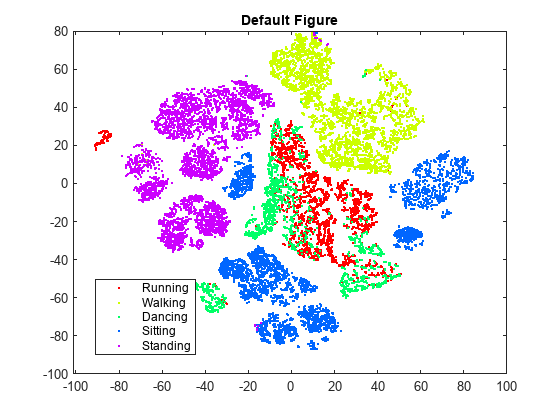
t-SNE は、位置が正しくないと思われるデータ点の個数が比較的少ない図を作成します。ただし、クラスターが十分に分離されているとは言えません。
パープレキシティ
パープレキシティの設定を変更して、図に対する影響を調べます。
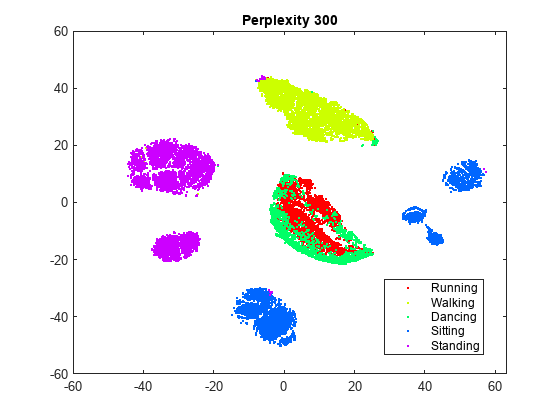
rng default % For fair comparison Y300 = tsne(X,Perplexity=300); figure gscatter(Y300(:,1),Y300(:,2),activity,clr) title('Perplexity 300')
rng default % For fair comparison Y4 = tsne(X,Perplexity=4); figure gscatter(Y4(:,1),Y4(:,2),activity,clr) title('Perplexity 4')
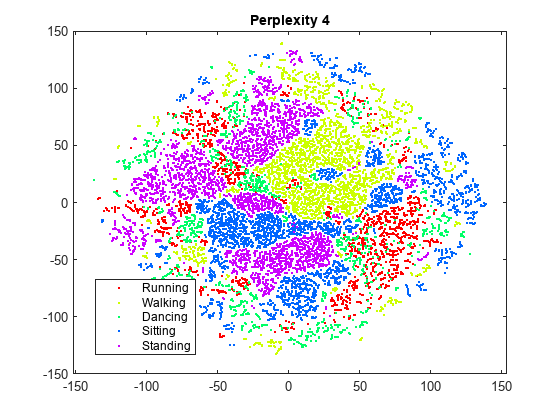
パープレキシティを 300 に設定すると、クラスターが元の図よりも適切に分離されている図が生成されます。パープレキシティを 4 に設定すると、クラスターが十分には分離されない図が生成されます。この例の残りの部分では、パープレキシティを 300 にします。
強調
強調の設定を変更して、図に対する影響を調べます。
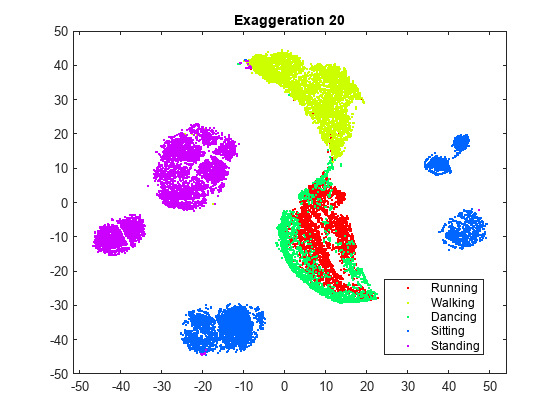
rng default % For fair comparison YEX20 = tsne(X,Perplexity=300,Exaggeration=20); figure gscatter(YEX20(:,1),YEX20(:,2),activity,clr) title('Exaggeration 20')
rng default % For fair comparison YEx15 = tsne(X,Perplexity=300,Exaggeration=1.5); figure gscatter(YEx15(:,1),YEx15(:,2),activity,clr) title('Exaggeration 1.5')
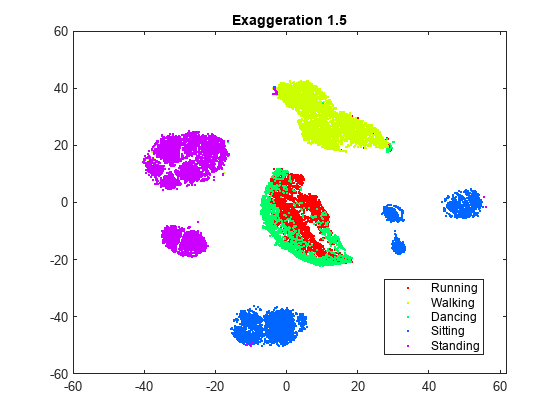
強調の設定は図に影響を与えますが、既定ではない設定にすると既定の設定より良好な図が得られるかどうかは明らかではありません。強調が 20 の図は既定の図と似ていますが、既定の図ほどはクラスターが十分には分離されていません。一般に、強調が大きくなると、埋め込まれるクラスターの間に作成される空白の空間が多くなります。強調が 1.5 になると、既定の強調と似た図になります。X の同時分布の値を強調すると、Y の同時分布の値が小さくなります。これにより、埋め込まれる点が互いに対してはるかに移動しやすくなります。
学習率
学習率の設定を変更して、図に対する影響を調べます。
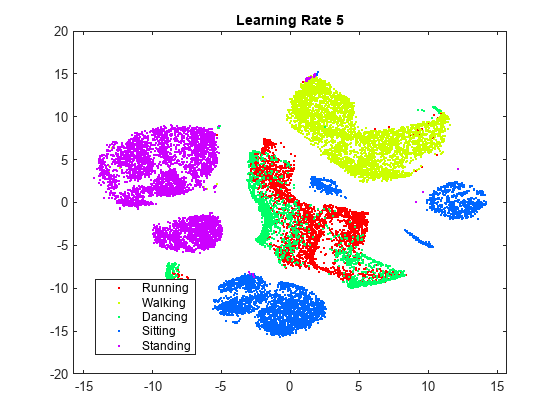
rng default % For fair comparison YL5 = tsne(X,Perplexity=300,LearnRate=5); figure gscatter(YL5(:,1),YL5(:,2),activity,clr) title('Learning Rate 5')
