明示的な並列通信のプロファイル
この例では、最近傍のワーカーに対する明示的な通信をプロファイルする方法を示します。spmdSend、spmdReceive および spmdSendReceive の使用について説明し、このアルゴリズムを実装する遅い (正しくない) 方法と速い (最適の) 方法を説明します。この問題は、並列プロファイラーを使用して検討します。並列プロファイルを始めるには、並列コードのプロファイルを参照してください。
この例における図は、12 ノードのクラスターから作成されています。
例のコードには明示的な通信が使われています。MATLAB® での明示的通信とは、Parallel Computing Toolbox™ の通信プリミティブ (spmdSend、spmdReceive、spmdSendReceive、spmdBarrier など) を直接使用することと同義です。このタイプの通信に伴うパフォーマンスの問題は、基本のハードウェアに関連していない場合に調査が難しい可能性があります。並列プロファイラーを使うと、こうした問題の多くは対話的に特定できます。プログラムのさまざまな部分を別々の関数に分離できることを覚えておくことは大切です。データによっては関数ごとにしか収集できないものもあるため、これはプロファイル作成に際して役立ちます。
アルゴリズム
プロファイルの対象とするアルゴリズムは、最近傍の通信方式です。それぞれの MATLAB ワーカーは、それ自体と、隣接する 1 つのラボからのデータのみを必要とします。こうしたタイプのデータ並列パターンは多くの行列問題に適していますが、間違って扱うと、不必要に遅いものとなります。説明を加えるとすれば、各ラボは、隣接するラボで "既に" 使用可能となっているデータに依存しています。たとえば、4 つのラボからなるクラスターで、ラボ 1 はラボ 2 に何らかのデータを送信し、ラボ 4 からのデータを必要とするというように、各ラボは他の 1 つのラボのみに依存しています。
1 は 4 に依存
2 は 1 に依存
3 は 2 に依存
4 は 3 に依存
与えられた任意の通信アルゴリズムを spmdSend および spmdReceive を使用して実装することが可能です。spmdReceive は通信が完了するまで常にプログラムをブロックしますが、spmdSend はデータが小規模であればブロックしない可能性があります。しかし、spmdSend を最初に使用しても、ほとんどの場合で役立ちません。
このアルゴリズムを成り立たせるための 1 つの方法は、すべてのワーカーを受信用に待機させ、1 つのワーカーだけに送信とこれに続けて受信を 1 回ずつ実行することによりに通信チェーンを開始させることです。あるいは、spmdSendReceive を使用することもできますが、一見しただけではパフォーマンスに大きな違いのあることがわからない可能性があります。
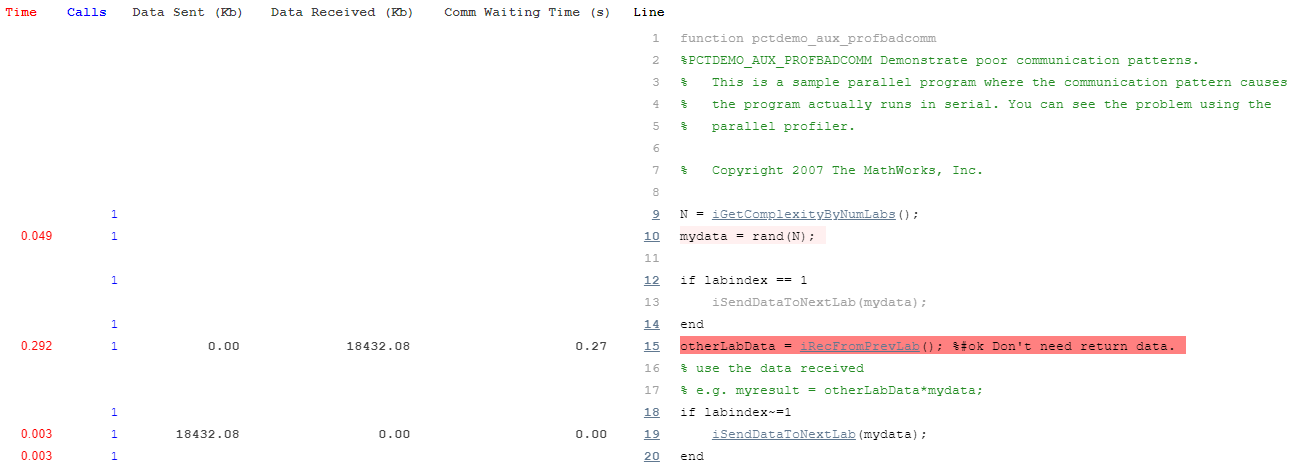
pctdemo_aux_profbadcomm および pctdemo_aux_profcomm のコードを表示して、このアルゴリズムの詳細な実装を確認できます。最初のファイルを確認し、通信に spmdSend と spmdReceive が使用されていることに注意してください。
よくある誤りとして、必要もなく spmdSend と spmdReceive の観点から考え始めることがあります。この pctdemo_aux_profbadcomm の実装がどのように機能しているかを調べると、求めるべき対象をよりよく把握できるようになります。
spmdSend 実装のプロファイル
spmd spmdBarrier; % to ensure the workers all start at the same time mpiprofile reset; mpiprofile on; pctdemo_aux_profbadcomm; end
