クラスターおよびクラウドへの parfor ループのスケールアップ
この例では、ローカルのマルチコア デスクトップである計算の実行に必要な時間の測定を開始し、この測定を関数としてワーカー数を増やして実行します。このテストを "ストロング スケーリング" テストと呼びます。このテストでは、ワーカーを追加した場合の計算所要時間の減少を測定できます。この依存関係は "高速化" と呼ばれ、そこからコードの "並列スケーラビリティ" を推定することができます。これにより、並列プールのワーカー数を増やして、クラスターおよびクラウド コンピューティングにスケール アップすることが有用かどうかを判断できます。
関数を作成します。
edit MyCodeMATLAB® エディターで新しい
parforループを入力し、経過時間を測定するticおよびtocを追加します。function a = MyCode(A) tic parfor i = 1:200 a(i) = max(abs(eig(rand(A)))); end toc end
ファイルを保存してエディターを閉じます。
[並列] 、 [並列設定] メニューで、[既定のクラスター] が [プロセス] (デスクトップ マシン) であることを確認します。
MATLAB コマンド ウィンドウでサイズ 1 の並列プールを定義し、1 つのワーカーで関数を実行して経過時間を計算します。1 つのワーカーの経過時間を記録し、並列プールをシャットダウンします。
parpool(1); a = MyCode(1000);
Elapsed time is 172.529228 seconds.
delete(gcp);
2 つのワーカーからなる新しい並列プールを開き、関数をもう一度実行します。
parpool(2); a = MyCode(1000);
経過時間を確認します。単一のワーカーの場合に比べて減少しているはずです。
4、8、12 および 16 個のワーカーで試します。両対数スケールで各ワーカー数の経過時間をプロットして、並列スケーラビリティを測定します。

この図は、一般的なマルチコア デスクトップ PC のスケーラビリティを示したものです (青い円のデータ点)。ストロング スケーリング テストでは、ワーカー 8 個までのほぼ線形的な高速化と大幅な並列スケーラビリティが示されています。この図から、この例では 8 個を超えるワーカーではさらなる高速化は実現されないことが分かります。この結果は、ローカル デスクトップ マシンのすべてのコアが 8 個のワーカーで最大限に使用されていることを意味します。ハードウェアによっては、ローカル デスクトップで異なる結果が得られることがあります。並列アプリケーションをさらに高速化するには、クラウドまたはクラスター コンピューティングへのスケール アップを検討してください。
前述の例のように、ローカルのワーカーを使い切った場合は、計算をクラウド コンピューティングにスケール アップできます。[並列] 、 [クラスターの検出] メニューでクラウド コンピューティングへのアクセスをチェックします。
クラウドで並列プールを開き、コードを変更せずにアプリケーションを実行します。
parpool(16); a = MyCode(1000);
増加するクラスター ワーカーの数に対する経過時間に注目してください。ワーカー数の関数として経過時間を両対数スケールにプロットし、並列スケーラビリティを測定します。

この図は、クラウドのワーカーの一般的なパフォーマンスを示したものです (赤いプラスのデータ点)。このストロング スケーリング テストでは、クラウドの 16 個のワーカーまで、線形的な高速化と 100% の並列スケーラビリティが示されています。クラウドまたは計算クラスター上のワーカー数を増やして、計算をさらにスケール アップすることを検討してください。ワーカーおよびその他のアプリケーションの数が多い場合、並列スケーラビリティはハードウェアによって異なる場合があります。
クラスターに直接アクセスする場合は、クラスター上のワーカーを使用して計算をスケール アップできます。[並列] 、 [クラスターの検出] メニューでクラスターへのアクセスをチェックします。アカウントがある場合は、[クラスター] を選択し、並列プールを開いて、コードを変更せずにアプリケーションを実行します。
parpool(64); a = MyCode(1000);
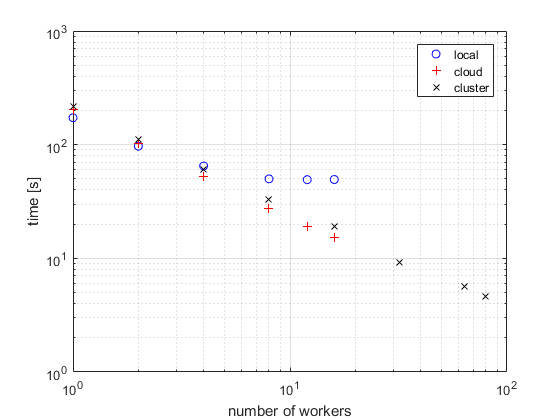
この図は、クラスター上のワーカーでの一般的なストロング スケーリングのパフォーマンスを示したものです (黒い x のデータ点)。100% の並列スケーラビリティが達成され、それが、クラスター上の少なくとも 80 個のワーカーまで継続しています。このアプリケーションは線形的にスケーリングすることに注目してください。高速化は使用されているワーカーの数に対応しています。
この例は、ワーカー数がそのまま高速化に結びつくことを示しています。すべてのタスクで同様な高速化が実現できるわけではありません。parfor を使用した対話形式でのループの並列実行の例を参照してください。
特定のタスクでは、異なる方法が必要となる場合があります。代替方法の詳細については、並列計算の解決策の選択を参照してください。
ヒント
ticBytes および tocBytes を使用して並列プール内のワーカーが送受信するデータ量を測定することにより、parfor ループをさらにプロファイリングできます。詳細と例については、parfor ループのプロファイリングを参照してください。