rng default % For fair comparison YL2000 = tsne(X,Perplexity=300,LearnRate=2000); figure gscatter(YL2000(:,1),YL2000(:,2),activity,clr) title('Learning Rate 2000')
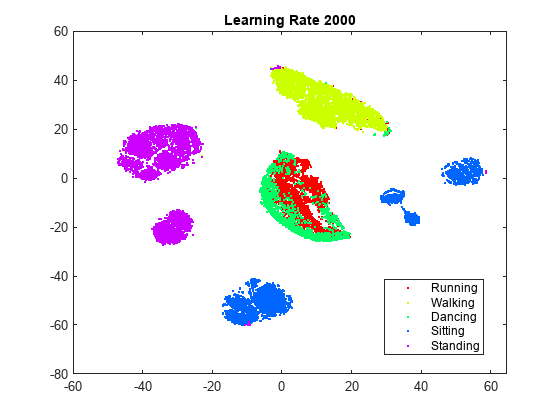
学習率が 5 の図では、いくつかのクラスターが 2 つ以上に分割されています。これは、学習率が小さすぎると、不適切なローカル最小値で最小化処理が止まる可能性があることを示しています。学習率が 2000 になると、学習率が設定されていない図と似た図になります。
さまざまな設定での初期動作
学習率または強調値が大きいと、望ましくない初期動作になる可能性があります。これを調べるため、これらのパラメーターに大きい値を設定し、すべての反復を表示するため NumPrint と Verbose を 1 に設定します。この実験の目標は初期動作を調べることだけなので、10 回の反復後に停止します。
はじめに、強調を 200 に設定します。
rng default % For fair comparison opts = statset(MaxIter=10); YEX5000 = tsne(X,Perplexity=300,Exaggeration=5000,... NumPrint=1,Verbose=1,Options=opts);
|==============================================| | ITER | KL DIVERGENCE | NORM GRAD USING | | | FUN VALUE USING | EXAGGERATED DIST| | | EXAGGERATED DIST| OF X | | | OF X | | |==============================================| | 1 | 6.388137e+04 | 6.483115e-04 | | 2 | 6.388775e+04 | 5.267770e-01 | | 3 | 7.131506e+04 | 5.754291e-02 | | 4 | 7.234772e+04 | 6.705418e-02 | | 5 | 7.409144e+04 | 9.278330e-02 | | 6 | 7.484659e+04 | 1.022587e-01 | | 7 | 7.445701e+04 | 9.934864e-02 | | 8 | 7.391345e+04 | 9.633570e-02 | | 9 | 7.315999e+04 | 1.027610e-01 | | 10 | 7.265936e+04 | 1.033174e-01 |
最初の数回の反復ではカルバック・ライブラー ダイバージェンスが増加しており、勾配のノルムも増加しています。
埋め込みの最終結果を調べるため、既定の停止条件を使用して、完了までアルゴリズムを実行できるようにします。
rng default % For fair comparison YEX5000 = tsne(X,Perplexity=300,Exaggeration=5000); figure gscatter(YEX5000(:,1),YEX5000(:,2),activity,clr) title('Exaggeration 5000')