Worker 1: sending to 2 Worker 2: receive from 1 Worker 3: receive from 2 Worker 4: receive from 3 Worker 5: receive from 4 Worker 6: receive from 5 Worker 7: receive from 6 Worker 8: receive from 7 Worker 9: receive from 8 Worker 10: receive from 9 Worker 11: receive from 10 Worker 12: receive from 11 Worker 1: receive from 12 Worker 2: sending to 3 Worker 3: sending to 4 Worker 4: sending to 5 Worker 5: sending to 6 Worker 6: sending to 7 Worker 7: sending to 8 Worker 8: sending to 9 Worker 9: sending to 10 Worker 10: sending to 11 Worker 11: sending to 12 Worker 12: sending to 1
mpiprofile viewer並列プロファイル概要レポートが表示されます。このページでは、通信での待機に費やされた時間が、[合計時間プロット] 列の下にオレンジのバーとして表示されます。下図のデータでは、かなりの時間が待機に費やされたことが示されています。並列プロファイラーが、こうした待機の原因特定にどのように役立つかを見てみましょう。
クイックスタートの手順
[並列プロファイル概要] テーブルを表示し、ツールストリップの [比較] セクションで [最長と最短合計時間] ボタンをクリックします。
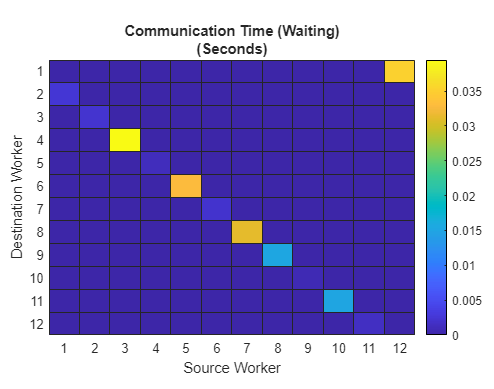
pctdemo_aux_profbadcomm>iRecFromPrevLabエントリについて、オレンジの長い待機時間が示されていることを確認します。これは、ネットワークの問題やアルゴリズムの問題のため、対応する送信において何かがおかしいことを兆候として示しています。ワーカー間通信プロットを表示するには、[並列プロファイル概要] の [プロット] セクションを展開し、ツールストリップの [プロット] セクションで [ヒートマップ] ボタンをクリックします。このビューの最初の図には、各ワーカーで受け取ったすべてのデータが表示されます。この例では、各ワーカーが先行するワーカーから同量のデータを受け取っており、問題点はデータ分散にはないように見えます。2 番目の図は、通信待機に費やされた時間を含む、さまざまな通信時間を表しています。3 番目の図でワーカーごとの通信待機時間プロットは、待ち時間の段階的増加を示しています。12 ノードのクラスターを使用したワーカーごとの通信待機時間プロットの例は、以下で確認できます。ソース ワーカーに戻り、そこで何が起こっているのかを確認することがよいでしょう。
ワーカー 1 で何が起こっているのかを確認します。最上位の関数
pctdemo_aux_profbadcommをクリックし、関数の詳細レポートに移動します。[関数リスト] セクションへと下にスクロールして、ワーカー 1 がどこで時間を費やし、どの行が対象となっているかを確認します。最後のワーカーと比較するには、ツールストリップの [比較] セクションにある [ワーカーに移動] メニューを使用して最後のワーカーを選択し、[時間のかかる行] テーブルを調べます。