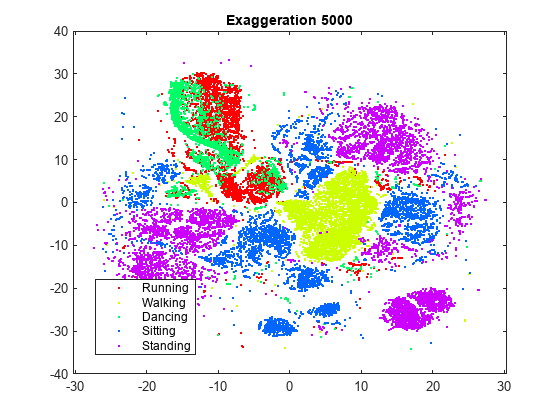
この強調値では、明確にはクラスターに分離されません。
学習率が 1,000,000 の場合の初期動作を表示します。
rng default % For fair comparison YL1000k = tsne(X,Perplexity=300,LearnRate=1e6,... NumPrint=1,Verbose=1,Options=opts);
|==============================================| | ITER | KL DIVERGENCE | NORM GRAD USING | | | FUN VALUE USING | EXAGGERATED DIST| | | EXAGGERATED DIST| OF X | | | OF X | | |==============================================| | 1 | 2.258150e+01 | 4.412730e-07 | | 2 | 2.259045e+01 | 4.857725e-04 | | 3 | 2.945552e+01 | 3.210405e-05 | | 4 | 2.976546e+01 | 4.337510e-05 | | 5 | 2.976928e+01 | 4.626810e-05 | | 6 | 2.969205e+01 | 3.907617e-05 | | 7 | 2.963695e+01 | 4.943976e-05 | | 8 | 2.960336e+01 | 4.572338e-05 | | 9 | 2.956194e+01 | 6.208571e-05 | | 10 | 2.952132e+01 | 5.253798e-05 |
この場合も、最初の数回の反復ではカルバック・ライブラー ダイバージェンスが増加しており、勾配のノルムも増加しています。
埋め込みの最終結果を調べるため、既定の停止条件を使用して、完了までアルゴリズムを実行できるようにします。
rng default % For fair comparison YL1000k = tsne(X,Perplexity=300,LearnRate=1e6); figure gscatter(YL1000k(:,1),YL1000k(:,2),activity,clr) title('Learning Rate 1,000,000')
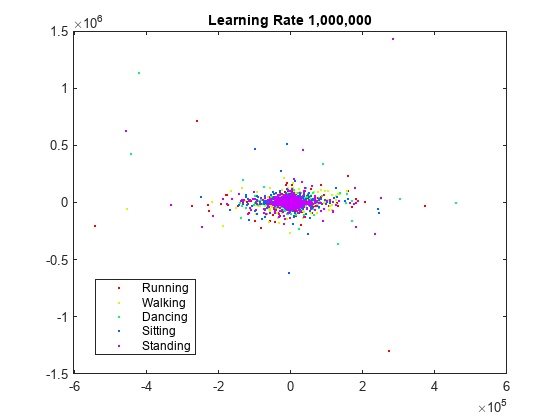
学習率が大きすぎるので、有用な埋め込みは得られません。
まとめ
既定設定の tsne は、クラスターが明確に定義された 2 次元の点に高次元の初期データを埋め込む処理を適切に行います。パープレキシティの値を大きくすると、このデータの埋め込みが見やすくなります。アルゴリズムの設定の影響を予測することは困難です。クラスタリングが改善されることもありますが、通常は既定設定が適切なようです。この調査に速度は含まれていませんが、設定がアルゴリズムの速度に影響を与える可能性があります。特にこのデータでは、既定の Barnes-Hut アルゴリズムは著しく高速になります。