コードのプロファイルされた行をすべて確認するには、ページ最後のアイテムまで下にスクロールします。この注釈の付いたコード リスティングの例は、以下に提示されています。
より大きなローカルでないクラスターを使用した通信プロット
spmdSend と spmdReceive の使用に伴う問題を明確にするために、次に示す 12 ノードのクラスターからの [通信時間 (待機)] プロットを確認します。

上のプロットでは、すべての関数についてのワーカー間通信のプロットを使用して、不要な待機を確認できます。待機時間はワーカー番号に応じて増加しています。これは、spmdReceive が、対になっている spmdSend の完了までブロックされるためです。したがって、後続のワーカーは直前の spmdIndex が出力するデータのみを必要としているにもかかわらず、通信は順次行われます。
spmdSendReceive を使用したこのアルゴリズムの実装
spmdSendReceive を使用して、データ送信と、依存されるワーカーからのデータ受信を同時に行い、待機時間を最小にすることができます。このことは、pctdemo_aux_profcomm に実装されている通信方式の修正バージョンで確認できます。明らかに、送信前にデータを受信する必要がある場合、spmdSendReceive は使用できません。そのような場合は、spmdSend と spmdReceive を使用して時系列を確実に維持します。しかし、この例のように送信前にデータを受信する必要がない場合は、spmdSendReceive を使用します。前のバージョンで収集したデータをリセットせずに、このバージョンをプロファイルします (mpiprofile resume を使用)。
spmd spmdBarrier; mpiprofile resume; pctdemo_aux_profcomm; end
Worker 1: sending to 2 receiving from 12 Worker 2: sending to 3 receiving from 1 Worker 3: sending to 4 receiving from 2 Worker 4: sending to 5 receiving from 3 Worker 5: sending to 6 receiving from 4 Worker 6: sending to 7 receiving from 5 Worker 7: sending to 8 receiving from 6 Worker 8: sending to 9 receiving from 7 Worker 9: sending to 10 receiving from 8 Worker 10: sending to 11 receiving from 9 Worker 11: sending to 12 receiving from 10 Worker 12: sending to 1 receiving from 11
mpiprofile viewerこの修正バージョンでは、待ち時間が実質的にゼロに減ります。これを確認するには、関数 pctdemo_aux_profcomm について、ワーカー間通信のプロットを表示します。spmdSendReceive を使用すると、次の通信時間 (待機) プロットが示すとおり、同じ通信方式で費やされる待機時間はほぼなくなります。
プロットの配色
それぞれの 2 次元イメージ プロットにおいて、配色はその場のタスクに合わせて正規化されます。したがって、上記プロットの配色を他のプロットとの比較には使用しないでください。色は正規化されており、最大値によって左右されるからです。この例で、pctdemo_aux_profbadcomm ではなく pctdemo_aux_profcomm を使用する場合は、待機時間の大きな差を比較するために最大値を使用することが最もよい方法です。